11 KiB
| title | description | keywords | tags | author | date | ||||
|---|---|---|---|---|---|---|---|---|---|
| 模块和包 | Python 模块和包 |
|
|
7Wate | 2023-08-03 |
在编程语言中,我们常常会看到各种不同级别的封装,如代码块、函数、类、模块,甚至包,每个级别都会进行逐级调用。在 Python 中,一个 .py 文件就被看作是一个模块。这实际上是比类级别更高的封装。在其他的编程语言中,被导入的模块通常被称为库。
模块
在 Python 中,模块可以分为自定义模块、内置模块(标准模块)和第三方模块。使用模块主要有以下几个好处:
- 提高了代码的可维护性。通过将代码拆分为多个模块,可以降低每个模块的复杂性,更容易进行理解和维护。
- 重用代码。当一个模块编写完毕,就可以被其他的模块引用。这避免了“重复造轮子”,允许开发者更加专注于新的任务。
- 避免命名冲突。同名的类、函数和变量可以分别存在于不同的模块中,防止名称冲突。但也要注意尽量避免与内置函数名(类名)冲突。
自定义模块
自定义模块是开发者根据实际需求编写的代码,封装为模块方便在多个地方使用。当创建一个新的 Python 文件时,比如 mymodule.py,我们就创建了一个名为 mymodule 的模块,可以通过 import mymodule 来导入和使用。
# mymodule.py
def hello():
print("Hello, World!")
# main.py
import mymodule
mymodule.hello() # 输出 "Hello, World!"
标准模块
Python 拥有一个强大的标准库。Python 语言的核心只包含数值、字符串、列表、字典、文件等常见类型和函数,而由 Python 标准库提供了系统管理、网络通信、文本处理、数据库接口、图形系统、XML 处理等额外的功能。如文本处理、文件系统操作、操作系统功能、网络通信、W3C 格式支持等。
Python 标准库中的模块可以直接通过 import 语句来导入。比如,我们可以导入 math 模块,使用其中的 sqrt 函数来求平方根:
import math
print(math.sqrt(16)) # 输出 4.0
第三方模块
Python 拥有大量的第三方模块,这也是其核心优点之一。这些模块通常在 Python 包管理系统 PyPI 中注册,你可以通过 pip 工具来安装。
比如,我们可以通过 pip install requests 来安装 requests 模块,然后在代码中使用它发送 HTTP 请求:
import requests
response = requests.get('https://www.python.org')
print(response.status_code) # 输出 200
包
Python 为了避免模块名冲突,又引入了按目录来组织模块的方法,称为包(Package)。包是模块的集合,比模块又高一级的封装。包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。一般来说,包名通常为全部小写,避免使用下划线。
标准包
标准包就是文件夹下必须存在 __init__.py 文件,该文件的内容可以为空。如果没有该文件,Python 无法识别出标准包。Python 中导入包后会初始化并执行 __init__.py 进行初始化;在 __init__.py 中,如果将 __all__ 定义为列表,其中包含对象名称的字符串,程序就可以通过 * 的方式导入。
例如,我们有以下的目录结构:
test.py
package_runoob
|-- __init__.py
|-- runoob1.py
|-- runoob2.py
它们的代码如下:
# package_runoob/runoob1.py
def runoob1():
print("I'm in runoob1")
# package_runoob/runoob2.py
def runoob2():
print("I'm in runoob2")
# package_runoob/__init__.py
if __name__ == '__main__':
print('作为主程序运行')
else:
print('package_runoob 初始化')
# test.py
from package_runoob.runoob1 import runoob1
from package_runoob.runoob2 import runoob2
runoob1()
runoob2()
# 输出
# package_runoob 初始化
# I'm in runoob1
# I'm in runoob2
模块和包的导入
Python 模块是一个包含 Python 定义和语句的文件,模块可以定义函数,类和变量。模块也可以包含可执行的代码。包是一种管理 Python 模块命名空间的形式,采用 " 点模块名称 "。
导入方式
在 Python 中,可以通过以下四种方式导入模块或包:
import xx.xx
这种方式将整个模块导入。如果模块中有函数、类或变量,我们需要以 module.xxx 的方式调用。
# Module_a.py
def func():
print("This is module A!")
# Main.py
import module_a
module_a.func() # 调用函数
from xx.xx import xx
这种方式从某个模块中导入某个指定的部分到当前命名空间,不会将整个模块导入。这种方式可以节省代码量,但需要注意避免名字冲突。
# Main.py
from module_a import func
func() # 直接调用 func
from xx.xx import xx as rename
为了避免命名冲突,我们可以在导入时重命名模块。
# Main.py
from module_a import func as f
f() # 使用新名称 f 来调用函数
from xx.xx import \*
这种方式将模块中的所有内容全部导入,非常容易发生命名冲突,因此需要谨慎使用。
# Main.py
from module_a import *
def func():
print("This is the main module!")
func() # func 从 module_a 导入被 main 中的 func 覆盖
绝对导入
绝对导入使用模块的完整路径来导入。这个路径是从项目的根目录开始的,也就是说,从 Python 解释器开始搜索模块的路径。让我们通过一个示例来理解绝对导入。
假设我们有以下项目结构:
myproject/
│
├── main.py
│
└── mypackage/
├── __init__.py
├── module_a.py
└── subpackage/
├── __init__.py
└── module_b.py
在这个项目中,我们有一个主程序 main.py 和一个包 mypackage,包含了模块 module_a.py 和一个子包 subpackage,包含了模块 module_b.py。
在 main.py 中,我们可以使用绝对导入来导入 module_a.py:
# main.py
import mypackage.module_a
在这里,mypackage 是项目的根目录,所以我们使用完整的路径来导入 module_a。
同样,在 module_b.py 中,我们可以使用绝对导入来导入 module_a.py:
# mypackage/subpackage/module_b.py
import mypackage.module_a
适用场景
绝对导入的适用场景包括:
- 明确:绝对导入提供了清晰的模块路径,使得其他开发人员更容易理解模块之间的关系。
- 项目结构不变:当项目结构发生变化时,绝对导入不需要更新导入路径。
- 可移植性:如果一个包被设计成可以独立安装并作为第三方库使用,绝对导入是更好的选择。
相对导入
相对导入是基于当前模块文件的目录结构的。使用 . 表示当前目录,.. 表示父目录,以此类推。相对导入通常用在包内部,当模块之间互相导入时。让我们通过示例来理解相对导入。
在 module_b.py 中,我们可以使用相对导入来导入同一包下的 module_a.py:
# mypackage/subpackage/module_b.py
from .. import module_a
在这里,.. 表示上一级目录,即 mypackage,然后我们导入了 module_a。
注意事项
相对导入需要一些额外的注意事项:
- 相对导入只能用于包内部模块之间的导入,不能用于顶级模块或脚本。
- 如果直接运行一个包含相对导入的模块,可能会导致
ImportError。
适用场景
相对导入通常更适合以下情况:
- 包内部导入:当你在包内部工作时,相对导入可以更好地保持模块的封装性和可移植性。
- 封装和模块重构:相对导入在包内部重构时特别有用,因为它减少了需要更改的导入语句的数量。
模块路径搜索顺序
当我们尝试导入一个模块时,Python 解释器对模块位置的搜索顺序是:
- Python 项目的当前目录
- 在环境变量 PYTHONPATH 中列出的所有目录
- Python 的安装目录和其他默认目录
模块搜索路径存储在 sys 模块的 sys.path 变量中。
import sys
print(sys.path)
命名空间和作用域
在 Python 中,命名空间(Namespace)是从名称到对象的映射,主要用于避免命名冲突。命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。
命名空间类型
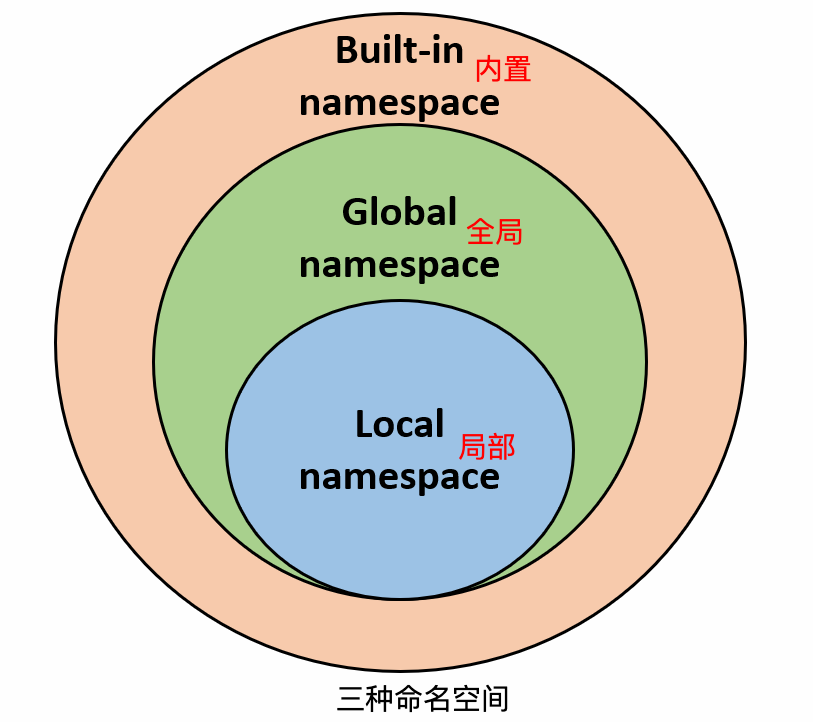
Python 有三种命名空间:
- 内置名称(built-in names):Python 语言内置的名称,如函数名
abs、char和异常名称BaseException、Exception等。 - 全局名称(global names):模块中定义的名称,包括模块的函数、类、导入的模块、模块级别的变量和常量。
- 局部名称(local names):函数中定义的名称,包括函数的参数和局部定义的变量。
作用域
作用域定义了命名空间可以直接访问的代码段,决定了在哪一部分程序可以访问特定的变量名。Python 的作用域一共有 4 种,分别是:

- L(Local):最内层,包含局部变量,比如一个函数/方法内部。
- E(Enclosing):包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类)A 里面又包含了一个函数 B,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
- G(Global):当前脚本的最外层,比如当前模块的全局变量。
- B(Built-in): 包含了内建的变量/关键字等,最后被搜索。
变量的查找顺序是:L --> E --> G --> B。
代码示例
# 全局变量
x = 10
z = 40
# 定义函数 foo
def foo():
# 局部变量
x = 20
z = 50
def bar():
nonlocal z
print("局部变量 z =", z) # 输出 "局部变量 z = 50"
def baz():
global z
print("全局变量 z =", z) # 输出 "全局变量 z = 40"
print("局部变量 x =", x) # 输出 "局部变量 x = 20"
bar()
baz()
# 定义函数 outer
def outer():
y = 30 # 封闭作用域变量
def inner():
nonlocal y
print("封闭作用域 y =", y) # 输出 "封闭作用域 y = 30"
inner()
# 执行函数
foo()
print("全局变量 x =", x) # 输出 "全局变量 x = 10"
outer()
# 调用内置函数
print(abs(-5)) # 输出 5
这个例子展示了 Python 中的作用域和命名空间的概念。在函数 foo 中,变量 x 和 z 是局部变量,只在 foo 函数内部可见。函数 bar 和 baz 改变了 z 的作用域,bar 定义 z 为封闭作用域(foo 函数的作用域),而 baz 定义 z 为全局作用域。函数 outer 和 inner 展示了封闭作用域变量的使用,outer 函数内的 y 变量在 inner 函数中也可见。
最后,我们调用了内置函数 abs,这是一个内置命名空间的例子。所有的内置函数和关键字都在 Python 的内置命名空间中,无需导入就可以直接使用。