Compare commits
8 Commits
a9ecc8d417
...
012f58a101
| Author | SHA1 | Date | |
|---|---|---|---|
|
012f58a101
|
|||
|
5e8f4bfa36
|
|||
|
8652b7ad17
|
|||
|
6fc6e5aee2
|
|||
|
2c03763e60
|
|||
|
5bbceb20f6
|
|||
|
2f3b6fc34f
|
|||
|
e396630045
|
429
Professional/Project/RSSky/项目计划书.md
Normal file
429
Professional/Project/RSSky/项目计划书.md
Normal file
@ -0,0 +1,429 @@
|
||||
---
|
||||
title: 项目计划书
|
||||
description: 《穹顶之下》(RSSky)项目旨在通过建立一个开放的RSS平台,打破信息茧房,提供多元化的信息获取渠道,并通过社区协作管理和代理RSS资源,实现信息的自由流通和高效订阅。
|
||||
keywords:
|
||||
- 信息茧房
|
||||
- RSS
|
||||
- 社区协作
|
||||
- 信息获取
|
||||
- 开放平台
|
||||
- 自由流通
|
||||
tags:
|
||||
- RSSky/项目计划书
|
||||
author: 仲平
|
||||
date: 2024-09-18
|
||||
---
|
||||
|
||||
## 1. 引言
|
||||
|
||||
### 1.1 项目背景
|
||||
|
||||
在信息爆炸的时代,互联网用户面对海量信息时,常常陷入**信息茧房**。这一现象指的是,用户的接收信息渠道受到算法推荐的限制,导致其只能接触到与自己兴趣、观点一致的信息,从而失去了多元视角。这不仅影响了个人的全面认知,也限制了社会整体的多样化对话。
|
||||
|
||||
《穹顶之下》项目(RSSky)旨在通过为用户提供多维度的信息获取渠道,打破信息茧房,提升信息获取的质量和效率。RSSky 的核心理念是建立一个开放、透明、自由的信息获取平台,依托 RSS 技术和社区协作,为用户带来高质量、全面的内容订阅服务。
|
||||
|
||||
### 1.2 项目愿景
|
||||
|
||||
**愿景**:打破信息茧房,提供多元信息获取渠道,提升用户对世界的理解和信息辨别能力。通过社区协作,提供开放、透明、自由的 RSS 资源代理与管理服务。
|
||||
|
||||
## 2. 项目概述
|
||||
|
||||
### 2.1 项目目标
|
||||
|
||||
> 无限可能,为自由而生
|
||||
|
||||
**《穹顶之下》(RSSky)** 的主要目标是为用户提供高质量的 RSS 订阅资源,并通过开源社区协作管理和代理这些资源,确保信息获取的稳定性和高效性。具体目标包括:
|
||||
|
||||
1. **信息开放**:打破信息茧房,提供多元化、全面的信息获取渠道。
|
||||
2. **社区协作**:通过社区成员共同贡献和管理 RSS 资源,实现分布式、协作式的信息提供。
|
||||
3. **自动化管理**:使用自动化技术实现 RSS 资源的更新、验证、路由与缓存管理,确保数据的实时性和稳定性。
|
||||
4. **用户需求满足**:支持个性化需求定制,帮助用户根据兴趣选择、管理和获取内容。
|
||||
|
||||
### 2.2 阶段性目标
|
||||
|
||||
- **阶段一**:完成社区平台的搭建,实现 100 个高质量的 RSS 资源代理,并通过 Cloudflare Workers 进行路由管理。
|
||||
- **阶段二**:扩展到 100 名活跃用户,代理 1000 个 RSS 资源,并支持用户需求定制,优化路由系统性能。
|
||||
|
||||
## 3. 技术方案
|
||||
|
||||
### 3.1 总体架构设计
|
||||
|
||||
RSSky 的核心是 **RSS 资源代理与路由管理**,它通过社区协作者提交的 RSS 资源地址,社区仓库对这些资源进行代理和缓存,所有的爬虫及 RSS 生成工作由协作者独立完成,**社区负责数据的流通与路由映射管理。**
|
||||
|
||||
架构核心模块包括:
|
||||
|
||||
- **Cloudflare Workers**:用于代理和缓存 RSS 请求。
|
||||
- **社区 GitHub 仓库**:用于管理 RSS 路由映射和自动化任务。
|
||||
- **协作者独立爬虫**:由社区协作者独立运行爬虫,生成 RSS 资源。
|
||||
|
||||
#### 3.1.1 核心架构图
|
||||
|
||||
```mermaid
|
||||
graph TD;
|
||||
subgraph Community GitHub Repository ["Community GitHub Repository"]
|
||||
B1[PR: Collaborator submits new RSS feed URL]
|
||||
B2[GitHub Actions: Validate RSS feed URL]
|
||||
B3[GitHub Actions: Merge PR and update mappings]
|
||||
end
|
||||
|
||||
subgraph Cloudflare Workers ["Cloudflare Workers"]
|
||||
A1[Handles routing requests]
|
||||
A2[Caches RSS feed responses]
|
||||
A3[Proxies requests to RSS providers]
|
||||
end
|
||||
|
||||
subgraph Collaborator RSS Providers ["Collaborator RSS Providers"]
|
||||
C1[Collaborator's crawler generates RSS XML]
|
||||
C2[RSS XML file hosted on collaborator's server]
|
||||
end
|
||||
|
||||
subgraph Users ["Users"]
|
||||
D1[User requests RSS feed]
|
||||
D2[Receives RSS feed response]
|
||||
end
|
||||
|
||||
B1 --> B2 --> B3
|
||||
B3 --> A1
|
||||
A1 --> A2
|
||||
A1 --> A3
|
||||
A3 --> C2
|
||||
C1 --> C2
|
||||
A2 --> D2
|
||||
D1 --> A1
|
||||
```
|
||||
|
||||
#### 3.1.2 核心流程图
|
||||
|
||||
```mermaid
|
||||
sequenceDiagram
|
||||
participant Collaborator as 协作者
|
||||
participant GitHub as GitHub Repository
|
||||
participant GitHubActions as GitHub Actions
|
||||
participant Cloudflare as Cloudflare Workers
|
||||
participant Cache as Cache
|
||||
participant CollaboratorServer as 协作者服务器
|
||||
participant User as 用户
|
||||
|
||||
%% 协作者提交和处理流程
|
||||
Collaborator->>GitHub: 提交 PR (新 RSS 源或更新源)
|
||||
GitHub-->>GitHubActions: 触发 GitHub Actions 任务
|
||||
GitHubActions->>GitHubActions: 验证 RSS URL 可用性和格式
|
||||
GitHubActions-->>Collaborator: 验证通过/失败反馈
|
||||
GitHubActions->>GitHub: 合并 PR 并更新路由映射
|
||||
GitHubActions->>Cloudflare: 更新 Cloudflare Workers 的路由配置
|
||||
|
||||
%% 用户请求和处理流程
|
||||
User->>Cloudflare: 请求 RSS 源 (代理地址)
|
||||
Cloudflare->>Cache: 检查缓存是否存在
|
||||
alt 缓存命中
|
||||
Cache-->>Cloudflare: 返回缓存的 RSS 文件
|
||||
Cloudflare-->>User: 返回缓存的 RSS 文件
|
||||
else 缓存未命中
|
||||
Cloudflare->>CollaboratorServer: 请求协作者服务器获取最新 RSS 文件
|
||||
CollaboratorServer-->>Cloudflare: 返回最新的 RSS 文件
|
||||
Cloudflare->>Cache: 缓存新的 RSS 文件
|
||||
Cloudflare-->>User: 返回最新的 RSS 文件
|
||||
end
|
||||
```
|
||||
|
||||
#### 3.1.3 核心功能模块
|
||||
|
||||
##### Cloudflare Workers 路由管理
|
||||
|
||||
**Cloudflare Workers** 是整个系统的核心代理模块,负责处理所有用户的 RSS 资源请求,并代理协作者提供的真实 RSS 地址。
|
||||
|
||||
```mermaid
|
||||
sequenceDiagram
|
||||
participant User as 用户
|
||||
participant Cloudflare as Cloudflare Workers
|
||||
participant Cache as Workers 缓存
|
||||
participant CollaboratorServer as 协作者服务器
|
||||
|
||||
User->>Cloudflare: 请求代理 RSS 地址
|
||||
Cloudflare->>Cache: 检查 RSS 是否已缓存
|
||||
alt 缓存命中
|
||||
Cache-->>Cloudflare: 返回缓存的 RSS 文件
|
||||
Cloudflare-->>User: 返回 RSS 文件
|
||||
else 缓存未命中
|
||||
Cloudflare->>CollaboratorServer: 请求协作者服务器获取最新 RSS 文件
|
||||
CollaboratorServer-->>Cloudflare: 返回最新 RSS 文件
|
||||
Cloudflare->>Cache: 缓存新的 RSS 文件
|
||||
Cloudflare-->>User: 返回最新的 RSS 文件
|
||||
end
|
||||
```
|
||||
|
||||
它的主要职责包括:
|
||||
|
||||
1. **处理路由请求**:
|
||||
- Cloudflare Workers 接收用户请求并通过路由映射找到相应的 RSS 资源地址。
|
||||
- 当用户访问代理的 RSS 地址时,Cloudflare Workers 负责转发请求并获取真实的 RSS 资源。
|
||||
2. **缓存管理**:
|
||||
- 为提高效率,Cloudflare Workers 会将已请求的 RSS 文件进行缓存,下一次请求同样的资源时,直接从缓存中返回结果。
|
||||
- 缓存策略会根据 RSS 内容的更新频率进行动态调整,确保用户始终获取最新的 RSS 信息。
|
||||
3. **代理与负载均衡**:
|
||||
- 当缓存失效或 RSS 源地址不可访问时,Cloudflare Workers 通过代理访问协作者服务器以获取最新 RSS 文件。
|
||||
|
||||
##### 社区 GitHub 仓库
|
||||
|
||||
社区 GitHub 仓库作为系统的核心协作平台,管理所有 RSS 资源的路由映射文件及更新。每一个 RSS 资源由社区成员通过 PR 提交。
|
||||
|
||||
```mermaid
|
||||
sequenceDiagram
|
||||
participant Collaborator as 协作者
|
||||
participant GitHub as GitHub Repository
|
||||
participant GitHubActions as GitHub Actions
|
||||
participant Cloudflare as Cloudflare Workers
|
||||
|
||||
Collaborator->>GitHub: 提交 PR (新 RSS 源/更新源)
|
||||
GitHub-->>GitHubActions: 触发 GitHub Actions
|
||||
GitHubActions->>GitHubActions: 验证 RSS 源(可访问性、格式正确性)
|
||||
GitHubActions-->>Collaborator: 验证通过/失败反馈
|
||||
GitHubActions->>GitHub: 合并 PR
|
||||
GitHubActions->>Cloudflare: 更新 Cloudflare Workers 路由映射
|
||||
```
|
||||
|
||||
社区具体功能包括:
|
||||
|
||||
1. **PR 提交与验证**:
|
||||
- 协作者可以通过 GitHub PR 提交新的 RSS 资源地址或更新已有的地址。
|
||||
- GitHub Actions 自动触发对 RSS 资源的验证,确保提交的地址能够正常访问,并且格式正确。
|
||||
2. **自动化管理**:
|
||||
- 验证通过后,GitHub Actions 会自动合并 PR 并更新路由映射文件。这些映射文件由 Cloudflare Workers 使用,确保用户请求能够正确路由到真实的 RSS 地址。
|
||||
- GitHub Actions 定期执行健康检查,验证现有 RSS 资源的可用性,若发现失效资源,将通知相关贡献者修复或删除。
|
||||
3. **社区协作与贡献激励**:
|
||||
- 社区成员通过贡献 RSS 资源或修复现有问题,提升社区的活跃度。GitHub 仓库提供公开的贡献历史,社区可以通过排行榜、积分等机制激励成员贡献。
|
||||
|
||||
##### 协作者独立爬虫
|
||||
|
||||
协作者独立爬虫是系统的基础数据来源,由各个社区贡献者负责编写、维护并托管。
|
||||
|
||||
```mermaid
|
||||
sequenceDiagram
|
||||
participant Collaborator as 协作者
|
||||
participant Crawler as 爬虫脚本
|
||||
participant CollaboratorServer as 协作者服务器
|
||||
participant GitHub as GitHub Repository
|
||||
participant GitHubActions as GitHub Actions
|
||||
|
||||
Collaborator->>Crawler: 定期运行爬虫抓取数据
|
||||
Crawler->>CollaboratorServer: 生成 RSS 文件并托管
|
||||
Collaborator->>GitHub: 提交新的 RSS 地址/更新地址至 GitHub
|
||||
GitHub-->>GitHubActions: 触发自动化验证
|
||||
GitHubActions->>GitHubActions: 验证 RSS 文件并更新映射
|
||||
```
|
||||
|
||||
其主要功能和责任如下:
|
||||
|
||||
1. **RSS 生成与托管**:
|
||||
- 协作者可以使用任意编程语言编写爬虫,负责抓取目标网站的内容并生成 RSS 文件。每个协作者独立运行自己的爬虫,系统不会集中管理爬虫任务。
|
||||
- 生成的 RSS 文件由协作者服务器托管,协作者需要定期维护爬虫,确保 RSS 文件的时效性。
|
||||
2. **自动化生成与更新**:
|
||||
- 协作者可以通过 GitHub Actions 或其他定时任务自动生成和更新 RSS 文件。例如,协作者可以设置每天定时运行爬虫,抓取最新的内容并更新 RSS 文件。
|
||||
- RSS 文件生成后,协作者将地址提交至社区 GitHub 仓库,系统自动更新对应的路由映射。
|
||||
3. **灵活性与兼容性**:
|
||||
- 系统允许协作者使用多种语言编写爬虫,例如 Python、Node.js 或 Rust 等。不同协作者可以根据自己熟悉的开发环境选择合适的技术栈,提升社区贡献的灵活性。
|
||||
- 为确保统一标准,建议社区提供爬虫编写的模板和代码规范,确保不同语言编写的爬虫都能顺利集成到系统中。
|
||||
|
||||
### 3.2 技术选型
|
||||
|
||||
1. **语言与开发工具**:
|
||||
- **JavaScript**:用于编写 Cloudflare Workers 路由逻辑。
|
||||
- **Python、Node.js、Rust**:协作者可以自行选择开发 RSS 爬虫的语言,**项目不限制爬虫开发语言。**
|
||||
- **GitHub Actions**:用于处理自动化任务,如提交的 RSS 资源验证、合并、定期更新等。
|
||||
2. **数据库与存储**:
|
||||
- **GitHub 仓库**:社区不直接存储 RSS 数据,仅存储 URL 映射文件,数据存储由提供者决定。
|
||||
- **缓存机制**:Cloudflare Workers 通过缓存管理 RSS 资源,确保访问效率。
|
||||
3. **代理与路由管理**:
|
||||
- **Cloudflare Workers**:用于动态代理协作者提供的 RSS 资源。
|
||||
|
||||
### 3.3 核心功能实现
|
||||
|
||||
项目的核心功能围绕**自动化工作流**、**用户界面与订阅管理**、以及**健康监控与通知**展开。这些功能不仅确保 RSS 资源的自动更新和管理,还提供了一种用户友好的交互方式,以便轻松管理和订阅内容。
|
||||
|
||||
#### 3.3.1 自动化工作流
|
||||
|
||||
**GitHub Actions** 在整个项目中扮演了自动化管理的关键角色,通过其强大的 CI/CD 流程,协作者提交的 RSS 资源能够得到快速验证、自动化处理和更新。自动化工作流的几个关键部分包括:
|
||||
|
||||
1. **PR 提交与自动化处理**:
|
||||
- 当协作者提交新的 RSS 资源或更新现有资源时,GitHub Actions 会自动触发,进行以下步骤:
|
||||
- 验证提交的 RSS URL 是否能够正常访问。
|
||||
- 检查 RSS 源的内容格式是否正确。
|
||||
- 验证通过后,自动合并 PR 到主仓库。
|
||||
- 如果验证失败,GitHub Actions 会通过评论通知提交者,并提供失败原因及修复建议。
|
||||
2. **自动化健康监控**:
|
||||
- **定期任务**:GitHub Actions 通过定期执行的任务,检查所有已代理的 RSS 资源的可用性。确保每个资源能够在特定时间窗口内正常访问。
|
||||
- **自动修复**:当某个 RSS 资源无法访问时,GitHub Actions 可以通知协作者修复或更新资源。如果资源未能在规定时间内恢复,系统将自动标记为失效,并建议用户切换到备用资源。
|
||||
3. **版本管理与发布**:
|
||||
- **自动化版本发布**:每周发布新版本,包含所有新提交的 RSS 资源及改进。每日生成体验版本,用于测试和持续改进系统功能。
|
||||
- **GitHub Releases**:每个稳定版本会自动发布到 GitHub Releases,社区开发者和用户可以获取最新的资源映射和路由信息。
|
||||
|
||||
#### 3.3.2 用户界面与订阅管理
|
||||
|
||||
项目通过**基于 Markdown 文件**来构建一个用户友好的静态站点界面,帮助用户轻松管理和订阅 RSS 资源。静态站点的优点是结构简单、维护方便、性能优越,并且可以与 GitHub Pages 无缝集成。以下是核心功能模块的详细说明:
|
||||
|
||||
1. **基于 Markdown 的静态站点**:
|
||||
- 使用静态站点生成器基于 Markdown 文件构建一个简单直观的 Web 界面。每个 RSS 源都有一个对应的内容,文件中包含 RSS 源的详细信息、使用说明、订阅地址等。
|
||||
- 该静态站点将托管在 GitHub Pages 上,用户可以直接访问,并通过搜索或分类功能查找感兴趣的订阅源。
|
||||
2. **订阅管理与搜索功能**:
|
||||
- **搜索功能**:用户可以通过站点内置的搜索引擎(如 Lunr.js 或 Algolia)搜索 RSS 资源。关键词搜索能够快速找到符合条件的 RSS 订阅源,极大提高了用户查找效率。
|
||||
- **分类展示**:每个 RSS 资源根据类别(如新闻、科技、娱乐等)进行分类展示,用户可以通过分类标签快速找到自己感兴趣的资源。每个分类页面使用 Markdown 文件生成,简单明了,方便用户浏览。
|
||||
3. **个性化推荐与管理**:
|
||||
- **RSS 管理面板**:为用户提供简单的订阅管理面板,用户可以收藏、标记或取消订阅 RSS 源。管理面板将依靠客户端存储(如 LocalStorage)保持用户偏好,便于浏览器持久化用户的订阅记录。
|
||||
- **一键订阅**:每个 RSS 资源都提供一键复制订阅地址功能,用户可以快速将订阅地址复制并粘贴到其 RSS 阅读器中。
|
||||
4. **RSS 资源展示与说明**:
|
||||
- 每个 RSS 资源的详细页面包含资源的介绍、更新频率、内容预览、订阅地址等详细信息。
|
||||
- 通过模板化 Markdown 文件生成资源页面,确保所有 RSS 源的展示信息一致且规范。
|
||||
|
||||
#### 3.3.3 健康监控与通知
|
||||
|
||||
系统通过**自动化健康监控机制**确保所有代理的 RSS 源在服务期间始终可用,并提供多层次的通知机制以便及时处理出现的任何问题。以下是功能模块的详细说明:
|
||||
|
||||
1. **自动化健康检查**:
|
||||
- **定期任务**:通过 GitHub Actions 定期执行健康检查任务,验证所有 RSS 资源的可访问性和格式是否正确。
|
||||
- **内容验证**:检查每个 RSS 文件是否符合标准格式,如 `<channel>`, `<item>` 等必要的标签。确保 RSS 资源可以正常解析和使用。
|
||||
- **更新频率检测**:通过分析 RSS 源中的 `<pubDate>` 或 `<lastBuildDate>`,检测资源是否定期更新。对于长时间未更新的资源,标记为需要维护或替换。
|
||||
2. **问题通知与修复建议**:
|
||||
- **协作者通知**:当发现某个 RSS 源失效时,系统会通过 GitHub Issues 自动生成问题报告,并通知协作者进行修复。协作者会收到问题的详细说明,包括失效原因和修复建议。
|
||||
- **邮件与推送通知**:协作者还会收到邮件通知或推送消息,确保他们能够及时修复问题,维持资源的可用性。
|
||||
- **问题报告**:所有检测结果会生成报告,并记录在 GitHub 中,便于社区成员审查和后续维护。
|
||||
3. **备用资源支持**:
|
||||
- **备用源配置**:为一些重要或高访问量的 RSS 资源设置备用源,确保在主 RSS 资源失效时,系统可以自动切换到备用资源。
|
||||
- **自动切换**:当健康检查发现主源失效时,系统会自动启用备用源,保障服务的连续性。用户无需任何手动操作,系统会自动处理切换。
|
||||
- **备用源管理**:协作者可以通过提交 PR 方式更新或增加备用 RSS 源,确保资源在出现问题时能够顺利切换。
|
||||
4. **用户反馈与问题报告**:
|
||||
- **用户通知**:当系统切换到备用资源时,用户将收到简要的通知,告知当前资源的状况。用户可以在资源页面查看详细信息,并选择是否手动更新订阅。
|
||||
- **问题反馈渠道**:用户可以通过静态站点的反馈功能报告失效的 RSS 资源。提交的反馈会转化为 GitHub Issues,供协作者查看并处理。
|
||||
|
||||
#### 3.3.4 社区协作与贡献者管理
|
||||
|
||||
社区协作是 RSSky 项目的基础,协作者通过贡献 RSS 资源并不断完善系统,维持项目的高活跃度。为了确保项目长期健康发展,系统提供了一套协作和管理机制,帮助社区成员更高效地参与项目。
|
||||
|
||||
1. **贡献者管理与激励机制**:
|
||||
- **贡献者排行榜**:每个贡献者的贡献(包括提交的 RSS 源、修复的问题等)都会被记录,并根据贡献量进行积分评定。贡献者可以通过排行榜查看自己的排名,激励社区成员更加积极地参与。
|
||||
- **贡献奖励与徽章系统**:为激励活跃的贡献者,项目引入了社区徽章和奖励系统。核心贡献者可以获得“活跃贡献者”、“修复专家”等徽章,这些徽章会展示在贡献者的 GitHub 个人资料上,增加社区声望。
|
||||
- **长期贡献者的社区影响力**:核心贡献者可以被邀请参与项目的长期规划,帮助制定新功能的路线图,并参与项目的重大决策,进一步增强社区归属感。
|
||||
2. **贡献者协作流程**:
|
||||
- **GitHub PR 审核流程**:贡献者通过 PR 向项目提交新功能或 RSS 资源。系统通过 GitHub Actions 自动验证 PR 的正确性(如 RSS URL 的有效性、内容格式的正确性等)。社区维护者或管理员在自动验证通过后,可以进一步进行手动审查和合并。
|
||||
- **社区反馈与讨论**:贡献者提交的 PR 可以通过 GitHub Discussions 或 Issues 进行社区讨论,确保提交的功能或 RSS 资源符合社区共识。这种开源协作的模式可以确保所有变更都能被详细审查和讨论。
|
||||
3. **协作模板与文档支持**:
|
||||
- **贡献指南**:为协作者提供详细的贡献指南,帮助新加入的贡献者快速上手。指南中包含如何提交 PR、如何编写 RSS 源格式、以及如何通过 GitHub Actions 进行自动化测试等。
|
||||
- **模板与代码规范**:为确保不同贡献者提交的代码和 RSS 源符合统一标准,项目提供了模板和代码规范文档。所有贡献者在提交代码或 RSS 源之前,需要使用这些模板和规范进行检查,确保代码的可维护性和一致性。
|
||||
4. **定期社区活动与黑客松**:
|
||||
- **社区黑客松**:项目可以定期组织在线黑客松活动,邀请全球开发者参与,推动新功能的开发和讨论。黑客松不仅能够激发创新,也能为项目引入更多新贡献者。
|
||||
- **反馈与路线图讨论**:项目管理员可以定期发起社区讨论,听取社区成员的意见和建议,并根据讨论结果调整未来的开发路线图。
|
||||
|
||||
### 3.4 项目路线图
|
||||
|
||||
#### 3.4.1 短期目标(0-6 个月)
|
||||
|
||||
- 实现基础的 RSS 资源代理和路由管理功能,使用 Cloudflare Workers 处理 RSS 资源请求。
|
||||
- 吸引社区成员贡献 RSS 资源,完善 PR 流程,实现自动化更新和验证。
|
||||
- 提供用户订阅管理的基本 Web 界面,支持一键订阅和管理功能。
|
||||
|
||||
以帮助项目更好地监控和追踪进展。
|
||||
|
||||
| 主任务 | 子任务 | 状态 |
|
||||
| ---------------------- | --------------------------------------- | --- |
|
||||
| **完成基础 RSS 资源代理与路由管理** | 构建 Cloudflare Workers 路由逻辑 | |
|
||||
| | 实现 RSS URL 到真实源地址的路由映射 | |
|
||||
| | 实现基本缓存管理机制(支持频繁更新的 RSS 缓存刷新) | |
|
||||
| | 配置负载均衡机制,处理高并发 RSS 请求 | |
|
||||
| | 创建基础状态页面,展示路由和缓存状态 | |
|
||||
| **实现自动化工作流与 PR 管理** | 集成 GitHub Actions,自动触发 PR 检查 | |
|
||||
| | 编写 PR 验证脚本,检查 RSS 源可用性和格式 | |
|
||||
| | 自动合并通过验证的 PR,更新路由映射 | |
|
||||
| | 创建状态页面,展示 PR 提交、验证、合并的实时状态 | |
|
||||
| **搭建用户界面与订阅管理** | 使用 Hugo 或 Jekyll 构建静态站点 | |
|
||||
| | 创建 RSS 源详细页面(包含订阅地址、说明) | |
|
||||
| | 集成 Lunr.js 或 Algolia 搜索引擎,支持 RSS 源关键词搜索 | |
|
||||
| | 按类别展示 RSS 源,提供分类筛选功能 | |
|
||||
| | 为每个 RSS 源创建一键复制订阅地址的功能 | |
|
||||
| | 创建状态页面,展示站点更新和页面访问数据 | |
|
||||
| **吸引社区协作者贡献 RSS 资源** | 编写贡献指南,详细描述如何编写爬虫和提交 RSS 源 | |
|
||||
| | 提供爬虫模板,支持多种语言(Python、Node.js、Rust) | |
|
||||
| | 开展社区推广活动,通过开发者论坛和社交媒体吸引贡献者 | |
|
||||
| | 设置贡献排行榜,展示贡献者提交的 RSS 源和参与度 | |
|
||||
| | 创建状态页面,展示社区成员贡献的统计数据 | |
|
||||
|
||||
#### 3.4.2 中期目标(6-12 个月)
|
||||
|
||||
- 扩展到 1000 个高质量的 RSS 订阅源,优化路由管理功能,提升系统的稳定性和性能。
|
||||
- 引入个性化推荐功能,通过分析用户的订阅历史,为用户提供更多相关 RSS 资源推荐。
|
||||
- 完善用户界面,增加 RSS 资源的可视化管理和分类功能,帮助用户更好地管理信息。
|
||||
|
||||
| 主任务 | 子任务 |
|
||||
| ------------------------------- | ------------------------------------------------------------ |
|
||||
| **扩展 RSS 资源与优化缓存策略** | 扩展至 1000 个高质量的 RSS 资源 |
|
||||
| | 为不同类型的 RSS 源优化缓存策略(高频、低频源不同缓存时间) |
|
||||
| | 对路由映射进行优化,减少处理时间 |
|
||||
| | 设置缓存刷新状态页面,实时展示缓存命中率和缓存刷新周期 |
|
||||
| **开发个性化推荐功能** | 通过分析用户订阅历史,开发个性化 RSS 源推荐算法 |
|
||||
| | 在用户界面增加推荐模块,提供相关推荐 RSS 源 |
|
||||
| | 开发订阅管理面板,支持收藏、标记已读、取消订阅等操作 |
|
||||
| **健康监控与备用资源支持** | 开发 GitHub Actions 任务,定期检查 RSS 源的可用性和更新频率 |
|
||||
| | 为高访问量的 RSS 源设置备用资源,自动切换到备用源 |
|
||||
| | 为协作者提供 RSS 源状态通知,提醒源失效或需更新 |
|
||||
| | 创建状态页面,展示 RSS 源健康状态(可用性、频率、错误报告等) |
|
||||
| **完善社区激励与协作机制** | 引入贡献者排行榜,展示贡献者的提交、修复等贡献记录 |
|
||||
| | 增加贡献徽章系统,奖励活跃贡献者 |
|
||||
| | 定期举办线上黑客松活动,激励新功能开发和修复任务 |
|
||||
| | 创建状态页面,展示社区活动的参与情况和贡献者活跃度 |
|
||||
|
||||
## 4. 用户体验与社区运营
|
||||
|
||||
### 4.1 用户体验
|
||||
|
||||
1. **稳定性与高可用性**:
|
||||
- 通过 Cloudflare Workers 的缓存机制,用户可以快速访问代理的 RSS 资源,确保信息流的稳定性和高效性。
|
||||
- 健康监控机制确保 RSS 源始终有效,用户可以获得高质量的订阅体验。
|
||||
2. **个性化推荐**:
|
||||
- 系统通过用户订阅行为分析,为用户推荐与其兴趣相关的 RSS 源,帮助用户避免信息过载,并提升信息获取的效率。
|
||||
3. **多维度管理**:
|
||||
- 用户可以通过 Web 界面轻松管理订阅源,并根据个人需求进行订阅源分类和筛选。
|
||||
|
||||
### 4.2 社区协作与运营
|
||||
|
||||
1. **贡献者管理与激励**:
|
||||
- 通过贡献者排行榜和积分机制,激励社区成员提交优质的 RSS 资源。贡献者可以通过定期提交和维护获得社区认可和奖励。
|
||||
- 核心贡献者将有机会参与项目的长期发展规划,提升社区的参与度和活跃度。
|
||||
2. **运营成本管理**:
|
||||
- 初期依赖 Cloudflare Workers 进行代理和路由,随着用户规模扩大,可以逐步引入自建 Nginx 反向代理,优化系统的流量管理,降低运营成本。
|
||||
- 项目也可以通过与云服务提供商建立合作,利用免费资源进一步降低成本。
|
||||
|
||||
### 4.3 社区增长策略
|
||||
|
||||
- **推广和营销**:通过社交媒体、开发者论坛、开源社区等渠道推广项目,吸引更多用户和开发者参与。
|
||||
- **合作伙伴计划**:与相关的 RSS 订阅平台、信息流工具建立合作伙伴关系,增加 RSSky 的知名度。
|
||||
- **社区激励计划**:引入贡献者奖励机制,通过排行榜、徽章、积分等方式,激励更多开发者和贡献者积极参与项目建设。
|
||||
|
||||
### 4.4 持续创新
|
||||
|
||||
- **AI 驱动的个性化推荐**:引入基于 AI 的算法模型,进一步优化个性化推荐功能,让用户能够快速找到感兴趣的订阅源。
|
||||
- **分布式缓存与优化**:随着用户规模的扩展,引入分布式缓存和 CDN 技术,进一步提高系统的响应速度和稳定性,确保全球范围内用户都能高效访问内容。
|
||||
- **新技术引入**:密切关注前沿技术的发展,如去中心化的内容发布协议、更加高效的内容聚合工具等,并探索这些技术如何与 RSSky 项目结合,推动项目的技术革新。
|
||||
|
||||
## 5. 开发者文档与协作
|
||||
|
||||
### 5.1 开发者支持
|
||||
|
||||
1. 详细文档:
|
||||
- 提供详细的开发者文档,包含如何编写爬虫、如何通过 GitHub Actions 自动生成 RSS 源,以及如何提交 PR。
|
||||
2. 标准化工具链:
|
||||
- 制定统一的代码规范和测试标准,确保不同语言的爬虫代码具有一致性,便于项目的长期维护和扩展。
|
||||
|
||||
### 5.2 贡献指南
|
||||
|
||||
1. 贡献流程:
|
||||
- 开发者可以通过 GitHub 提交 PR,RSS 源的提交和更新将由 GitHub Actions 自动化处理。贡献者可以通过贡献文档了解详细的贡献指南。
|
||||
2. 贡献激励:
|
||||
- 通过贡献者的活跃度和代码质量进行评估,为高质量贡献者提供社区认可和奖励,增强社区凝聚力。
|
||||
|
||||
## 6. 安全性与合法性
|
||||
|
||||
### 6.1 数据安全
|
||||
|
||||
- **用户隐私保护**:项目不存储用户的个人数据,所有 RSS 资源的获取通过代理完成,确保用户信息的隐私性。
|
||||
|
||||
### 6.2 法律合规
|
||||
|
||||
- **内容版权保护**:原则上所有提交的 RSS 资源必须经过社区审核,确保其合法合规,避免侵犯目标网站的版权和知识产权。
|
||||
@ -1,32 +0,0 @@
|
||||
---
|
||||
title: 前端工程师(Front-End Engineer)
|
||||
date: 2023-11-09
|
||||
---
|
||||
|
||||
## 前端工程师(Front-End Engineer)
|
||||
|
||||
前端工程师是负责构建和维护网页或 Web 应用用户界面的专业人员,他们将设计师的设计稿和后端开发者的 API 转换为可以在浏览器上运行的网页或应用。
|
||||
|
||||
**职责与工作内容:**
|
||||
|
||||
1. **构建用户界面**:使用 HTML、CSS 和 JavaScript 构建网页或应用的用户界面。
|
||||
2. **实现交互效果**:编写 JavaScript 代码来实现用户与网页或应用的交互。
|
||||
3. **优化性能**:优化前端代码和资源加载,提升网页的加载速度和运行性能。
|
||||
4. **响应式设计**:使网页或应用能够适应不同的设备和屏幕尺寸。
|
||||
5. **与后端协作**:与后端开发者协作,实现数据的前后端交互。
|
||||
6. **测试与调试**:使用各种工具对前端代码进行测试和调试,保证代码的质量和稳定性。
|
||||
|
||||
**必备技能与知识:**
|
||||
|
||||
1. **HTML/CSS/JavaScript**:这是前端开发的基础,HTML 用于描述网页内容,CSS 用于描述网页样式,JavaScript 用于实现网页交互。
|
||||
2. **前端框架和库**:如 React、Angular 或 Vue.js,这些框架能够帮助开发者更容易地构建复杂的前端应用。
|
||||
3. **版本控制系统**:如 Git,用于代码的版本管理和多人协作。
|
||||
4. **构建和打包工具**:如 Webpack、Babel,用于优化和转译前端代码。
|
||||
5. **浏览器开发工具**:理解并熟练使用浏览器的开发者工具,用于代码调试和性能分析。
|
||||
6. **对用户体验的理解**:理解并关注用户体验,包括交互设计、可访问性、性能优化等。
|
||||
|
||||
总体来说,前端工程师的目标是构建和维护高性能、易用、美观的用户界面,他们通过技术手段,使得用户可以愉快、高效地使用网页或 Web 应用,满足用户的需求。他们的工作直接影响到用户的体验,对于提升产品的价值和满足客户需求至关重要。
|
||||
|
||||
### RoadMap
|
||||
|
||||
|
||||
@ -1,48 +0,0 @@
|
||||
---
|
||||
title: 历史发展
|
||||
description: 前端开发历史发展
|
||||
keywords:
|
||||
- 前端开发
|
||||
- 历史发展
|
||||
tags:
|
||||
- FullStack/文化
|
||||
sidebar_position: 2
|
||||
author: 7Wate
|
||||
date: 2023-10-16
|
||||
---
|
||||
|
||||
前端开发已经经历了长达几十年的发展历程,从最初的静态网页到现在的复杂的 Web 交互应用,前端开发的技术和工具都发生了巨大的变化。下面是前端开发的一些主要发展阶段:
|
||||
|
||||
## 1990 年代:静态网页时代
|
||||
|
||||
在 1990 年,Tim Berners-Lee 发明了万维网,也就标志着网页的诞生。在这个阶段,网页主要由纯文本构成,使用 HTML(HyperText Markup Language)进行标记。这些网页被称为静态网页,因为它们的内容在服务器端生成,用户端不能交互和修改。
|
||||
|
||||
## 1995 年:JavaScript 的诞生
|
||||
|
||||
1995 年,JavaScript 语言在 Netscape 浏览器上首次亮相,由 Brendan Eich 发明。最初,JavaScript 被用作一种客户端的脚本语言,用于实现网页上的简单交互效果,如表单验证等。
|
||||
|
||||
## 1996 年: CSS 的诞生
|
||||
|
||||
1996 年,W3C(万维网联盟)发布了 CSS(Cascading Style Sheets)的第一版规范,标志着样式表的诞生。CSS 的出现使得开发者可以更加方便地控制网页的样式和布局。
|
||||
|
||||
## 2000 年代初:动态网页和 AJAX
|
||||
|
||||
2000 年代初,随着 JavaScript 和服务端技术的发展,网页开始从静态向动态转变。AJAX(Asynchronous JavaScript and XML)技术的出现,使得网页可以在不刷新页面的情况下与服务器进行交互,极大地提高了用户体验。
|
||||
|
||||
## 2006 年:jQuery 的出现
|
||||
|
||||
2006 年,jQuery 库发布,提供了一种简洁易用的 API 来操作 HTML 文档、处理事件、创建动画以及进行 AJAX 交互。jQuery 的出现极大地简化了前端开发,使得开发者可以用更少的代码完成更多的功能。
|
||||
|
||||
## 2008 年:Chrome 浏览器和 V8 引擎
|
||||
|
||||
2008 年,Google 发布了 Chrome 浏览器和 V8 JavaScript 引擎。V8 引擎的出现极大地提升了 JavaScript 的运行速度,使得 JavaScript 能够用于更复杂的应用。
|
||||
|
||||
## 2010 年代:前端框架和工具的崛起
|
||||
|
||||
2010 年代,前端开发进入了一个新的时代。一方面,出现了大量的前端框架和库,如 Angular、React 和 Vue.js,使得开发者可以更容易地构建复杂的前端应用。另一方面,前端开发工具和生态系统也得到了极大的发展,如 Node.js、webpack、Babel、ESLint 等。
|
||||
|
||||
## 2015 年至今:现代前端开发
|
||||
|
||||
2015 年,ECMAScript 6(也称为 ES2015)的发布,为 JavaScript 带来了许多新的语言特性,如类、模块、箭头函数、Promises、生成器等。同时,随着 Web Components 和 Progressive Web Apps(PWA)的出现,前端开发正在朝着更加模块化、组件化和原生应用化的方向发展。
|
||||
|
||||
在过去的几十年里,前端开发经历了从静态网页到复杂 Web 应用的巨大转变。尽管前端开发的技术和工具不断变化,但其核心目标一直未变,那就是创建出色的用户体验。
|
||||
@ -1,56 +0,0 @@
|
||||
---
|
||||
title: 概述
|
||||
description: H5 前端开发概述
|
||||
keywords:
|
||||
- 前端开发
|
||||
- HTML5
|
||||
tags:
|
||||
- FullStack/文化
|
||||
sidebar_position: 1
|
||||
author: 7Wate
|
||||
date: 2023-10-13
|
||||
---
|
||||
|
||||
## 简介
|
||||
|
||||
前端开发是当今技术领域的重要组成部分,它使我们能够以视觉上吸引人的、交互式的方式浏览网站和网络应用程序。
|
||||
|
||||
### 前端开发的定义
|
||||
|
||||
前端开发,有时也被称为客户端开发,是创建网络应用程序或网站用户交互界面的实践。它涉及到的技术包括 HTML、CSS 和 JavaScript,以及各种现代框架和库,如 React、Angular 和 Vue.js。前端开发者的目标是提供一个高度交互的、用户友好的界面,它可以在各种设备和浏览器上无缝工作。
|
||||
|
||||
### 前端与后端的区别
|
||||
|
||||
**在理解前端和后端的区别时,最直接的比喻可能就是一家餐厅。在这个比喻中,前端开发者就像是餐厅的服务员,他们直接与顾客(用户)互动,提供菜单,接收订单,并提供所需的食物(数据)。而后端开发者就像是厨师,他们在幕后处理服务员传来的订单,并准备好食物。**
|
||||
|
||||
在技术方面,前端开发主要关注用户界面和用户体验,而后端开发则是处理服务器、应用和数据库之间的交互。后端开发者使用如 Python、Ruby、Java、PHP 等服务器端语言,创建应用的业务逻辑,管理数据库,以及处理用户的请求和响应。
|
||||
|
||||
### 前端开发的重要性
|
||||
|
||||
前端开发的重要性在于它**直接影响到用户的体验。**一个易于使用、视觉吸引人的界面可以大大增加用户的满意度,提高用户的参与度,甚至影响到公司的品牌形象。此外,前端开发也涉及到网站的可访问性和响应式设计,这可以确保所有用户,无论他们使用的设备类型或者他们的身体能力如何,都可以方便的访问和使用网站。
|
||||
|
||||
在当今的数字化世界中,前端开发已经变得至关重要。无论是小型的静态网站,还是大型的复杂网络应用,都需要前端开发者的专业技能和经验来创建用户友好的界面。在未来,随着技术的不断发展和新的用户需求的出现,前端开发的重要性只会继续增加。
|
||||
|
||||
## 未来发展趋势
|
||||
|
||||
在未来,前端开发预计将继续迅速发展和变化。以下是一些可能的发展趋势:
|
||||
|
||||
### 更丰富的交互体验
|
||||
|
||||
随着技术的进步,我们可以预期更加丰富和复杂的用户界面和交互体验。例如,虚拟现实(VR)和增强现实(AR)技术可能会更加普及,为前端开发带来全新的挑战和机遇。另外,随着机器学习和人工智能的发展,我们可能会看到更多的自适应和个性化的用户界面。
|
||||
|
||||
### 新的和改进的工具
|
||||
|
||||
前端开发工具在不断发展和改进。新的编程语言、库和框架正在不断出现,以解决前端开发者面临的新的挑战。例如,WebAssembly 可能会改变我们构建和运行前端应用的方式,而像 React Native 这样的框架可能会继续改变我们开发跨平台应用的方式。
|
||||
|
||||
### 性能优化
|
||||
|
||||
随着用户对于网页响应速度和流畅度的期望越来越高,性能优化将继续是前端开发的重要主题。包括如何有效地使用缓存、如何优化代码以减少加载时间、如何更好地使用网络资源等方面。
|
||||
|
||||
### Web 安全性
|
||||
|
||||
随着网络攻击和数据泄露事件的增多,Web 安全性将成为前端开发的重要考虑因素。前端开发者需要了解如何保护用户数据,如何防止跨站脚本(XSS)攻击,跨站请求伪造(CSRF)等。
|
||||
|
||||
### 可访问性和包容性
|
||||
|
||||
在未来,可访问性和包容性可能会成为前端开发的更重要的考虑因素。这意味着创建的网站和应用需要对所有人开放,无论他们的能力如何。这包括对于屏幕阅读器友好的设计,对于不同的输入方法(例如语音输入)的支持,以及对于不同文化和语言的考虑。
|
||||
@ -1,96 +0,0 @@
|
||||
---
|
||||
title: 现代化开发工具链
|
||||
description: 前端现代化开发工具链
|
||||
keywords:
|
||||
- 前端开发
|
||||
- 工具
|
||||
tags:
|
||||
- FullStack/文化
|
||||
sidebar_position: 3
|
||||
author: 7Wate
|
||||
date: 2023-10-16
|
||||
---
|
||||
|
||||
在前端开发过程中,开发者需要利用一系列的工具和技术来提高工作效率、确保代码质量和进行项目管理。这些工具和技术构成了前端的开发工具链。以下是一些现代前端开发中常用的工具和技术:
|
||||
|
||||
## 版本控制:Git + GitFlow、Pull Request
|
||||
|
||||
[Git](https://git-scm.com/) 是一个开源的分布式版本控制系统,用于跟踪和记录项目文件的更改历史。[GitHub](https://github.com/) 是一个基于 Git 的代码托管平台, 提供了代码审查、项目管理、版本控制等功能。使用 GitFlow 可以实现更规范的分支管理,Pull Request 允许代码审查,是团队协作的重要方式。
|
||||
|
||||
## 包管理器:npm、yarn 和 Pnpm
|
||||
|
||||
包管理器用于自动处理项目的依赖关系。[npm](https://www.npmjs.com/)(Node Package Manager) 是 Node.js 的默认包管理器,[yarn](https://yarnpkg.com/) 由 Facebook 开发,提供更快速度。[pnpm](https://pnpm.io/) 结合了两者优点,也越来越受欢迎。
|
||||
|
||||
## 代码编辑器:VS Code
|
||||
|
||||
[VS Code](https://code.visualstudio.com/)(Visual Studio Code)是 Microsoft 开发的一个开源代码编辑器。VS Code 提供了语法高亮、智能代码补全、代码重构等功能,并支持大量的插件,如 ESLint、Prettier 等。
|
||||
|
||||
## 模块打包器:Webpack 和 Vite
|
||||
|
||||
[Webpack](https://webpack.js.org/) 是一个模块打包器,支持代码分割、懒加载等。[Vite](https://vitejs.dev/) 通过原生 ES module 实现极速开发服务器启动,能够显著提升开发效率。
|
||||
|
||||
## 代码转译器:Babel
|
||||
|
||||
[Babel](https://babeljs.io/) 是一个 JavaScript 编译器,可以将最新版的 JavaScript 代码转译成旧版的代码,以便在老版本的浏览器中运行。Babel 支持 ES6、React JSX 语法、TypeScript 等。
|
||||
|
||||
## 代码检查器:ESLint 和 Prettier
|
||||
|
||||
[ESLint](https://eslint.org/) 是一个开源的 JavaScript 代码检查工具,可以检查代码中的错误和不符合规范的编码风格。[Prettier](https://prettier.io/) 是一个代码格式化工具,可以自动格式化代码,确保代码的一致性。
|
||||
|
||||
## 测试框架:Jest 和 Mocha
|
||||
|
||||
[Jest](https://jestjs.io/) 是 Facebook 开发的一个 JavaScript 测试框架,支持模拟测试、快照测试等。[Mocha](https://mochajs.org/) 是另一种流行的 JavaScript 测试框架,可以搭配 [Chai](https://www.chaijs.com/)(断言库)和 [Sinon](https://sinonjs.org/)(测试替身库)等工具使用。
|
||||
|
||||
## 前端框架:React、Vue 和 Angular
|
||||
|
||||
[React](https://reactjs.org/)、[Vue](https://vuejs.org/) 和 [Angular](https://angular.io/) 是目前最流行的前端框架,它们提供了组件化、声明式编程等高级特性,用于构建复杂的单页应用(SPA)。
|
||||
|
||||
## CSS 预处理器:Sass、CSS Modules
|
||||
|
||||
[Sass](https://sass-lang.com/) 是一种强大的 CSS 预处理器,允许使用变量、嵌套规则、混合等功能,以写出更干净、更易于维护的 CSS 代码。[CSS Modules](https://github.com/css-modules/css-modules) 是一种 CSS 模块化方案,可以实现 CSS 的局部作用域,避免样式冲突。
|
||||
|
||||
## 结构化数据:GraphQL 和 REST API
|
||||
|
||||
[GraphQL](https://graphql.org/) 是 Facebook 推出的一种数据查询和操作语言,可以让客户端精确地获取需要的数据,提高数据传输效率。REST API 是网络应用程序中最常用的 API 架构风格,它利用 HTTP 协议提供 CRUD(创建、读取、更新、删除)操作。
|
||||
|
||||
## 状态管理:Redux、Vuex 和 MobX
|
||||
|
||||
[Redux](https://redux.js.org/)(用于 React)和 [Vuex](https://vuex.vuejs.org/)(用于 Vue)都是前端状态管理工具,用于管理和维护组件间共享的状态。[MobX](https://mobx.js.org/README.html) 是另一种流行的状态管理库,它使用响应式编程概念,让状态管理更加直观。
|
||||
|
||||
## 静态类型检查器:TypeScript
|
||||
|
||||
[TypeScript](https://www.typescriptlang.org/) 是 JavaScript 的一个超集,它添加了静态类型检查和其他特性,可以提高代码的可维护性和可靠性。
|
||||
|
||||
## 服务器端渲染(SSR)和静态站点生成(SSG):Next.js 和 Nuxt.js
|
||||
|
||||
[Next.js](https://nextjs.org/)(用于 React)和 [Nuxt.js](https://nuxtjs.org/)(用于 Vue)是用于构建服务器端渲染(SSR)和静态站点生成(SSG)的框架,可以提高首屏加载速度,优化 SEO。
|
||||
|
||||
以上就是现代化前端开发工具链的概述,这些工具和技术可以提高开发效率,保证代码质量,使得前端开发更具生产力。
|
||||
|
||||
## 端到端测试:Cypress 和 Puppeteer
|
||||
|
||||
[Cypress](https://www.cypress.io/) 和 [Puppeteer](https://pptr.dev/) 是用于进行端到端测试的工具,允许开发者模拟用户的行为,检查页面的响应,确保应用在真实使用场景中的表现。
|
||||
|
||||
## 开发环境:Docker
|
||||
|
||||
[Docker](https://www.docker.com/) 是一种开源的容器平台,可以用于打包和运行应用,确保应用在不同环境中的一致性。使用 Docker 可以避免“在我机器上可以运行”的问题。
|
||||
|
||||
## 持续集成/持续部署(CI/CD):GitHub Actions 和 Jenkins
|
||||
|
||||
[GitHub Actions](https://github.com/features/actions) 和 [Jenkins](https://www.jenkins.io/) 是用于持续集成和持续部署的工具,可以自动化构建、测试和部署的过程,提高开发效率和代码质量。
|
||||
|
||||
## 性能优化:Lighthouse 和 Webpack Bundle Analyzer
|
||||
|
||||
[Lighthouse](https://developers.google.com/web/tools/lighthouse) 是一种开源工具,可以对网页进行性能、可访问性、最佳实践、SEO 等方面的评估。[Webpack Bundle Analyzer](https://www.npmjs.com/package/webpack-bundle-analyzer) 是一个插件,可以帮助开发者理解 webpack 打包的输出文件,找出优化的机会。
|
||||
|
||||
## API Mocking:Mirage JS 和 Json-server
|
||||
|
||||
[json-server](https://github.com/typicode/json-server) 和 [Mirage JS](https://miragejs.com/) 可以用于生成模拟的 RESTful API,帮助前端开发者在后端 API 还没准备好的情况下进行开发和测试。
|
||||
|
||||
## 设计工具和 UI 组件库:Sketch、Figma、Ant Design 和 Material-UI
|
||||
|
||||
[Sketch](https://www.sketch.com/) 和 [Figma](https://www.figma.com/) 是用于设计 UI 的工具,可以创建和分享设计原型。[Ant Design](https://ant.design/) 和 [Material-UI](https://material-ui.com/) 是 UI 组件库,提供了一系列预定义的 UI 组件,可以快速构建美观的界面。
|
||||
|
||||
## 调试工具:DevTools、VS Code 调试
|
||||
|
||||
[Chrome DevTools](https://developer.chrome.com/docs/devtools/) 和 VS Code 的调试功能用于前端代码调试。
|
||||
@ -7,8 +7,8 @@ keywords:
|
||||
- 磁盘
|
||||
- 文件系统
|
||||
tags:
|
||||
- Linux/进阶
|
||||
- 技术/操作系统
|
||||
- Linux/存储管理
|
||||
author: 7Wate
|
||||
date: 2023-04-10
|
||||
---
|
||||
|
||||
505
Technology/OperatingSystem/Linux/7.存储管理/fio 存储性能测试.md
Normal file
505
Technology/OperatingSystem/Linux/7.存储管理/fio 存储性能测试.md
Normal file
@ -0,0 +1,505 @@
|
||||
---
|
||||
title: fio 存储性能测试
|
||||
description: Fio 是一款灵活的 I/O 测试工具,用于模拟不同工作负载下存储设备的性能。它支持多种 I/O 模式、并发任务和配置选项,适用于基准测试、故障排查和存储设备选型。
|
||||
keywords:
|
||||
- fio
|
||||
- 存储性能测试
|
||||
- I/O 测试
|
||||
- 模拟工作负载
|
||||
- 基准测试
|
||||
tags:
|
||||
- 技术/操作系统
|
||||
- Linux/存储管理
|
||||
author: 仲平
|
||||
date: 2024-09-10
|
||||
---
|
||||
|
||||
## Fio 概述
|
||||
|
||||
### Fio 是什么
|
||||
|
||||
**`fio`(Flexible I/O Tester)是一款用于生成磁盘 I/O 测试负载的工具,广泛用于存储设备的性能测试和分析。**`fio` 支持多种 I/O 模式、并发任务以及灵活的配置选项,可以模拟实际工作负载下的磁盘 I/O 行为,因此在存储系统的基准测试、故障排查、存储设备选型等场景中被广泛应用。
|
||||
|
||||
1. **存储设备性能测试**:`fio` 可以通过模拟不同的 I/O 模式,如顺序读写、随机读写等,来评估存储设备在各种工作负载下的性能表现。它支持在固态硬盘(SSD)、机械硬盘(HDD)、NVMe 等存储介质上进行测试,从而帮助用户了解这些设备在不同 I/O 压力下的吞吐量、延迟和 IOPS(每秒输入输出操作数)。
|
||||
|
||||
2. **模拟实际工作负载**:在生产环境中,存储设备通常面对复杂的混合读写请求,`fio` 可以通过配置多线程、多任务以及读写比例来模拟真实的工作负载。例如,数据库服务器的 I/O 通常以随机读为主,而备份系统则更多地依赖顺序写。`fio` 能够灵活配置任务,以精确模拟不同应用场景下的 I/O 行为。
|
||||
|
||||
3. **测试不同 I/O 模型的性能**:`fio` 支持多种 I/O 引擎(如 `sync`、`libaio`、`io_uring` 等),用户可以通过调整不同的 I/O 模型来测试系统的最大 I/O 能力。同步 I/O 更适合简单的 I/O 操作场景,而异步 I/O 则能在多任务或高并发负载下提供更高的性能。
|
||||
4. **支持并发、多任务处理**:`fio` 提供了非常强大的并发处理能力,可以通过设置 `numjobs` 参数来控制并发的任务数量,从而模拟不同的并发场景。此外,通过调整 `iodepth` 参数,可以控制异步 I/O 请求的深度,进一步增强并发能力。
|
||||
5. **丰富的可配置选项**:`fio` 提供了大量灵活的配置参数,用户可以通过自定义配置文件或命令行参数来控制测试的具体行为。可以指定块大小(`bs`)、I/O 深度(`iodepth`)、读写比例(`rwmixread`)等详细参数。此外,`fio` 还支持多种输出格式,如 JSON、CSV,以便于集成到监控系统中进行结果分析。
|
||||
|
||||
> fio was written by Jens Axboe [axboe@kernel.dk](mailto:axboe@kernel.dk) to enable flexible testing of the Linux I/O subsystem and schedulers. He got tired of writing specific test applications to simulate a given workload, and found that the existing I/O benchmark/test tools out there weren’t flexible enough to do what he wanted.
|
||||
>
|
||||
> Jens Axboe [axboe@kernel.dk](mailto:axboe@kernel.dk) 20060905
|
||||
|
||||
### Fio 安装方法
|
||||
|
||||
`fio` 支持多种操作系统,包括主流的 Linux、macOS 和 Windows 平台。在不同的操作系统上安装 `fio` 具有一些小的差异,用户可以选择合适的安装方式。目前 fio 已经集成在各大 Linux 发行版中,可以自行安装或参考 [官方手册](https://fio.readthedocs.io/en/latest/fio_doc.html#binary-packages)。
|
||||
|
||||
#### 支持的平台
|
||||
|
||||
- **Linux**:Linux 是 `fio` 最常用的平台,在各大 Linux 发行版(如 Ubuntu、CentOS、Debian 等)上,`fio` 都有对应的预编译包。
|
||||
- **macOS**:`fio` 也支持在 macOS 上安装,可以通过 Homebrew 等包管理工具安装。
|
||||
- **Windows**:在 Windows 环境下,`fio` 支持原生的 Windows 文件系统,并可以通过 Cygwin 或 Windows Subsystem for Linux (WSL) 运行。
|
||||
|
||||
### Fio 基本原理
|
||||
|
||||
`fio` 是一个高度灵活的工具,它的核心原理是通过模拟不同的 I/O 模式来生成实际负载,从而测试存储设备的性能。了解 `fio` 的 I/O 模型和工作负载模拟原理,能够帮助用户更好地配置测试场景。
|
||||
|
||||
#### I/O 模型
|
||||
|
||||
**在 `fio` 中,I/O 模型分为两类:同步 I/O 和异步 I/O。**
|
||||
|
||||
1. **同步 I/O:** 同步 I/O 模型是指每个 I/O 操作在完成之前,发起 I/O 请求的线程会被阻塞,直到 I/O 操作完成后才会继续进行后续操作。这种模型通常用于低并发场景或 I/O 请求较少的工作负载。例如,在单线程的顺序读写测试中,使用同步 I/O 可以更直接地反映存储设备的顺序访问性能。
|
||||
|
||||
2. **异步 I/O:** 异步 I/O 模型允许多个 I/O 请求同时进行。发起 I/O 请求后,线程不需要等待当前 I/O 操作完成,而是可以继续发起其他请求,这大大提高了并发能力。异步 I/O 更适合高并发、大量随机访问的场景,比如服务器上并发处理多个数据库查询请求时,异步 I/O 能显著提升处理效率。常用的异步 I/O 引擎包括 `libaio` 和 `io_uring`。
|
||||
|
||||
`fio` 支持多种 I/O 引擎,它们决定了 I/O 操作的执行方式,不同的 I/O 引擎在性能和应用场景上有很大区别。选择合适的 I/O 引擎可以帮助用户更精准地模拟特定的负载场景。
|
||||
|
||||
| I/O 引擎 | 特点 |
|
||||
| -------- | ------------------------------------------------------------ |
|
||||
| sync | 同步 I/O 引擎,所有 I/O 操作在返回前都会被阻塞,适合简单的顺序读写操作。适合对吞吐量敏感的场景。 |
|
||||
| libaio | Linux 异步 I/O 引擎,允许多个 I/O 请求并行执行,不需等待前一个操作完成。适合高并发、高性能存储设备。 |
|
||||
| mmap | 通过内存映射实现的 I/O 操作,适合对文件的大块连续读写场景。 |
|
||||
| io_uring | Linux 新引入的高性能异步 I/O 模型,提供了更低的系统开销和更高的 I/O 性能。特别适用于 NVMe 等高性能存储设备。 |
|
||||
|
||||
### Fio 如何模拟工作负载
|
||||
|
||||
**`fio` 通过创建多个线程或进程来模拟多任务并发的 I/O 请求。** 每个任务可以独立配置它的 I/O 模型、读写模式、块大小等,从而能够精确地模拟出不同应用程序的 I/O 行为。例如,可以同时配置一个任务进行顺序写操作,另一个任务进行随机读操作,达到模拟数据库写操作和备份操作并行执行的效果。
|
||||
|
||||
### Fio Job 的基本组成
|
||||
|
||||
一个 `fio` 的 job(任务)是测试的核心,它通常由以下几个部分组成:
|
||||
|
||||
1. **任务配置**:每个任务可以独立配置 I/O 模型、读写模式等。例如,可以配置多个 job 并发运行以模拟真实环境中的多线程负载。
|
||||
2. **文件配置**:文件配置指的是 `fio` 要对哪个文件或设备进行读写操作。可以是具体的文件路径,也可以是块设备,如 `/dev/sda`。
|
||||
3. **进程/线程控制**:`fio` 可以通过 `numjobs` 参数创建多个并发任务,并通过 `thread` 参数决定任务是以线程还是进程的形式运行。
|
||||
|
||||
## Fio 基本操作
|
||||
|
||||
### Fio 基础命令
|
||||
|
||||
`fio` 支持两种方式运行:**命令行模式和配置文件模式。** 这两种方式提供了不同的灵活性和适用场景:
|
||||
|
||||
- **命令行模式**:在命令行中直接指定测试参数和选项。这种方式更适合简单、快速的测试场景。命令行模式提供的参数直接跟随 `fio` 命令。例如:
|
||||
|
||||
```shell
|
||||
fio --name=test --rw=randread --size=1G --bs=4k --ioengine=libaio --numjobs=4 --iodepth=64
|
||||
```
|
||||
|
||||
- **配置文件模式**:将所有的测试选项写入一个配置文件,然后通过 `fio` 执行该配置文件。这种模式适合复杂的多任务、多文件的测试场景,尤其在需要复现特定的工作负载时非常有用。例如,用户可以在配置文件中定义多个任务,指定不同的读写模式、块大小和 I/O 引擎等。使用方式如下:
|
||||
|
||||
```shell
|
||||
fio mytest.fio
|
||||
```
|
||||
|
||||
配置文件的内容可以非常复杂,允许用户指定多个任务和设备。
|
||||
|
||||
#### **基本语法和参数介绍**
|
||||
|
||||
在命令行模式中,`fio` 的基本命令结构如下:
|
||||
|
||||
```shell
|
||||
fio [全局参数] --name=任务名 [任务参数]
|
||||
```
|
||||
|
||||
**全局参数**:影响所有任务的运行行为,如日志输出格式。
|
||||
|
||||
**任务参数**:每个任务可以独立配置,如 I/O 模式、块大小等。常用参数包括 `rw`、`bs`、`size`、`numjobs` 等。
|
||||
|
||||
#### **简单 I/O 测试实例**
|
||||
|
||||
通过简单的 `fio` 命令,可以执行读写操作并测试设备性能。以下是一些常见的测试场景:
|
||||
|
||||
```shell
|
||||
# 在默认路径生成一个 1GB 的文件,并进行顺序写操作,块大小为 1MB。
|
||||
fio --name=seqwrite --rw=write --size=1G --bs=1M --ioengine=sync
|
||||
|
||||
# 随机读操作,块大小为 4KB,使用异步 I/O 引擎并设置 I/O 深度为 64。
|
||||
fio --name=randread --rw=randread --size=1G --bs=4k --ioengine=libaio --iodepth=64
|
||||
```
|
||||
|
||||
#### **使用 `--output` 参数保存输出结果**
|
||||
|
||||
`fio` 支持将测试结果保存到指定的文件中,这对于长时间或复杂的测试尤为重要。可以通过 `--output` 参数将输出保存到文件:
|
||||
|
||||
```shell
|
||||
fio --name=test --rw=randwrite --size=1G --bs=4k --output=result.txt
|
||||
```
|
||||
|
||||
### Fio 常用参数
|
||||
|
||||
| 参数 | 描述 | 常用选项 | 示例命令 |
|
||||
| ----------- | ------------------------------------------------------------ | -------------------------------------------------- | ------------------------------------------------------------ |
|
||||
| `rw` | 定义 I/O 操作类型,包括顺序读 (`read`)、顺序写 (`write`)、随机读 (`randread`)、随机写 (`randwrite`)、混合读写 (`randrw`)。 | `read`, `write`, `randread`, `randwrite`, `randrw` | `fio --name=test --rw=randread --size=1G --bs=4k` |
|
||||
| `bs` | 块大小,指定每次 I/O 操作的块大小,影响 IOPS 和带宽。小块大小适合 IOPS,大块适合带宽测试。 | `4k`, `8k`, `1M` | `fio --name=test --rw=write --bs=1M --size=1G` |
|
||||
| `size` | 测试文件的大小,定义测试过程中传输的数据总量。 | `1G`, `2G`, `10G` | `fio --name=test --rw=write --size=2G` |
|
||||
| `ioengine` | 选择不同的 I/O 引擎,如同步 (`sync`)、异步 (`libaio`)、`io_uring`。 | `sync`, `libaio`, `io_uring` | `fio --name=test --rw=randread --ioengine=libaio --iodepth=64` |
|
||||
| `numjobs` | 设置并发任务数,增加并发负载,模拟多线程或多进程环境下的 I/O。 | `1`, `4`, `8`, `16` | `fio --name=test --rw=randwrite --numjobs=4` |
|
||||
| `iodepth` | 控制异步 I/O 请求的队列深度,适用于 `libaio` 和 `io_uring` 等异步 I/O 模型。 | `32`, `64`, `128` | `fio --name=test --rw=randread --ioengine=libaio --iodepth=64` |
|
||||
| `thread` | 控制任务以线程模式执行,适合轻量级并发场景。 | `thread`, `process` | `fio --name=test --rw=randread --numjobs=4 --thread` |
|
||||
| `rwmixread` | 在混合读写测试中,控制读写比例,如 70% 读,30% 写。 | `50`, `70`, `80` | `fio --name=test --rw=randrw --rwmixread=70 --size=1G --bs=4k` |
|
||||
| `rate` | 限制每秒的传输字节数,适用于带宽受限的场景。 | `10m`, `100m`, `1g` | `fio --name=test --rw=randwrite --size=1G --rate=10m` |
|
||||
| `rate_iops` | 限制每秒的 I/O 操作次数(IOPS)。 | `100`, `500`, `1000` | `fio --name=test --rw=randwrite --rate_iops=100` |
|
||||
| `verify` | 数据一致性校验,确保写入数据能正确读回,常用模式如 `md5`、`crc32`。 | `md5`, `crc32` | `fio --name=test --rw=randwrite --verify=md5 --size=1G` |
|
||||
|
||||
### Fio 文件配置
|
||||
|
||||
**`fio` 文件配置为管理复杂的 I/O 测试场景提供了极大的灵活性。** 通过配置文件,用户可以定义多个并发任务,指定不同的 I/O 模式、块大小、I/O 引擎以及存储目标。每个测试任务的参数可以独立配置,适合多任务并发运行或复杂负载的测试需求。
|
||||
|
||||
**`fio` 配置文件使用 `.fio` 后缀,文件结构类似于 `ini` 格式,每个任务用 `[jobname]` 进行定义,后面跟随具体的参数配置。**配置文件可以包含全局设置以及单独任务的定义,适合测试复杂的场景,如多任务、多设备的并发 I/O 测试。
|
||||
|
||||
#### 配置文件结构示例
|
||||
|
||||
```ini
|
||||
[global]
|
||||
ioengine=libaio
|
||||
size=1G
|
||||
bs=4k
|
||||
|
||||
[readtest]
|
||||
rw=randread
|
||||
iodepth=32
|
||||
|
||||
[writetest]
|
||||
rw=randwrite
|
||||
iodepth=64
|
||||
```
|
||||
|
||||
- **[global]**:全局配置部分,适用于所有任务,例如 `ioengine=libaio` 设置 I/O 引擎为异步模式,`size=1G` 设置测试文件大小为 1GB,`bs=4k` 设置块大小为 4KB。
|
||||
- **[readtest]**:定义了一个随机读测试任务,`iodepth=32` 表示该任务的 I/O 队列深度为 32。
|
||||
- **[writetest]**:定义了一个随机写测试任务,`iodepth=64` 表示该任务的 I/O 队列深度为 64。
|
||||
|
||||
#### **使用 `filename` 参数定义测试文件**
|
||||
|
||||
`filename` 参数用于指定测试使用的文件或块设备。可以是具体的文件路径,也可以是裸设备(如 `/dev/sda`)。这使得 `fio` 不仅可以在文件系统层面测试,还可以直接测试块设备的 I/O 性能。
|
||||
|
||||
```shell
|
||||
fio --name=test --rw=write --size=1G --filename=/dev/sda
|
||||
```
|
||||
|
||||
- **临时文件**:在文件系统上创建的文件用于测试,适合测试文件系统的性能。
|
||||
- **裸设备**:直接在块设备上运行测试,适合测试硬盘或存储设备的底层性能,避免文件系统的缓存影响。
|
||||
|
||||
#### **多文件和目录的 I/O 测试**
|
||||
|
||||
`fio` 支持在多个文件或目录上并发运行测试任务。可以使用通配符或明确指定多个文件进行测试。
|
||||
|
||||
```shell
|
||||
fio --name=test --rw=randread --filename=/mnt/data/testfile[1-4]
|
||||
```
|
||||
|
||||
使用 `fio` 配置文件,可以管理复杂的测试场景。配置文件结构清晰,能够定义多个并发任务、不同的 I/O 模式以及特定的存储目标。
|
||||
|
||||
`fio` 配置文件使用 `.fio` 作为后缀,文件内部的结构类似于 ini 格式。每个任务通过 `[jobname]` 定义,任务的详细参数在后续逐行配置。例如:
|
||||
|
||||
```ini
|
||||
[global]
|
||||
ioengine=libaio
|
||||
size=1G
|
||||
bs=4k
|
||||
|
||||
[readtest]
|
||||
rw=randread
|
||||
iodepth=32
|
||||
|
||||
[writetest]
|
||||
rw=randwrite
|
||||
iodepth=64
|
||||
```
|
||||
|
||||
该配置文件定义了两个任务 `readtest` 和 `writetest`,分别进行随机读和随机写操作。
|
||||
|
||||
### Fio 日志报告
|
||||
|
||||
`fio` 提供了方便的输出报告功能,可以将测试结果保存到日志文件中,便于后续分析、共享和归档。通过 `--output` 参数指定输出文件,可以轻松生成测试报告:
|
||||
|
||||
```shell
|
||||
fio --name=test --rw=randread --size=1G --output=result.txt
|
||||
```
|
||||
|
||||
#### 标准输出解析
|
||||
|
||||
| 术语 | 描述 | 适用场景 | 单位 |
|
||||
| ---------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ---------------------- |
|
||||
| **IOPS** | 每秒输入输出操作数,用于衡量设备在单位时间内处理的 I/O 请求数量。特别适合小块随机 I/O 的性能评估。 | 高并发场景,如数据库、虚拟化系统中小块 I/O 性能的评估。 | IOPS(每秒请求数) |
|
||||
| **带宽(Bandwidth)** | 表示单位时间内的数据传输量,评估大块顺序 I/O 性能。 | 适合大文件传输、顺序读写的场景,如流媒体、备份等需要大量连续数据传输的场景。 | MB/s 或 GB/s |
|
||||
| **延迟(Latency)** | 每个 I/O 操作从发出到响应完成的时间。延迟越低,系统响应越快,适合高并发和实时性要求高的应用。 | 高性能存储需求场景,如数据库、交易系统、实时应用。 | 微秒(µs)或毫秒(ms) |
|
||||
| **完成时间(Completion Time)** | 表示单个测试任务完成所需的总时间。这可以用于评估整体性能表现。 | 测试持续时间较长的 I/O 操作,如备份和归档。 | 秒(s) |
|
||||
| **CPU 使用率(CPU Utilization)** | 指测试期间系统的 CPU 占用情况,反映 I/O 操作对 CPU 资源的消耗。 | 用于衡量存储设备和系统的 CPU 整体利用效率,特别是在高并发或高负载场景中有助于确定 CPU 资源是否成为瓶颈。 | 百分比(%) |
|
||||
| **队列深度(Queue Depth)** | 反映测试期间并发处理的 I/O 请求数量,尤其是异步 I/O 操作中。队列深度较大时,系统可以更高效地并行处理 I/O 请求。 | 适合异步 I/O 负载测试场景,如 SSD 和 NVMe 设备的性能优化,帮助评估设备的并行处理能力。 | 无单位 |
|
||||
| **错误率(Error Rate)** | 反映测试过程中发生的错误数量和类型,如 I/O 失败或数据验证失败。确保测试过程中的数据完整性和可靠性。 | 数据可靠性测试和故障排查场景,如验证存储设备的故障检测能力。 | 错误次数 |
|
||||
| **磁盘利用率(Disk Utilization)** | 指存储设备的忙碌程度,反映设备在 I/O 操作中的占用率,通常结合 CPU 利用率来评估系统资源的综合使用情况。 | 用于评估系统和存储设备在高负载下的工作状态,判断系统瓶颈点。 | 百分比(%) |
|
||||
|
||||
#### 日志输出格式
|
||||
|
||||
为了方便数据分析和集成监控系统,`fio` 支持将测试结果输出为标准文本、JSON 或 CSV 格式。用户可以选择最适合的格式来处理和分析测试结果。
|
||||
|
||||
##### JSON 格式
|
||||
|
||||
结构化数据输出,适合与自动化工具和监控系统集成。JSON 输出便于导入诸如 Grafana、Prometheus 等监控工具进行可视化和性能趋势分析。
|
||||
|
||||
```shell
|
||||
fio --name=test --rw=randread --size=1G --output-format=json --output=result.json
|
||||
```
|
||||
|
||||
##### CSV 格式
|
||||
|
||||
CSV 格式适合导入 Excel 或数据分析工具(如 R、Python),便于用户手动分析和生成图表。
|
||||
|
||||
```shell
|
||||
fio --name=test --rw=write --size=1G --output-format=csv --output=result.csv
|
||||
```
|
||||
|
||||
#### 日志间隔与精确数据记录
|
||||
|
||||
| 参数 | 描述 | 示例命令 | 适用场景 |
|
||||
| ----------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------ |
|
||||
| `--log_avg_msec` | 设置时间间隔记录平均性能数据,适用于长时间压力测试,帮助用户观察性能趋势和波动。 | `fio --name=test --rw=randread --size=1G --log_avg_msec=1000 --output=result.txt` | 长时间压力测试,性能趋势观察 |
|
||||
| `--log_hist_msec` | 记录更加精确的 I/O 性能数据,适用于捕捉短时间内的 I/O 波动,帮助分析微观层面上的性能变化。 | `fio --name=test --rw=randwrite --size=1G --log_hist_msec=100 --output=result.txt` | 高精度性能监控,短时间性能分析 |
|
||||
| `--write_iops_log` | 将 IOPS 性能数据记录到日志文件中,用于观察和分析 IOPS 的变化情况,支持长期记录和监控。 | `fio --name=test --rw=randread --size=1G --write_iops_log=iops_log.txt` | IOPS 监控,长期性能观察 |
|
||||
| `--write_bw_log` | 将带宽(Bandwidth)性能数据记录到日志文件中,适合大文件传输、顺序读写的带宽监控与分析。 | `fio --name=test --rw=write --size=1G --write_bw_log=bw_log.txt` | 带宽性能监控,顺序读写分析 |
|
||||
| `--write_lat_log` | 将延迟(Latency)数据记录到日志文件中,帮助分析 I/O 操作的响应时间变化,特别适用于高实时性要求的场景,如数据库和虚拟机。 | `fio --name=test --rw=randwrite --size=1G --write_lat_log=lat_log.txt` | 延迟监控,高实时性应用分析 |
|
||||
| `--write_log` | 同时记录 IOPS、带宽和延迟数据,生成综合日志文件,适合对存储设备的整体性能进行全面监控和记录。 | `fio --name=test --rw=randrw --size=1G --write_log=performance_log.txt` | 综合性能监控,全面性能评估 |
|
||||
| `--log_max_value` | 设置日志记录的最大值,适用于限制日志文件中记录的最大性能数据点,防止异常值导致日志分析数据失真。 | `fio --name=test --rw=write --size=1G --log_max_value=10000` | 限制日志数据范围,去除异常数据 |
|
||||
| `--log_offset` | 为日志文件中的数据设置偏移值,用于对记录数据进行时间上的调整,适合对多次测试进行对比分析时使用。 | `fio --name=test --rw=randread --size=1G --log_offset=1000 --output=result.txt` | 数据对比分析,多次测试分析 |
|
||||
| `--log_unix_epoch` | 记录日志时以 Unix 时间戳(秒级或毫秒级)为基础,适用于将数据集成到其他系统中进行时序分析或对接监控工具。 | `fio --name=test --rw=randwrite --size=1G --log_unix_epoch=1 --output=result.txt` | 时间序列分析,监控系统集成 |
|
||||
| `--write_log_units` | 设置日志文件中记录的数据单位,如 IOPS 的单位可以是 `iops`,带宽可以是 `mbps`,延迟可以是 `ms`。 | `fio --name=test --rw=randread --size=1G --write_log_units=iops,mbps,ms --write_log=unit_log.txt` | 自定义单位日志记录 |
|
||||
| `--log_avg_msec` | 设置记录平均性能数据的时间间隔,用于长时间性能监控。 | `fio --name=test --rw=randwrite --size=1G --log_avg_msec=2000 --output=result.txt` | 长时间压力测试,平均性能分析 |
|
||||
| `--log_hist_coarseness` | 设置记录直方图数据的粒度,适用于需要捕捉细微性能变化的场景。 | `fio --name=test --rw=randread --size=1G --log_hist_coarseness=10 --output=hist_log.txt` | 性能微观分析,细粒度数据监控 |
|
||||
|
||||
## Fio 实际应用案例
|
||||
|
||||
`fio` 是一个高度灵活的存储性能测试工具,广泛应用于不同场景下的 I/O 性能测试。无论是在评估 SSD 和 HDD 性能、分布式存储和网络 I/O 测试,还是模拟数据库负载,`fio` 都能够提供精准的 I/O 负载模拟和详细的性能指标。此外,`fio` 在企业级存储基准测试和大规模存储性能测试中也是必不可少的工具。
|
||||
|
||||
### 在 SSD/HDD 上的测试
|
||||
|
||||
SSD 和 HDD 是两类性能差异较大的存储介质。**SSD 具有更高的随机读写性能和更低的延迟,而 HDD 则更适合大规模顺序读写操作。** 通过 `fio`,可以精确测试这两种设备在不同工作负载下的表现,并对其性能差异进行对比。
|
||||
|
||||
#### SSD 的读写性能测试
|
||||
|
||||
SSD 通常在随机读写操作中表现突出,尤其是 NVMe SSD 通过支持高并发和低延迟的 I/O 操作,能显著提升系统性能。使用 `fio` 测试 SSD 的随机读写性能,可以评估其在高负载场景下的表现。
|
||||
|
||||
```
|
||||
# 测试 NVMe SSD 的随机读写性能,其中 70% 是随机读,30% 是随机写,块大小为 4KB,I/O 深度为 64。
|
||||
fio --name=ssd-test --rw=randrw --rwmixread=70 --bs=4k --size=10G --iodepth=64 --numjobs=4 --filename=/dev/nvme0n1
|
||||
```
|
||||
|
||||
#### 机械硬盘的顺序读写和随机读写性能测试
|
||||
|
||||
机械硬盘(HDD)在顺序读写操作中表现较好,但在随机读写下性能表现较差。`fio` 可以帮助分析 HDD 的顺序和随机 I/O 性能,评估其适用于哪些应用场景。
|
||||
|
||||
```shell
|
||||
# 测试顺序写性能,块大小为 1MB,适合测试 HDD 的带宽和吞吐量。
|
||||
fio --name=hdd-test --rw=write --bs=1M --size=10G --iodepth=32 --filename=/dev/sda
|
||||
|
||||
# 测试 HDD 的随机读性能,适合评估 HDD 在随机访问应用场景中的表现。
|
||||
fio --name=hdd-test --rw=randread --bs=4k --size=10G --iodepth=32 --filename=/dev/sda
|
||||
```
|
||||
|
||||
### **分布式存储和网络 I/O 测试**
|
||||
|
||||
在现代数据中心,分布式存储和网络文件系统被广泛使用,如 Ceph、GlusterFS、NFS 等。`fio` 支持 client/server 模式,可以用于分布式 I/O 测试,评估系统在网络存储环境中的性能表现。
|
||||
|
||||
#### 使用 client/server 模式进行分布式 I/O 测试
|
||||
|
||||
`fio` 的 client/server 模式允许在不同的主机之间进行 I/O 测试,这使得其非常适合分布式存储环境的性能评估。通过在不同节点之间传输数据,可以测试网络延迟、带宽以及多节点间的 I/O 协作能力。
|
||||
|
||||
```shell
|
||||
# 1.服务器端启动并等待客户端连接。
|
||||
fio --server
|
||||
|
||||
# 2.客户端启动测试,客户端连接到远程 `fio` 服务器进行随机写测试。
|
||||
fio --client=server_ip --name=test --rw=randwrite --size=10G --bs=4k
|
||||
```
|
||||
|
||||
#### 网络文件系统(NFS)、分布式存储(Ceph)的测试
|
||||
|
||||
对于分布式文件系统(如 NFS 或 Ceph),可以使用 `fio` 测试其性能,模拟多个客户端同时访问共享存储的场景。
|
||||
|
||||
```shell
|
||||
# 在挂载的 NFS 目录中执行随机写测试,用于评估 NFS 在并发访问下的性能表现。
|
||||
fio --name=nfs-test --rw=randwrite --size=10G --bs=4k --directory=/mnt/nfs
|
||||
|
||||
# 在 Ceph 文件系统中执行多任务随机读测试,评估其在高并发情况下的读写能力。
|
||||
fio --name=ceph-test --rw=randread --size=10G --bs=4k --numjobs=8 --filename=/mnt/ceph
|
||||
```
|
||||
|
||||
### **模拟数据库负载**
|
||||
|
||||
数据库应用的 I/O 负载通常表现为高并发、小块的随机读写操作。通过 `fio`,可以模拟数据库的典型 I/O 模型,测试存储设备在类似数据库工作负载下的性能。
|
||||
|
||||
数据库负载往往以 4KB 的小块随机读写为主,`fio` 可以通过设置 `bs=4k` 和高并发来精确模拟这种工作负载。
|
||||
|
||||
```shell
|
||||
# 模拟 70% 随机读和 30% 随机写的混合操作,块大小为 4KB,16 个并发任务和较高的 I/O 深度,能够逼真地模拟数据库环境中的高负载。
|
||||
fio --name=db-test --rw=randrw --rwmixread=70 --bs=4k --size=10G --numjobs=16 --iodepth=64
|
||||
```
|
||||
|
||||
为了进一步优化数据库工作负载的性能,通常需要对块大小和 I/O 深度进行调整:
|
||||
|
||||
- **块大小**:数据库通常使用较小的块大小(如 4KB),以优化随机读写性能。较大的块大小适合顺序操作或批量数据处理,但对数据库负载可能不利。
|
||||
- **I/O 深度**:增加 I/O 深度(`iodepth`)可以提高系统的并发处理能力,尤其是对于 NVMe SSD 等高性能存储设备,合适的 `iodepth` 可以极大提升系统 IOPS。
|
||||
|
||||
### **企业级应用场景**
|
||||
|
||||
在企业环境中,`fio` 被广泛用于存储设备的基准测试、压力测试和性能验证。通过 `fio` 的灵活配置,用户可以评估存储系统在不同负载下的表现,并预测系统在实际生产环境中的稳定性和响应能力。
|
||||
|
||||
#### **使用 Fio 进行存储设备的基准测试和验证**
|
||||
|
||||
基准测试是存储设备选型和性能优化的重要手段。`fio` 能够模拟各种典型的应用场景,帮助企业对比不同存储设备的性能表现。
|
||||
|
||||
```shell
|
||||
# 对设备进行顺序读基准测试,块大小为 1MB,适合评估设备的最大带宽。
|
||||
fio --name=baseline --rw=read --bs=1M --size=10G --iodepth=32 --filename=/dev/sda
|
||||
```
|
||||
|
||||
#### **大规模存储设备的 I/O 性能测试与压力测试**
|
||||
|
||||
在大规模存储系统(如 SAN、NAS)中,压力测试用于评估系统在长时间高负载条件下的性能稳定性。通过增加并发任务和 I/O 负载,`fio` 能够模拟生产环境中极端的使用场景,帮助企业发现存储系统的性能瓶颈。
|
||||
|
||||
```shell
|
||||
# 在 24 小时内对存储设备进行随机读写压力测试,64 个并发任务和较高的 I/O 深度能够逼真模拟企业生产环境下的高负载工作场景。
|
||||
fio --name=stress --rw=randrw --bs=4k --size=100G --numjobs=64 --iodepth=128 --runtime=24h --time_based
|
||||
```
|
||||
|
||||
## Fio 性能优化与故障排查
|
||||
|
||||
### 性能调优技巧
|
||||
|
||||
#### **使用 `numjobs` 增加并发性**
|
||||
|
||||
`numjobs` 参数是 `fio` 中控制并发性的重要工具。它用于定义并行执行的任务数量,适合模拟多线程或多任务环境下的 I/O 负载。例如,在测试数据库或虚拟化环境中,可以通过增加并发任务数量来模拟实际应用中高负载下的存储访问行为。
|
||||
|
||||
- **调优场景**:
|
||||
|
||||
- 如果存储设备支持并发 I/O,那么通过增加 `numjobs` 可以有效提升设备的吞吐量和 IOPS,尤其是在 NVMe SSD 等高性能存储设备上。
|
||||
|
||||
- **示例**:
|
||||
|
||||
```shell
|
||||
fio --name=test --rw=randread --size=1G --bs=4k --numjobs=8
|
||||
```
|
||||
|
||||
在该命令中,`numjobs=8` 表示将启动 8 个并发任务进行随机读操作。较高的并发性适合测试系统在高负载条件下的 I/O 性能。
|
||||
|
||||
#### **调整 `iodepth` 优化异步性能**
|
||||
|
||||
`iodepth` 参数定义了在异步 I/O 模式下(如 `libaio` 或 `io_uring`),队列中允许同时存在的最大 I/O 请求数。更高的 `iodepth` 值可以提升并发能力,但如果系统资源有限,过高的 `iodepth` 可能会导致队列过长,增加延迟。通过合理调整 `iodepth`,可以找到设备的最佳异步性能点。
|
||||
|
||||
- **调优场景**:
|
||||
|
||||
- 在高性能 SSD 或 NVMe 设备上,较大的 `iodepth` 可以提高设备的 IOPS 和吞吐量。
|
||||
- 对于 HDD 或 SATA SSD,过高的 `iodepth` 可能会因为硬件瓶颈导致性能下降或延迟增加。
|
||||
|
||||
- **示例**:
|
||||
|
||||
```shell
|
||||
fio --name=test --rw=randwrite --size=1G --ioengine=libaio --iodepth=64
|
||||
```
|
||||
|
||||
该命令中,`iodepth=64` 表示同时进行 64 个异步 I/O 操作,适合高并发场景。
|
||||
|
||||
#### **针对 IOPS、带宽、延迟等不同目标进行针对性优化**
|
||||
|
||||
根据不同的测试目标,`fio` 可以通过以下参数进行针对性优化:
|
||||
|
||||
- **优化 IOPS**:为小块随机读写的场景调优。通过增加并发任务数(`numjobs`)和适度提高 `iodepth`,可以有效提高 IOPS。合适的块大小(`bs`)对 IOPS 影响极大,通常 4KB 是优化 IOPS 的标准选择。
|
||||
|
||||
```shell
|
||||
fio --name=io_test --rw=randread --bs=4k --size=10G --numjobs=16 --iodepth=32
|
||||
```
|
||||
|
||||
- **优化带宽**:适用于大块顺序读写操作。通过增大块大小(`bs=1M` 或更大),可以提高数据传输速率,最大化设备的带宽性能。
|
||||
|
||||
```shell
|
||||
fio --name=bw_test --rw=write --bs=1M --size=10G
|
||||
```
|
||||
|
||||
- **优化延迟**:适用于实时性要求较高的场景。需要控制 `iodepth` 和 `numjobs`,避免过多的并发和过深的队列,保证 I/O 请求尽快被处理。
|
||||
|
||||
```shell
|
||||
fio --name=latency_test --rw=randread --bs=4k --size=1G --iodepth=4
|
||||
```
|
||||
|
||||
### Fio 常见问题与排错
|
||||
|
||||
在使用 `fio` 进行测试时,可能会遇到一些错误和性能问题。了解 `fio` 输出日志中的错误信息,并通过正确的调试工具和方法进行排错,是测试工作顺利进行的保障。
|
||||
|
||||
#### **如何分析和解决 Fio 报错**
|
||||
|
||||
- **常见报错**:
|
||||
- **文件系统/块设备权限问题**:执行测试时,确保 `fio` 对测试文件或设备有写入权限。可以通过 `chmod` 或 `chown` 修改文件权限。
|
||||
- **参数配置冲突**:有些参数不能同时使用,如指定 `rw=randread` 时不应再设定 `verify` 参数。解决方案是根据报错提示,调整相应的参数配置。
|
||||
- **分析报错日志**: 当 `fio` 报错时,日志中会包含详细的错误信息。通过阅读 `fio` 输出的错误消息,可以准确定位到导致错误的参数或系统配置。例如,如果在测试期间设备无法响应,报错信息可能会显示 "I/O error"。
|
||||
- **解决方法**:
|
||||
- 检查并确保所有的设备路径正确。
|
||||
- 检查设备的挂载状态和可写权限。
|
||||
- 根据错误日志,调整 `fio` 的配置或系统资源分配。
|
||||
|
||||
#### **系统资源(CPU、内存、磁盘)的使用情况监控**
|
||||
|
||||
`fio` 运行时对系统资源的占用情况(如 CPU 和内存)可能会影响测试结果,因此监控系统资源使用至关重要。可以使用以下工具来监控测试过程中系统的资源使用情况:
|
||||
|
||||
- **`top` 或 `htop`**:实时监控 CPU 和内存使用情况,识别系统瓶颈。
|
||||
|
||||
```shell
|
||||
top
|
||||
```
|
||||
|
||||
- **`iostat`**:监控磁盘 I/O 性能,分析磁盘读写速率、设备利用率等。
|
||||
|
||||
```shell
|
||||
iostat -x 1
|
||||
```
|
||||
|
||||
- **`vmstat`**:监控系统的虚拟内存使用情况,帮助识别内存瓶颈。
|
||||
|
||||
```shell
|
||||
vmstat 1
|
||||
```
|
||||
|
||||
通过实时监控系统资源使用,可以识别由于 CPU 或内存不足导致的 I/O 性能瓶颈,并进行相应的优化调整。
|
||||
|
||||
#### **使用 `--debug` 参数进行深度调试**
|
||||
|
||||
`fio` 提供了 `--debug` 参数,用于调试运行过程中的细节。可以通过该参数输出更多调试信息,从而深入了解 `fio` 的内部运行机制,帮助排查一些难以发现的系统问题。
|
||||
|
||||
```shell
|
||||
fio --name=test --rw=randread --size=1G --debug=all
|
||||
```
|
||||
|
||||
此命令会生成详尽的调试信息,涵盖从 I/O 操作到系统调用的详细日志。
|
||||
|
||||
### 性能瓶颈分析与解决方案
|
||||
|
||||
`fio` 测试过程中,存储设备的性能可能受到多种硬件和软件因素的影响。分析 I/O 性能瓶颈,并结合其他系统工具进行深入排查,可以帮助用户识别并解决影响系统性能的根本问题。
|
||||
|
||||
#### **分析不同硬件和软件配置下的 I/O 性能瓶颈**
|
||||
|
||||
存储设备的 I/O 性能瓶颈可以来源于硬件或软件层:
|
||||
|
||||
- **硬件瓶颈**:
|
||||
- **磁盘 I/O 性能不足**:传统 HDD 在处理高并发随机 I/O 时会遇到 IOPS 限制。更换为 SSD 或 NVMe 设备通常能显著提高 IOPS 性能。
|
||||
- **网络带宽受限**:在分布式存储系统中,网络带宽可能成为瓶颈。通过增加网络带宽或使用更高性能的网络接口卡(如 10GbE、25GbE)可以缓解这种瓶颈。
|
||||
- **软件瓶颈**:
|
||||
- **I/O 队列设置不当**:在高并发负载下,如果 I/O 队列深度设置过小,可能会导致设备性能无法充分发挥;如果设置过大,可能会增加延迟,导致系统响应速度变慢。
|
||||
- **文件系统的选择**:不同文件系统(如 ext4、XFS)的性能差异可能影响测试结果。针对特定应用场景,选择合适的文件系统对提高 I/O 性能至关重要。
|
||||
|
||||
#### **使用 Fio 结合其他系统工具(如 `iostat`、`sar`)进行性能分析**
|
||||
|
||||
`fio` 可以与其他性能监控工具结合使用,帮助全面分析系统的 I/O 性能瓶颈:
|
||||
|
||||
- **`iostat`**:`iostat` 提供了磁盘 I/O 的详细信息,包括每个设备的读写速率、平均等待时间、设备利用率等。通过与 `fio` 结合使用,可以监控不同测试条件下磁盘的性能表现。
|
||||
|
||||
```shell
|
||||
iostat -x 1
|
||||
```
|
||||
|
||||
- **`sar`**:`sar` 是一款强大的系统性能分析工具,可以监控系统的 CPU、内存、I/O 性能等多种资源。通过收集长时间的系统数据,用户可以分析系统在不同时间段的性能变化情况。
|
||||
|
||||
```shell
|
||||
sar -d 1
|
||||
```
|
||||
|
||||
通过这些工具,用户可以更好地了解 `fio` 测试时系统的资源使用情况,从而识别和解决性能瓶颈。
|
||||
263
Technology/WebDevelopment/0.Overview/概述.md
Normal file
263
Technology/WebDevelopment/0.Overview/概述.md
Normal file
@ -0,0 +1,263 @@
|
||||
---
|
||||
title: 概述
|
||||
description: 前端开发领域的全面概述,包括其定义、与后端的区别、重要性、历史发展、现代化工具和技术、以及未来发展趋势。
|
||||
keywords:
|
||||
- 前端开发
|
||||
- 客户端
|
||||
- 用户界面
|
||||
- 后端
|
||||
- 技术发展
|
||||
- 工具链
|
||||
- 未来趋势
|
||||
tags:
|
||||
- 技术/WebDev
|
||||
- WebDev/Overview
|
||||
author: 7Wate
|
||||
date: 2024-09-30
|
||||
---
|
||||
|
||||
## 简介
|
||||
|
||||
前端开发是当今技术领域的重要组成部分,它使我们能够以视觉上吸引人的、交互式的方式浏览网站和网络应用程序。
|
||||
|
||||
### 前端开发的定义
|
||||
|
||||
前端开发,有时也被称为客户端开发,是创建网络应用程序或网站用户交互界面的实践。它涉及到的技术包括 HTML、CSS 和 JavaScript,以及各种现代框架和库,如 React、Angular 和 Vue.js。前端开发者的目标是提供一个高度交互的、用户友好的界面,它可以在各种设备和浏览器上无缝工作。
|
||||
|
||||
### 前端与后端的区别
|
||||
|
||||
**在理解前端和后端的区别时,最直接的比喻可能就是一家餐厅。在这个比喻中,前端开发者就像是餐厅的服务员,他们直接与顾客(用户)互动,提供菜单,接收订单,并提供所需的食物(数据)。而后端开发者就像是厨师,他们在幕后处理服务员传来的订单,并准备好食物。**
|
||||
|
||||
在技术方面,前端开发主要关注用户界面和用户体验,而后端开发则是处理服务器、应用和数据库之间的交互。后端开发者使用如 Python、Ruby、Java、PHP 等服务器端语言,创建应用的业务逻辑,管理数据库,以及处理用户的请求和响应。
|
||||
|
||||
### 前端开发的重要性
|
||||
|
||||
前端开发的重要性在于它**直接影响到用户的体验。**一个易于使用、视觉吸引人的界面可以大大增加用户的满意度,提高用户的参与度,甚至影响到公司的品牌形象。此外,前端开发也涉及到网站的可访问性和响应式设计,这可以确保所有用户,无论他们使用的设备类型或者他们的身体能力如何,都可以方便的访问和使用网站。
|
||||
|
||||
在当今的数字化世界中,前端开发已经变得至关重要。无论是小型的静态网站,还是大型的复杂网络应用,都需要前端开发者的专业技能和经验来创建用户友好的界面。在未来,随着技术的不断发展和新的用户需求的出现,前端开发的重要性只会继续增加。
|
||||
|
||||
## 历史发展
|
||||
|
||||
前端开发已经经历了长达几十年的发展历程,从最初的静态网页到现在的复杂的 Web 交互应用,前端开发的技术和工具都发生了巨大的变化。下面是前端开发的一些主要发展阶段:
|
||||
|
||||
### 1990 年代:静态网页时代
|
||||
|
||||
在 1990 年,Tim Berners-Lee 发明了万维网,也就标志着网页的诞生。在这个阶段,网页主要由纯文本构成,使用 HTML(HyperText Markup Language)进行标记。这些网页被称为静态网页,因为它们的内容在服务器端生成,用户端不能交互和修改。
|
||||
|
||||
### 1995 年:JavaScript 的诞生
|
||||
|
||||
1995 年,JavaScript 语言在 Netscape 浏览器上首次亮相,由 Brendan Eich 发明。最初,JavaScript 被用作一种客户端的脚本语言,用于实现网页上的简单交互效果,如表单验证等。
|
||||
|
||||
### 1996 年: CSS 的诞生
|
||||
|
||||
1996 年,W3C(万维网联盟)发布了 CSS(Cascading Style Sheets)的第一版规范,标志着样式表的诞生。CSS 的出现使得开发者可以更加方便地控制网页的样式和布局。
|
||||
|
||||
### 2000 年代初:动态网页和 AJAX
|
||||
|
||||
2000 年代初,随着 JavaScript 和服务端技术的发展,网页开始从静态向动态转变。AJAX(Asynchronous JavaScript and XML)技术的出现,使得网页可以在不刷新页面的情况下与服务器进行交互,极大地提高了用户体验。
|
||||
|
||||
### 2006 年:jQuery 的出现
|
||||
|
||||
2006 年,jQuery 库发布,提供了一种简洁易用的 API 来操作 HTML 文档、处理事件、创建动画以及进行 AJAX 交互。jQuery 的出现极大地简化了前端开发,使得开发者可以用更少的代码完成更多的功能。
|
||||
|
||||
### 2008 年:Chrome 浏览器和 V8 引擎
|
||||
|
||||
2008 年,Google 发布了 Chrome 浏览器和 V8 JavaScript 引擎。V8 引擎的出现极大地提升了 JavaScript 的运行速度,使得 JavaScript 能够用于更复杂的应用。
|
||||
|
||||
### 2010 年代:前端框架和工具的崛起
|
||||
|
||||
2010 年代,前端开发进入了一个新的时代。一方面,出现了大量的前端框架和库,如 Angular、React 和 Vue.js,使得开发者可以更容易地构建复杂的前端应用。另一方面,前端开发工具和生态系统也得到了极大的发展,如 Node.js、webpack、Babel、ESLint 等。
|
||||
|
||||
### 2015 年至今:现代前端开发
|
||||
|
||||
2015 年,ECMAScript 6(也称为 ES2015)的发布,为 JavaScript 带来了许多新的语言特性,如类、模块、箭头函数、Promises、生成器等。同时,随着 Web Components 和 Progressive Web Apps(PWA)的出现,前端开发正在朝着更加模块化、组件化和原生应用化的方向发展。
|
||||
|
||||
在过去的几十年里,前端开发经历了从静态网页到复杂 Web 应用的巨大转变。尽管前端开发的技术和工具不断变化,但其核心目标一直未变,那就是创建出色的用户体验。
|
||||
|
||||
## 现代化开发工具
|
||||
|
||||
在前端开发过程中,开发者需要利用一系列的工具和技术来提高工作效率、确保代码质量和进行项目管理。这些工具和技术构成了前端的开发工具链。以下是一些现代前端开发中常用的工具和技术:
|
||||
|
||||
### 版本控制
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| ------------ | ---------------------------------------------------- | -------------------------------------------------------- | ------------------------------------ | ---------------------------------- |
|
||||
| Git | 分布式版本控制系统,用于项目文件的版本管理。 | 分布式版本控制、支持分支管理、离线工作、社区庞大 | 强大的分支管理、协作便利、开源且免费 | 初学者理解复杂的操作和概念需要时间 |
|
||||
| GitFlow | Git 的工作流,用于更有条理地管理项目的分支。 | 特定的分支策略(主分支、开发分支、功能分支、发布分支等) | 结构化分支模型,适用于大中型项目 | 小型项目中可能显得冗余 |
|
||||
| Pull Request | 用于代码审查和协作开发,尤其在 GitHub 和 GitLab 上常见。 | 代码审查、自动测试集成、评论机制 | 易于团队协作、审查代码质量 | 对于较小的团队可能不必要 |
|
||||
|
||||
### 包管理器
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| -------- | ---------------------------------------------------------- | -------------------------------------- | ----------------------------------------- | ------------------------------------ |
|
||||
| npm | Node.js 的默认包管理器,用于安装和管理项目依赖。 | 全球最大的 JavaScript 包仓库、广泛支持 | 社区广泛支持、工具链成熟、默认支持 Node.js | 安装速度较慢、容易出现版本管理问题 |
|
||||
| Yarn | Facebook 开发的包管理器,提供更快的安装速度。 | 并行下载依赖、离线缓存、语义化版本锁定 | 更快的包安装速度、更好的依赖缓存 | 社区支持不如 npm 广泛 |
|
||||
| pnpm | 高效的包管理器,类似于 npm 和 Yarn,使用软链接来提高效率。 | 节省磁盘空间、安装速度快、依赖项去重 | 高效的依赖管理、节省磁盘空间 | 社区相对较小,部分包的兼容性尚需验证 |
|
||||
|
||||
### 代码编辑器
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| ------------------ | ------------------------------------------------------------ | ------------------------------------------------------ | ------------------------------------ | -------------------------------------- |
|
||||
| Visual Studio Code | 微软开发的开源代码编辑器,支持多种语言和插件。 | 语法高亮、代码补全、调试工具、Git 集成、丰富的插件生态 | 免费、跨平台、插件系统强大、社区活跃 | 某些复杂插件可能影响性能 |
|
||||
| WebStorm | JetBrains 开发的专业 IDE,专为前端和 JavaScript 开发者设计。 | 集成调试、代码补全、测试工具、React/Vue/Angular 支持 | 专业级功能、集成度高、支持多种框架 | 付费软件、占用资源较多 |
|
||||
| Sublime Text | 轻量级代码编辑器,支持多种语言和插件。 | 语法高亮、代码折叠、插件支持、极快的启动速度 | 性能极佳、轻量快速、支持多种编程语言 | 许多高级插件需要付费购买,社区相对较小 |
|
||||
|
||||
### 模块打包器
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| -------- | ---------------------------------------------------------- | ------------------------------------------------------------ | -------------------------------------- | ------------------------------------------------- |
|
||||
| Webpack | 强大的 JavaScript 模块打包工具,支持项目的依赖管理和打包。 | 代码分割、Tree-shaking、动态导入、CSS 和 JS 处理、多种插件和扩展 | 强大的生态系统、灵活性高、适合大型项目 | 配置复杂、学习曲线较陡 |
|
||||
| Vite | 轻量级开发服务器和构建工具,专为现代前端开发优化。 | 原生 ES 模块支持、开发服务器启动快、热模块替换(HMR) | 快速启动、极简配置、现代开发体验 | 功能相对简洁,高级功能可能需要配合 Webpack 等使用 |
|
||||
| Parcel | 零配置的快速打包工具,适合小型项目快速启动。 | 零配置、自动依赖解析、支持 JS、CSS、HTML 等多种资源打包 | 快速简单、易于上手、自动化程度高 | 对于大型项目可能显得过于简洁,配置不够灵活 |
|
||||
| Rollup | 专注于打包 ES 模块的打包工具,常用于库的打包。 | Tree-shaking、按需加载、模块化支持 | 打包体积小、适合库开发 | 配置相对复杂,功能不如 Webpack 丰富 |
|
||||
| Snowpack | 新兴打包工具,支持即时开发和快速的模块打包。 | 快速开发、基于 ES 模块、按需构建 | 开发速度极快、支持热重载 | 功能相对较少,适合轻量项目,不如 Webpack 灵活 |
|
||||
|
||||
### 代码转译器
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| ------------------- | --------------------------------------------------------- | ---------------------------------------------------- | ---------------------------------- | --------------------------------------- |
|
||||
| Babel | JavaScript 编译器,支持将现代 JS 转译为向后兼容的版本。 | ES6+ 支持、TypeScript 支持、React JSX 转译、插件扩展 | 强大的语法转换功能、跨浏览器兼容性 | 配置复杂,需要合适的 preset 和 plugin |
|
||||
| TypeScript Compiler | TypeScript 官方的编译器,将 TS 代码编译为 JS。 | 类型检查、语法转换、与现代 JS 兼容 | 静态类型检查、提升代码可靠性 | 对于纯 JS 项目引入 TS 可能显得复杂 |
|
||||
| SWC | 新兴的快速 JavaScript/TypeScript 编译器,用 Rust 实现。 | 高性能转译、支持多种语言(JS、TS、React JSX) | 编译速度极快、支持现代语法 | 社区支持和插件生态尚不成熟 |
|
||||
| Sucrase | 专注于速度的 JavaScript 编译器,支持 TypeScript、JSX 等。 | 极快的编译速度、支持 JSX 和 TypeScript | 极度优化的性能 | 功能相对有限,缺少一些 Babel 的高级功能 |
|
||||
| Traceur | Google 开发的 ES6 转译器,允许 ES6 代码在旧浏览器中运行。 | ES6 支持、Polyfill 提供 | 支持旧浏览器、轻量化 | 生态和社区支持不如 Babel 和 SWC 等 |
|
||||
|
||||
### 代码检查器
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| --------- | -------------------------------------------------------- | ------------------------------------------------ | ------------------------------ | ---------------------------------------------------------- |
|
||||
| ESLint | 开源 JavaScript 代码检查工具,用于发现代码中的潜在问题。 | 自定义规则、插件扩展、自动修复、与多种编辑器集成 | 灵活的配置、强大的插件生态系统 | 初次配置可能较复杂,尤其在大项目中 |
|
||||
| TSLint | 专为 TypeScript 开发的静态代码检查工具。 | 专注于 TypeScript 检查、强大的类型检查功能 | 专业针对 TS 项目,集成度高 | 已被官方宣布停止维护,推荐迁移到 ESLint 与 TypeScript 插件 |
|
||||
| Prettier | 代码格式化工具,自动对 JS、CSS、HTML 等进行格式化。 | 自动格式化、支持多种语言、与编辑器和 CI 集成 | 保证代码风格一致性、易于集成 | 无法进行语法错误检查,需与 ESLint 配合使用 |
|
||||
| Stylelint | CSS 代码检查工具,支持 Sass、Less 等预处理器。 | 自定义规则、自动修复、与编辑器集成 | 提高 CSS 代码质量、可配置性高 | 需与 ESLint 配合,单独使用对大型项目管理不够全面 |
|
||||
| SonarQube | 用于代码质量检测的工具,支持多种语言的代码分析。 | 多语言支持、静态代码分析、漏洞扫描 | 代码质量分析全面、集成方便 | 配置复杂,适合大型项目和企业应用 |
|
||||
|
||||
### 测试框架
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| -------- | ------------------------------------------------------------ | -------------------------------------------------------- | ------------------------------ | ------------------------------------------------- |
|
||||
| Jest | Facebook 开发的 JavaScript 测试框架,支持单元测试、集成测试。 | 内置模拟和快照测试、异步测试支持、React 集成 | 配置简单、性能优异、社区广泛 | 对非 React 项目支持稍弱 |
|
||||
| Mocha | JavaScript 测试框架,提供灵活的测试 API。 | 灵活的测试框架、支持异步测试、与 Chai 和 Sinon 兼容 | 灵活、可扩展、生态系统强大 | 需要集成断言库(如 Chai)和测试替身库(如 Sinon) |
|
||||
| Jasmine | 行为驱动开发(BDD)的测试框架,专注于语义化断言和报告。 | 语义化断言、开箱即用、支持异步测试 | API 简洁、集成容易 | 功能相对 Mocha 简单,不如 Jest 集成度高 |
|
||||
| Karma | JavaScript 测试运行器,专为浏览器测试而设计。 | 多浏览器测试支持、与 CI 集成良好、与 Mocha、Jasmine 集成 | 便于在多浏览器中进行测试 | 单独使用功能有限,通常与其他测试框架配合使用 |
|
||||
| Cypress | 端到端测试框架,允许模拟用户行为和测试整个应用。 | 端到端测试、浏览器集成、模拟用户交互 | 开发体验极佳、测试用例编写简单 | 仅支持 Chrome 和 Electron,跨浏览器支持较弱 |
|
||||
|
||||
### 前端框架
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| -------- | ----------------------------------------------------- | -------------------------------------------------- | ---------------------------------------- | ---------------------------------------------- |
|
||||
| React | Facebook 开发的前端 UI 框架,采用组件化和声明式编程。 | 组件化、虚拟 DOM、单向数据流、Hooks 支持、JSX 语法 | 生态系统庞大、组件复用性高、灵活性强 | 学习曲线较陡、需配合路由和状态管理库使用 |
|
||||
| Vue.js | 轻量级前端框架,支持渐进式开发,适合小型和中型项目。 | 双向绑定、虚拟 DOM、组件化、易于集成第三方库 | 学习曲线平缓、灵活性强、文档详细 | 在大型项目中生态系统不如 React 或 Angular 完善 |
|
||||
| Angular | 全功能型前端框架,支持企业级应用开发,谷歌长期维护。 | 双向绑定、依赖注入、模块化开发、强类型支持 | 强大的生态系统、适合大型项目、企业支持强 | 学习曲线陡峭、框架较为重量级 |
|
||||
| Svelte | 新兴的前端框架,编译时生成高度优化的代码。 | 无虚拟 DOM、编译时优化、轻量级、快速渲染 | 代码简洁、性能卓越、无框架运行时开销 | 社区支持和生态系统相对较小,适合小型项目 |
|
||||
| Ember.js | 企业级 JavaScript 框架,支持约定优于配置。 | 路由支持、模板引擎、组件化、双向数据绑定 | 适合大型项目、内置许多最佳实践 | 学习曲线较陡峭,社区不如 React 和 Vue 活跃 |
|
||||
|
||||
### CSS 预处理器
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| ----------- | --------------------------------------------------- | -------------------------------------------- | ------------------------------------- | ------------------------------------------ |
|
||||
| Sass | 强大的 CSS 预处理器,允许使用变量、嵌套规则等功能。 | 变量、嵌套、混合、继承、兼容标准 CSS | 提高可维护性和可读性、广泛支持 | 编译过程复杂,开发体验与标准 CSS 有差异 |
|
||||
| Less | CSS 预处理器,灵感来自 Sass,允许使用变量和函数。 | 变量、嵌套、函数支持、兼容标准 CSS | 简单易用、与现有 CSS 兼容性强 | 社区活跃度和生态系统不如 Sass 丰富 |
|
||||
| Stylus | 灵活的 CSS 预处理器,支持多种语法风格。 | 自定义语法风格、灵活配置、支持变量和函数 | 灵活性强、开发体验优秀 | 使用相对复杂,社区支持不如 Sass 或 Less |
|
||||
| PostCSS | 用于转换 CSS 的工具,支持多种插件。 | 插件扩展、现代 CSS 特性、与构建工具集成 | 支持最新 CSS 特性、与其他工具兼容性好 | 需根据具体项目配置插件,初学者可能感到复杂 |
|
||||
| CSS Modules | CSS 模块化方案,允许 CSS 在局部作用域中生效。 | 局部作用域、自动生成类名、与 JavaScript 集成 | 样式隔离性好、适合组件化开发 | 需要与构建工具集成,使用稍有复杂 |
|
||||
|
||||
### 服务器端渲染(SSR)和静态站点生成(SSG)
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| -------- | ---------------------------------------------------------- | ---------------------------------------------- | ----------------------------------------------- | ---------------------------------------------------------- |
|
||||
| Next.js | React 的 SSR 和 SSG 框架,支持服务器端渲染和静态站点生成。 | SSR、SSG、API 路由支持、自动路由、CSS 模块支持 | 提升 SEO 和首屏加载速度、功能强大、社区支持广泛 | 配置相对复杂,学习曲线比传统 React 项目陡峭 |
|
||||
| Nuxt.js | Vue.js 的 SSR 和 SSG 框架,简化服务器端渲染过程。 | SSR、SSG、模块化、自动路由、SEO 优化 | 与 Vue.js 无缝集成、提升性能和 SEO、开发体验好 | 大型项目中的性能调优有时较为复杂 |
|
||||
| Gatsby | React 的静态站点生成框架,专注于构建快速的静态网站。 | SSG、GraphQL 数据层、插件丰富、PWA 支持 | 静态网站生成快、开发体验好、生态系统成熟 | 动态内容支持较弱,对于大型动态站点不适用 |
|
||||
| Hugo | 基于 Go 的静态站点生成器,专注于构建快速静态网站。 | SSG、极快的构建速度、模板引擎、支持多语言 | 极快的生成速度、模板灵活、文档优秀 | 配置和模板引擎较复杂,学习曲线较陡 |
|
||||
| Sapper | Svelte 的 SSR 和 SSG 框架,支持灵活的渲染模式。 | SSR、SSG、轻量快速、PWA 支持 | 轻量化、高性能、Svelte 社区支持 | 社区和生态系统较小,开发工具链不如 Next.js 和 Nuxt.js 成熟 |
|
||||
|
||||
好的!接下来,我将补充一些其他类别的前端开发工具,包括**服务器端渲染(SSR)和静态站点生成(SSG)**、**端到端测试(E2E)**、**API Mocking 工具**、**设计工具和 UI 组件库**、**持续集成/持续部署(CI/CD)**等。每个类目仍然会保持 3-5 个工具的介绍,继续以表格形式提供详细信息。
|
||||
|
||||
------
|
||||
|
||||
### 服务器端渲染(SSR)和静态站点生成(SSG)
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| -------- | ---------------------------------------------------------- | ---------------------------------------------- | ----------------------------------------------- | ---------------------------------------------------------- |
|
||||
| Next.js | React 的 SSR 和 SSG 框架,支持服务器端渲染和静态站点生成。 | SSR、SSG、API 路由支持、自动路由、CSS 模块支持 | 提升 SEO 和首屏加载速度、功能强大、社区支持广泛 | 配置相对复杂,学习曲线比传统 React 项目陡峭 |
|
||||
| Nuxt.js | Vue.js 的 SSR 和 SSG 框架,简化服务器端渲染过程。 | SSR、SSG、模块化、自动路由、SEO 优化 | 与 Vue.js 无缝集成、提升性能和 SEO、开发体验好 | 大型项目中的性能调优有时较为复杂 |
|
||||
| Gatsby | React 的静态站点生成框架,专注于构建快速的静态网站。 | SSG、GraphQL 数据层、插件丰富、PWA 支持 | 静态网站生成快、开发体验好、生态系统成熟 | 动态内容支持较弱,对于大型动态站点不适用 |
|
||||
| Hugo | 基于 Go 的静态站点生成器,专注于构建快速静态网站。 | SSG、极快的构建速度、模板引擎、支持多语言 | 极快的生成速度、模板灵活、文档优秀 | 配置和模板引擎较复杂,学习曲线较陡 |
|
||||
| Sapper | Svelte 的 SSR 和 SSG 框架,支持灵活的渲染模式。 | SSR、SSG、轻量快速、PWA 支持 | 轻量化、高性能、Svelte 社区支持 | 社区和生态系统较小,开发工具链不如 Next.js 和 Nuxt.js 成熟 |
|
||||
|
||||
------
|
||||
|
||||
### 端到端测试(E2E)
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| ---------- | ----------------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------ | ----------------------------------------------------- |
|
||||
| Cypress | 现代化端到端测试框架,允许模拟用户行为并测试整个应用。 | 端到端测试、自动等待、快照功能、内置测试服务器 | 开发体验优秀、测试编写简单、调试方便 | 跨浏览器支持有限(仅支持 Chrome 和 Electron) |
|
||||
| Puppeteer | Google 开发的用于控制 Chrome 浏览器的自动化库。 | 浏览器自动化、无头浏览器支持、页面截图和生成 PDF、页面抓取 | 强大的浏览器控制能力、支持无头浏览器 | 仅限 Chrome 和 Chromium,跨浏览器支持较差 |
|
||||
| Playwright | 由 Microsoft 开发的跨浏览器自动化测试工具,支持多种浏览器。 | 支持多浏览器(Chromium、Firefox、WebKit)、并行执行测试、多语言 API 支持 | 跨浏览器支持强大、性能好、API 简洁 | 配置相对 Puppeteer 更复杂,较新的项目社区资源相对较少 |
|
||||
| TestCafe | 简单易用的端到端测试框架,无需额外安装浏览器插件。 | 无需浏览器插件、内置测试服务器、支持多浏览器 | 易于上手、跨浏览器支持好 | 相比 Cypress 等工具,功能不够丰富 |
|
||||
| Selenium | 历史悠久的自动化测试框架,支持多种编程语言和浏览器。 | 多语言支持、跨浏览器支持、与 CI 集成良好 | 跨浏览器支持强、企业级应用多 | 配置复杂、性能较慢,较新项目可能觉得过于重量级 |
|
||||
|
||||
### API Mocking 工具
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| ------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------------------------------------------------------- | --------------------------------------------- |
|
||||
| Mirage JS | 专注于前端的 API Mocking 库,允许模拟 REST 和 GraphQL API。 | API Mocking、模拟 REST 和 GraphQL、内置数据库、无需后端依赖 | 开发体验优秀、与前端框架无缝集成(如 React、Vue、Ember) | 仅适用于前端,后端项目使用较少 |
|
||||
| json-server | 快速创建一个完整的 REST API,用于前端开发和测试。 | 快速生成 REST API、零配置、简单 JSON 文件即为数据库 | 开发快速、无需配置、适合小型项目 | 不适合复杂 API 或动态数据交互,功能相对简单 |
|
||||
| Mockoon | 桌面应用,用于生成本地的 API Mock 服务器。 | 本地 Mock 服务器、支持 REST 和 GraphQL、GUI 界面、导出导入 API 模型 | 易于上手、跨平台、直观的 GUI | 对于复杂场景不够灵活,功能不如 Mirage JS 灵活 |
|
||||
| WireMock | Java 实现的 API Mocking 工具,适用于后端开发者。 | REST API Mock、支持复杂规则匹配、记录和重放请求 | 强大的规则配置、适合企业级后端项目 | 学习曲线较陡,主要面向后端开发 |
|
||||
| Mock Service Worker | 基于 Service Worker 的 Mock 工具,用于拦截和模拟 HTTP 请求。 | 基于浏览器的 API Mocking、无需额外服务器、支持 REST 和 GraphQL | 轻量灵活、无需依赖外部服务器 | 仅限于前端项目,浏览器兼容性有限 |
|
||||
|
||||
### 设计工具和 UI 组件库
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| ----------- | ------------------------------------------------------------ | ---------------------------------------------------- | --------------------------------------- | ------------------------------------------------- |
|
||||
| Figma | 基于云的 UI 设计和协作工具,支持团队实时协作。 | 云端协作、原型设计、插件支持、设计系统管理 | 多人实时协作、跨平台、免费版本功能丰富 | 高级功能需付费 |
|
||||
| Sketch | 知名的 UI 设计工具,专注于设计系统和原型设计。 | 原型设计、设计系统、插件生态丰富、与开发工具集成良好 | 专注于 UI 设计、插件丰富 | 仅限 macOS 平台,跨平台支持较差 |
|
||||
| Adobe XD | Adobe 推出的 UI 设计和原型设计工具,支持与 Adobe 生态系统集成。 | 原型设计、设计共享、与 Adobe 生态系统集成 | 与 Photoshop、Illustrator 等无缝集成 | 插件生态不如 Figma 和 Sketch 丰富,复杂功能需付费 |
|
||||
| Ant Design | 蚂蚁金服推出的企业级 UI 组件库,专注于数据驱动的企业应用。 | 预定义组件丰富、设计语言统一、国际化支持、React 集成 | 设计优秀、组件丰富、易于使用 | 定制化相对困难,适用于数据驱动的企业应用 |
|
||||
| Material-UI | Google 推出的 Material Design UI 组件库,适用于 React 项目。 | Material Design 风格、预定义组件丰富、React 集成 | Google 设计语言支持、组件丰富、文档详细 | 过度依赖 Material Design 风格,定制难度较大 |
|
||||
|
||||
### 持续集成/持续部署(CI/CD)
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| -------------- | -------------------------------------------------------- | ---------------------------------------------------------- | ---------------------------------------- | -------------------------------------------------- |
|
||||
| GitHub Actions | GitHub 提供的 CI/CD 工具,深度集成 GitHub 仓库。 | 深度集成 GitHub、支持自动化工作流、支持多平台和多语言 | 与 GitHub 无缝集成、社区支持好、配置灵活 | 仅适用于 GitHub 项目,复杂配置可能需要较长学习时间 |
|
||||
| Jenkins | 开源的 CI/CD 自动化服务器,广泛应用于企业级项目。 | 支持多种构建工具和语言、插件丰富、与企业工具集成良好 | 开源免费、支持多平台、多语言 | 界面较为简陋、配置复杂,学习曲线较陡 |
|
||||
| CircleCI | 基于云的 CI/CD 平台,专注于快速和高效的持续集成。 | 云端构建、并行任务执行、Docker 支持、丰富的集成功能 | 高效的并行构建、支持多种编程语言 | 免费版限制较多,复杂配置需付费版本 |
|
||||
| Travis CI | 基于云的 CI 服务,支持多种语言的持续集成。 | 与 GitHub 集成良好、支持多语言、简单配置、自动化测试和部署 | 配置简单、免费版可满足大部分需求 | 免费版并行任务有限制,企业级用户需付费 |
|
||||
| GitLab CI | GitLab 提供的 CI/CD 工具,支持私有仓库的持续集成和部署。 | 内置 CI/CD 支持、与 GitLab 仓库深度集成、Pipeline 可视化 | 私有库免费、CI/CD 集成度高 | GitLab 生态外的项目集成不如 Jenkins 等工具灵活 |
|
||||
|
||||
### 性能优化
|
||||
|
||||
| 工具名称 | 工具简介 | 特性 | 优点 | 缺点 |
|
||||
| ----------------------- | ----------------------------------------------------------- | ------------------------------------------------------- | ------------------------------------------ | ------------------------------------------------ |
|
||||
| Lighthouse | Google 开发的网页性能分析工具,评估页面的性能和最佳实践。 | 性能评估、SEO 分析、可访问性检测、PWA 支持 | 全面的性能评估、集成 DevTools、免费开源 | 仅用于性能评估,不直接提供优化解决方案 |
|
||||
| Webpack Bundle Analyzer | Webpack 插件,帮助开发者分析打包文件的大小和依赖关系。 | 可视化依赖分析、Tree-shaking 分析、包体积优化建议 | 帮助优化打包文件、可视化输出 | 仅限 Webpack 项目使用,其他打包工具支持较差 |
|
||||
| PageSpeed Insights | Google 提供的网页性能评估工具,支持移动和桌面页面分析。 | 性能指标分析、SEO 评估、可访问性检测、可视化建议 | 提供详细的优化建议、适合移动端和桌面端 | 对于复杂场景优化建议不够细化 |
|
||||
| WebPageTest | 开源网页性能测试工具,支持全球多个测试位置和多种浏览器。 | 支持多浏览器、多位置测试、详细的网络性能分析 | 网络性能测试全面、报告详细 | 相对 PageSpeed Insights 配置较为复杂 |
|
||||
| Perfume.js | 前端性能监控库,帮助开发者跟踪用户体验指标(如 FCP、TTI)。 | 性能指标监控、轻量、支持多种 UX 性能指标(FCP、TTI 等) | 开发者友好、易于集成、帮助优化页面加载时间 | 需要手动集成到项目中,对于非技术用户使用难度较高 |
|
||||
|
||||
## 未来发展趋势
|
||||
|
||||
在未来,前端开发预计将继续迅速发展和变化。以下是一些可能的发展趋势:
|
||||
|
||||
### 更丰富的交互体验
|
||||
|
||||
随着技术的进步,我们可以预期更加丰富和复杂的用户界面和交互体验。例如,虚拟现实(VR)和增强现实(AR)技术可能会更加普及,为前端开发带来全新的挑战和机遇。另外,随着机器学习和人工智能的发展,我们可能会看到更多的自适应和个性化的用户界面。
|
||||
|
||||
### 新的和改进的工具
|
||||
|
||||
前端开发工具在不断发展和改进。新的编程语言、库和框架正在不断出现,以解决前端开发者面临的新的挑战。例如,WebAssembly 可能会改变我们构建和运行前端应用的方式,而像 React Native 这样的框架可能会继续改变我们开发跨平台应用的方式。
|
||||
|
||||
### 性能优化
|
||||
|
||||
随着用户对于网页响应速度和流畅度的期望越来越高,性能优化将继续是前端开发的重要主题。包括如何有效地使用缓存、如何优化代码以减少加载时间、如何更好地使用网络资源等方面。
|
||||
|
||||
### Web 安全性
|
||||
|
||||
随着网络攻击和数据泄露事件的增多,Web 安全性将成为前端开发的重要考虑因素。前端开发者需要了解如何保护用户数据,如何防止跨站脚本(XSS)攻击,跨站请求伪造(CSRF)等。
|
||||
|
||||
### 可访问性和包容性
|
||||
|
||||
在未来,可访问性和包容性可能会成为前端开发的更重要的考虑因素。这意味着创建的网站和应用需要对所有人开放,无论他们的能力如何。这包括对于屏幕阅读器友好的设计,对于不同的输入方法(例如语音输入)的支持,以及对于不同文化和语言的考虑。
|
||||
373
Technology/WebDevelopment/1.Browser/1.浏览器概述.md
Normal file
373
Technology/WebDevelopment/1.Browser/1.浏览器概述.md
Normal file
@ -0,0 +1,373 @@
|
||||
---
|
||||
title: 浏览器概述
|
||||
description: 本文详细介绍了浏览器的核心功能,包括页面渲染、用户交互、网络通信,以及现代浏览器的主要组件。同时,探讨了浏览器的渲染机制、安全特性,以及前沿技术如PWA和WebAssembly。
|
||||
keywords:
|
||||
- 浏览器
|
||||
- 页面渲染
|
||||
- 用户交互
|
||||
- 网络通信
|
||||
- 渲染引擎
|
||||
- 安全机制
|
||||
- PWA
|
||||
- WebAssembly
|
||||
tags:
|
||||
- 技术/WebDev
|
||||
- WebDev/Browser
|
||||
author: 仲平
|
||||
date: 2024-09-30
|
||||
---
|
||||
|
||||
## 浏览器的基本概念
|
||||
|
||||

|
||||
|
||||
**浏览器是现代互联网中不可或缺的核心工具,主要用于在人与网络世界之间建立交互桥梁。**它的核心功能是解析和渲染网页内容,将服务器端传送的代码(如 HTML、CSS、JavaScript 等)转化为用户能够直观理解和操作的图形界面。借助浏览器,用户可以轻松访问各类网站、查找信息、观看多媒体内容、进行在线购物以及处理电子邮件等。此外,现代浏览器还具备扩展功能,支持插件与增强安全特性,以提供更加个性化和安全的网络体验。
|
||||
|
||||
随着互联网技术的不断发展,浏览器不仅仅是简单的网页查看工具,它还逐渐演变为集成各种网络服务的平台,支持云计算、在线协作、实时通信等丰富的功能。因此,浏览器已经成为人们日常工作、学习和娱乐不可或缺的工具之一。
|
||||
|
||||
### 浏览器的核心功能
|
||||
|
||||
**浏览器的核心功能可以归结为三个主要方面:页面渲染、用户交互与网络通信。** 这些功能是用户与互联网内容交互的基础。
|
||||
|
||||
#### 1. **解析和渲染**
|
||||
|
||||
浏览器的首要职责是将开发者编写的 HTML、CSS 和 JavaScript 代码转换为可视化的网页内容。这一过程被称为**渲染**。具体而言,浏览器通过渲染引擎解析 HTML 生成 DOM 树、解析 CSS 生成 CSSOM 树,并将二者结合生成渲染树,最终通过布局计算和绘制,将结构化数据转化为图形并显示在用户屏幕上。
|
||||
|
||||
渲染的流程大致可归纳为以下几个步骤:
|
||||
|
||||
1. **解析**:将 HTML 和 CSS 转化为 DOM 树和 CSSOM 树。
|
||||
2. **生成渲染树**:结合 DOM 和 CSSOM,创建用于页面布局和显示的渲染树。
|
||||
3. **布局(Reflow)**:根据视口大小和 CSS 样式规则计算每个元素的几何位置和大小。
|
||||
4. **绘制(Paint)**:将渲染树中的每个节点绘制到屏幕上。
|
||||
|
||||
这一系列步骤是浏览器性能优化的关键领域,开发者通常通过减少**重排(Reflow)**和**重绘(Repaint)**操作,提升页面的渲染效率。
|
||||
|
||||
#### 2. **用户交互**
|
||||
|
||||
浏览器不仅负责页面渲染,还必须处理来自用户的输入与操作。用户交互通过事件机制实现,常见的交互方式包括:
|
||||
|
||||
- **鼠标事件**:如点击、双击、鼠标悬停等。
|
||||
- **键盘事件**:如按键输入、组合键操作。
|
||||
- **触摸事件**:如触摸屏上的滑动、缩放操作。
|
||||
|
||||
浏览器通过事件监听器捕捉这些用户操作,并根据定义的响应行为更新页面内容或执行特定的功能。这一机制是现代 Web 应用动态交互的基础。
|
||||
|
||||
#### 3. **网络请求与数据传输**
|
||||
|
||||
浏览器还需要与远程服务器进行通信,以获取和发送数据。这一过程主要通过 HTTP 或 HTTPS 协议完成。浏览器发送请求时,会附带相关的头部信息(headers),服务器返回的响应包括页面资源(如 HTML、CSS、JavaScript 文件)和其他相关数据(如 JSON 数据、图像资源)。在这个过程中,浏览器负责处理以下任务:
|
||||
|
||||
- **DNS 解析**:将域名转换为服务器的 IP 地址。
|
||||
- **TLS/SSL 加密**:确保 HTTPS 通信的安全性。
|
||||
- **HTTP 请求/响应处理**:发送请求、接收响应并解析数据。
|
||||
|
||||
现代浏览器还引入了多种优化手段,如 HTTP/2、HTTP 缓存、服务端推送等,以减少页面加载时间并提高数据传输效率。
|
||||
|
||||
### 现代浏览器的主要组件
|
||||
|
||||
现代浏览器为了支持上述核心功能,内部架构由多个组件组成。每个组件负责特定的任务,并相互协作提供完整的浏览器功能。
|
||||
|
||||
#### 1. **用户界面(UI)**
|
||||
|
||||
用户界面是用户与浏览器交互的入口,通常包括:
|
||||
|
||||
- **地址栏**:输入 URL 以导航至不同的网站。
|
||||
- **导航按钮**:前进、后退按钮用于页面间的跳转。
|
||||
- **标签页**:允许用户同时访问多个网站,每个网站在不同的标签页中独立显示。
|
||||
- **菜单和书签**:供用户快捷访问浏览器功能和常用网站。
|
||||
|
||||
这些元素都是浏览器的外部表现,与用户的交互体验息息相关。
|
||||
|
||||
#### 2. **浏览器引擎**
|
||||
|
||||
浏览器引擎位于用户界面和渲染引擎之间,负责管理两者之间的通信。它接收来自用户界面的指令(如用户输入的 URL),并控制渲染引擎加载和显示网页内容。此外,浏览器引擎还负责管理其他功能模块,如插件和扩展。
|
||||
|
||||
#### 3. **渲染引擎**
|
||||
|
||||
渲染引擎是浏览器的核心,它决定了页面的渲染速度和精度。其主要任务是解析 HTML、CSS,并将它们转化为用户可以看到的视觉内容。不同的浏览器使用不同的渲染引擎:
|
||||
|
||||
- **Blink**:由 Chrome、Edge 使用,是目前最广泛应用的渲染引擎。
|
||||
- **Gecko**:由 Firefox 使用,具有高可扩展性和跨平台支持。
|
||||
- **WebKit**:由 Safari 使用,曾经是 Chrome 的前身渲染引擎。
|
||||
|
||||
每个渲染引擎都有自己独特的实现方式和优化策略,但其基本工作原理相似。
|
||||
|
||||
#### 4. **网络模块**
|
||||
|
||||
网络模块处理所有与服务器的通信任务,确保浏览器可以正确获取远程资源。这些任务包括:
|
||||
|
||||
- 发送和接收 HTTP/HTTPS 请求。
|
||||
- 管理网络缓存,避免重复加载相同资源。
|
||||
- 处理跨域资源共享(CORS)和安全策略。
|
||||
|
||||
高效的网络模块设计可以显著提高页面加载速度,尤其是在资源密集型的网页中。
|
||||
|
||||
#### 5. **JavaScript 引擎**
|
||||
|
||||
JavaScript 引擎的主要任务是解析、编译并执行网页中的 JavaScript 代码。随着 Web 应用的复杂度不断提高,JavaScript 引擎的性能显得尤为重要。主流的 JavaScript 引擎包括:
|
||||
|
||||
- **V8**:由 Google 开发,使用在 Chrome 和 Edge 中。以其快速的编译速度和高效的垃圾回收机制著称。
|
||||
- **SpiderMonkey**:由 Mozilla 开发,使用在 Firefox 中。支持最新的 ECMAScript 标准,并具备高级优化功能。
|
||||
- **JavaScriptCore**:由 Apple 开发,使用在 Safari 中。为 WebKit 项目提供强大的 JavaScript 支持。
|
||||
|
||||
这些引擎在执行 JavaScript 时,通常采用即时编译(Just-in-time Compilation, JIT)技术,将 JavaScript 代码编译为机器码以提高执行效率。
|
||||
|
||||
#### 6. **数据存储**
|
||||
|
||||
浏览器提供了多种数据存储机制,以支持持久化和缓存用户数据。这些存储机制主要包括:
|
||||
|
||||
- **Cookie**:最早的数据存储机制,常用于会话管理、用户偏好存储等。它有较小的存储空间(通常为 4KB),并且会随请求发送至服务器。
|
||||
- **Local Storage & Session Storage**:HTML5 引入的客户端存储方式,Local Storage 用于持久存储,Session Storage 则仅在浏览器会话期间有效。
|
||||
- **IndexedDB**:提供复杂的数据库查询能力,适用于存储大量结构化数据。通常用于离线 Web 应用。
|
||||
|
||||
这些数据存储机制帮助浏览器提升用户体验,例如,通过缓存数据实现快速加载,或在用户离线时继续提供应用功能。
|
||||
|
||||
## 浏览器的渲染机制
|
||||
|
||||
浏览器的渲染机制是将用户请求的网页资源转化为可视化内容的过程。该过程涉及多个步骤,包括解析页面内容、计算布局、绘制图形,并最终呈现到屏幕上。了解这些步骤有助于开发者优化网页的性能,提高用户体验。
|
||||
|
||||
### 渲染流程概述
|
||||
|
||||
从用户输入 URL 到页面完全呈现,浏览器会依次执行多个步骤。这些步骤确保浏览器能够从服务器获取网页资源,并将其转换为可供用户交互的可视化内容。以下是这一过程的概述:
|
||||
|
||||
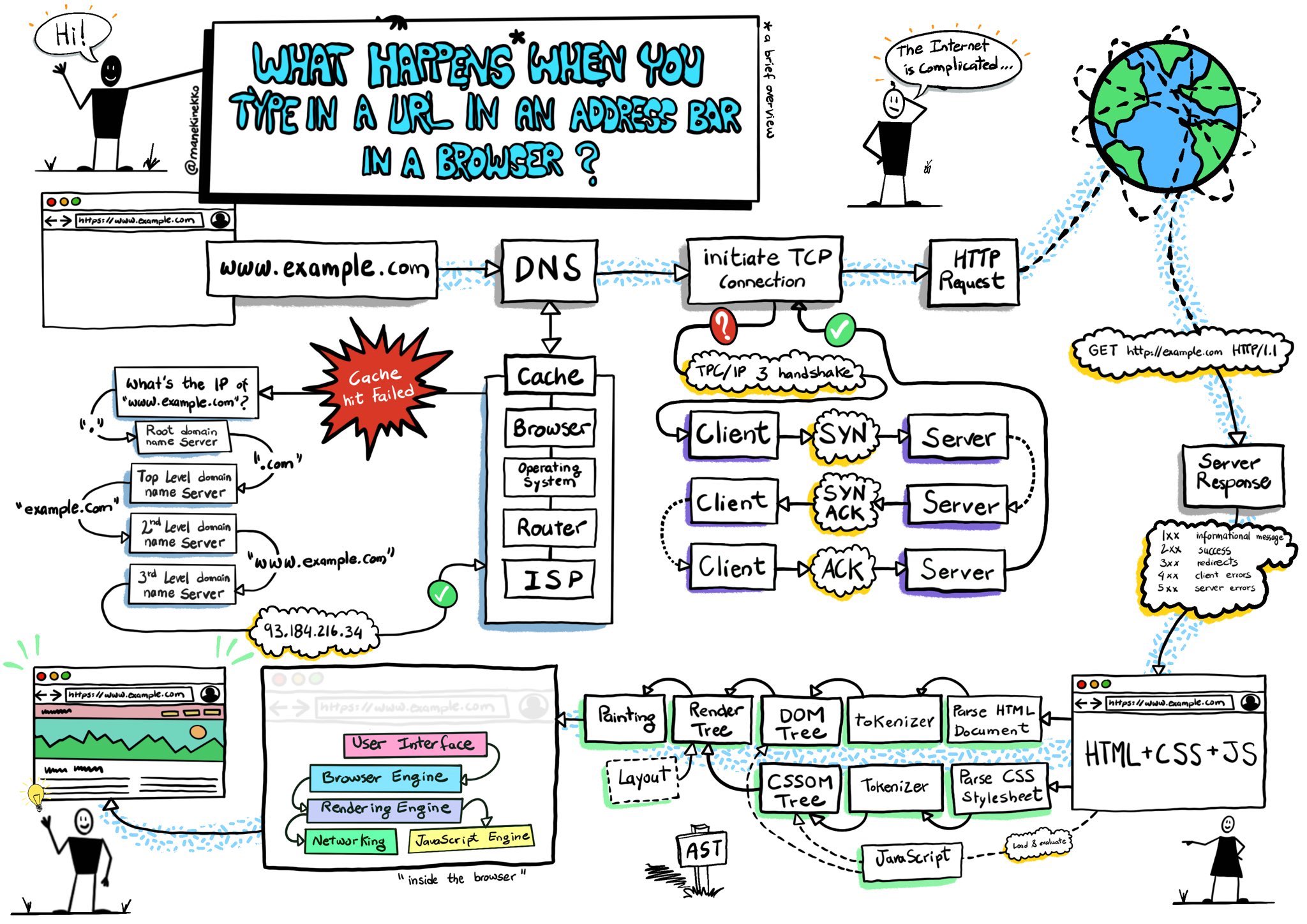
|
||||
|
||||
#### 1. 客户端建立连接并发起 HTTP 请求
|
||||
|
||||
当用户在浏览器地址栏输入 URL 并按下回车时,浏览器首先需要将域名转换为对应的服务器 IP 地址。这一过程称为**DNS 解析**,通常通过查询本地缓存或向 DNS 服务器发送请求完成。
|
||||
|
||||
浏览器通过 IP 地址定位服务器,并通过**TCP**协议建立连接。如果使用 HTTPS 协议,则同时会通过**TLS**(传输层安全协议)加密数据传输,以确保数据的安全性。
|
||||
|
||||
连接建立后,浏览器会发送**HTTP 请求**,请求的资源包括 HTML 文档、CSS 样式、JavaScript 文件、图像等。服务器响应浏览器的请求,并返回相应的资源文件。
|
||||
|
||||
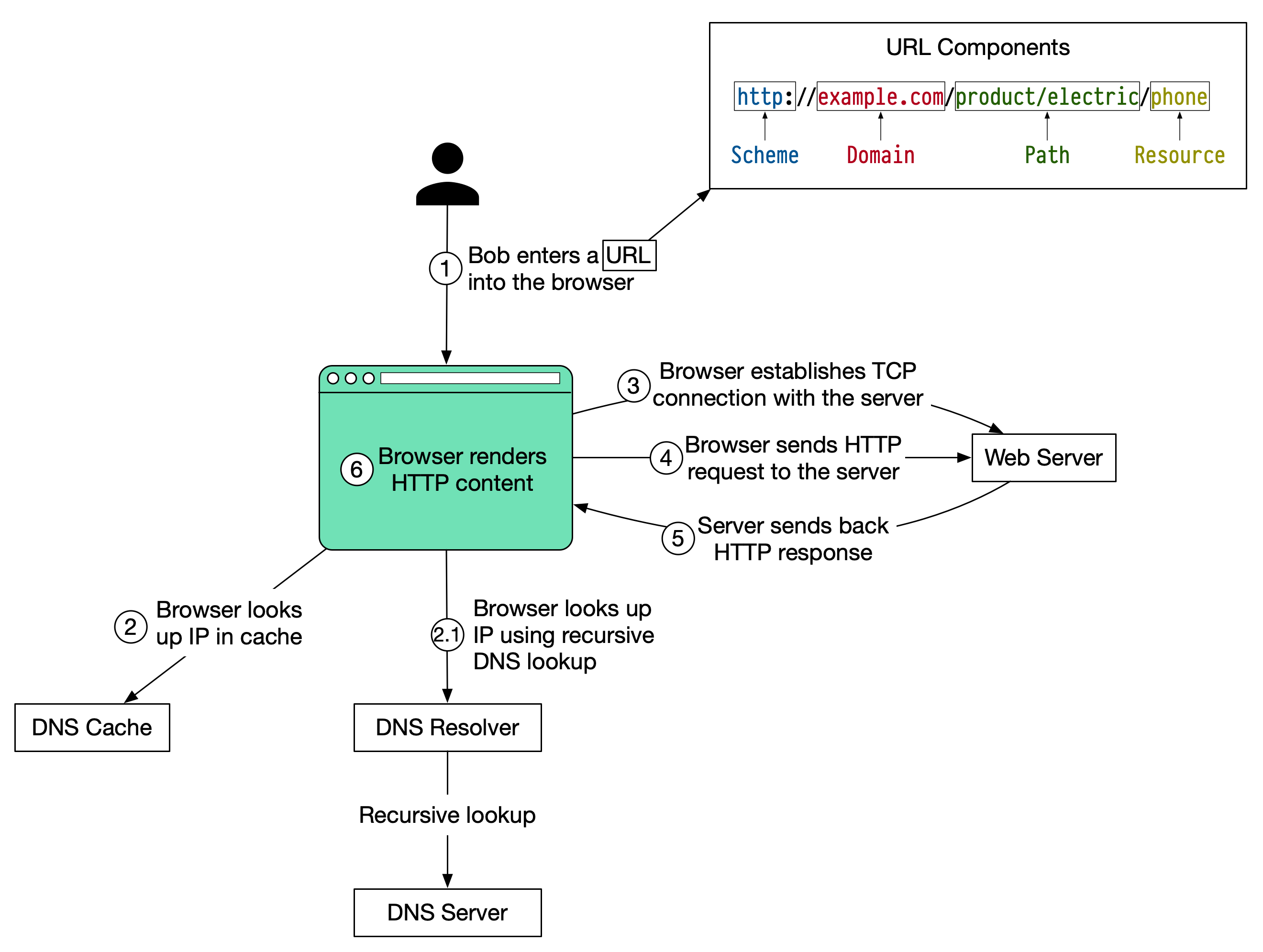
|
||||
|
||||
#### 2. **HTML 解析与 DOM 树生成**
|
||||
|
||||
浏览器接收到 HTML 文件后,进入**解析阶段**,将 HTML 标记解析为**DOM 树**(Document Object Model)。DOM 树是页面结构的抽象表示,每个 HTML 元素对应 DOM 树中的一个节点。浏览器依照 DOM 树的层次结构,组织页面的结构关系。
|
||||
|
||||
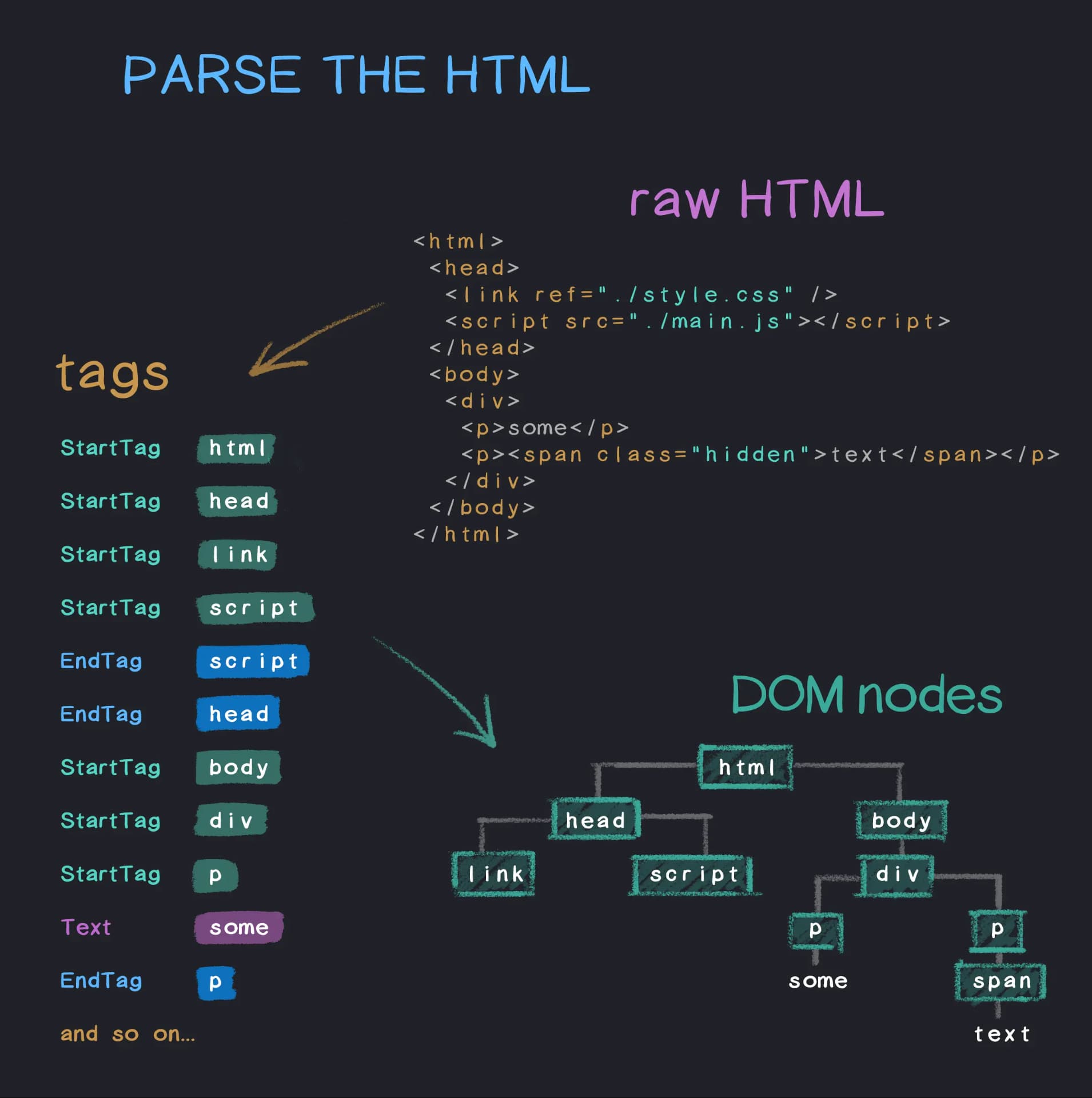
|
||||
|
||||
#### 3. **CSS 解析与 CSSOM 树生成**
|
||||
|
||||
与此同时,浏览器还会解析从服务器或本地缓存获取的 CSS 样式表,生成**CSSOM 树**(CSS Object Model)。CSSOM 树是样式的结构化表示,描述了每个 DOM 元素的样式信息,如字体、颜色、尺寸等。
|
||||
|
||||
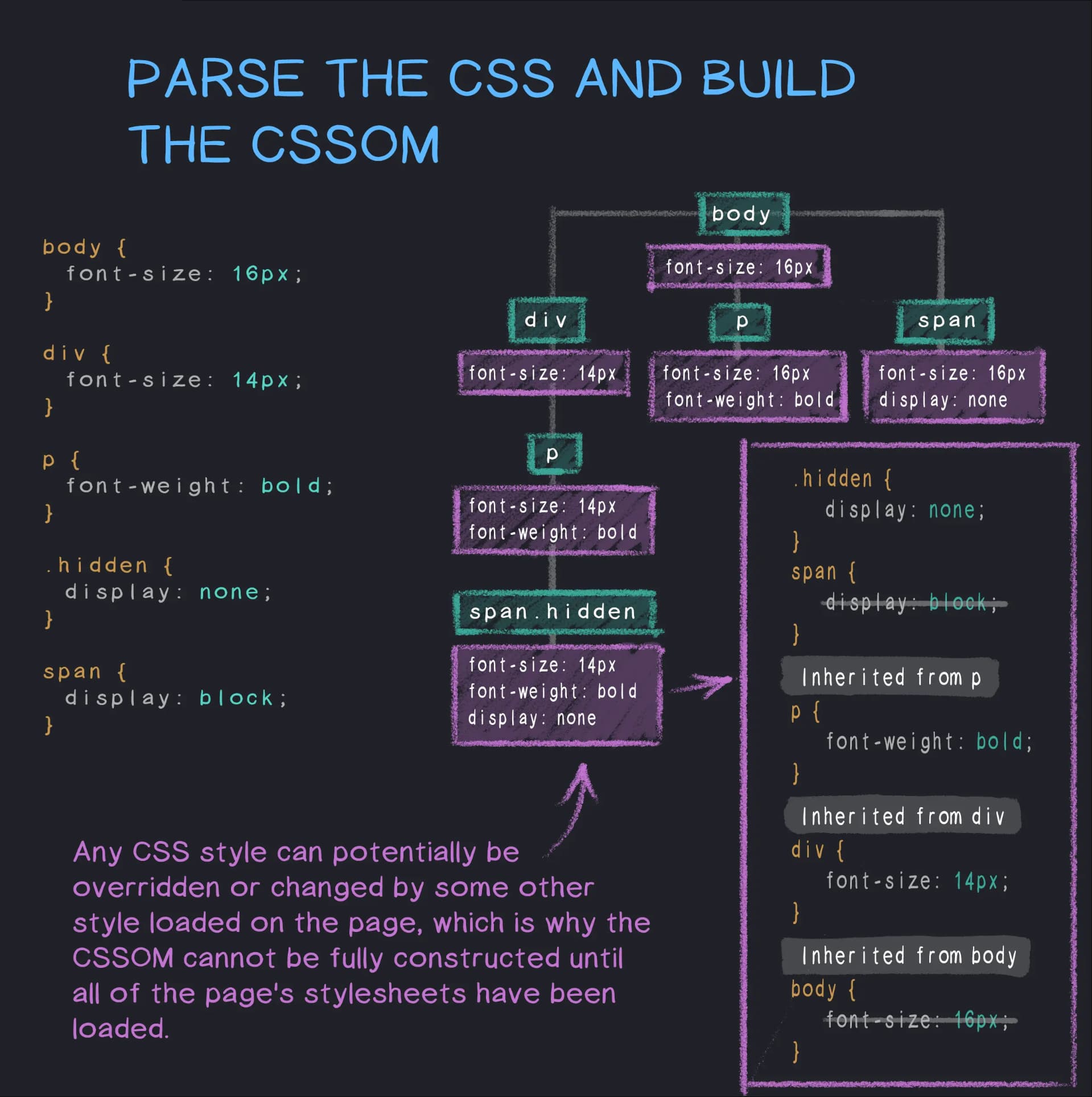
|
||||
|
||||
#### 4. JavaScript 执行
|
||||
|
||||
在页面的解析过程中,浏览器遇到 JavaScript 脚本时,会暂停 HTML 的解析并将脚本交由**JavaScript 引擎**执行。JavaScript 代码可能会修改 DOM 树或 CSSOM 树,因而会影响页面的渲染结果。常见的 JavaScript 引擎包括 Chrome 的**V8**引擎和 Firefox 的**SpiderMonkey**引擎。
|
||||
|
||||
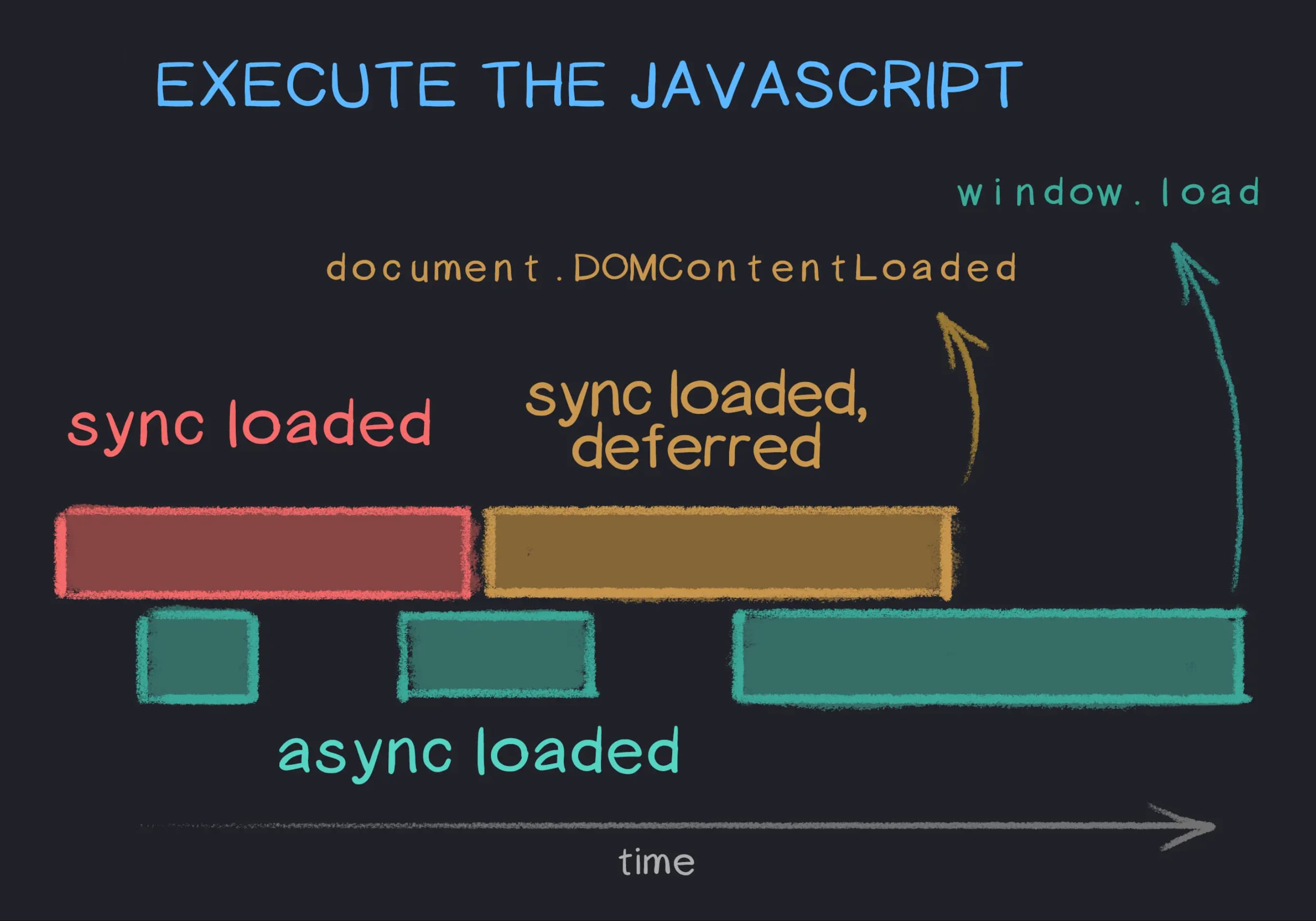
|
||||
|
||||
#### 5. 布局绘制
|
||||
|
||||
浏览器生成完 DOM 树和 CSSOM 树后,下一步是**布局**,即计算每个 DOM 元素的几何位置和大小。布局过程考虑了视口的大小、盒模型(box model)、浮动和定位规则等。布局信息用于指导元素的绘制顺序与空间占用。
|
||||
|
||||
一旦布局完成,浏览器进入**绘制**阶段。在这一阶段,浏览器会根据渲染树中每个元素的几何位置信息,将其样式(如颜色、边框、阴影、背景图片等)绘制到屏幕上。绘制的结果是由图形系统管理的一系列位图或图块(tiles)。
|
||||
|
||||

|
||||
|
||||
#### 6. **合成与渲染**
|
||||
|
||||
绘制后的内容会被分成多个**图层**,这些图层独立存在并由**合成器线程**管理。合成器线程将这些图层**合成**为最终呈现的页面图像。为了提高性能,某些元素(如动画或变换元素)会被放在独立图层中处理,避免频繁的重排和重绘操作。这一过程在 GPU 加速下处理,以确保图像渲染流畅、及时。
|
||||
|
||||
### 渲染树与渲染层
|
||||
|
||||
浏览器通过**渲染树**来表示可见的页面元素,该树由**DOM 树**和**CSSOM 树**相结合生成。渲染树仅包含那些对用户可见的元素,并排除了 `display: none` 等隐藏元素。渲染树是页面渲染的核心数据结构,它直接决定了页面的布局和绘制结果。
|
||||
|
||||
#### DOM 树与 CSSOM 树的结合
|
||||
|
||||
- **DOM 树**表示网页的结构,如标记标签和节点的层级关系。
|
||||
- **CSSOM 树**包含每个节点的样式信息。
|
||||
|
||||
浏览器将 DOM 树和 CSSOM 树结合,生成一个只包含可见节点的渲染树。每个渲染树的节点包含布局计算和绘制所需的全部信息。
|
||||
|
||||
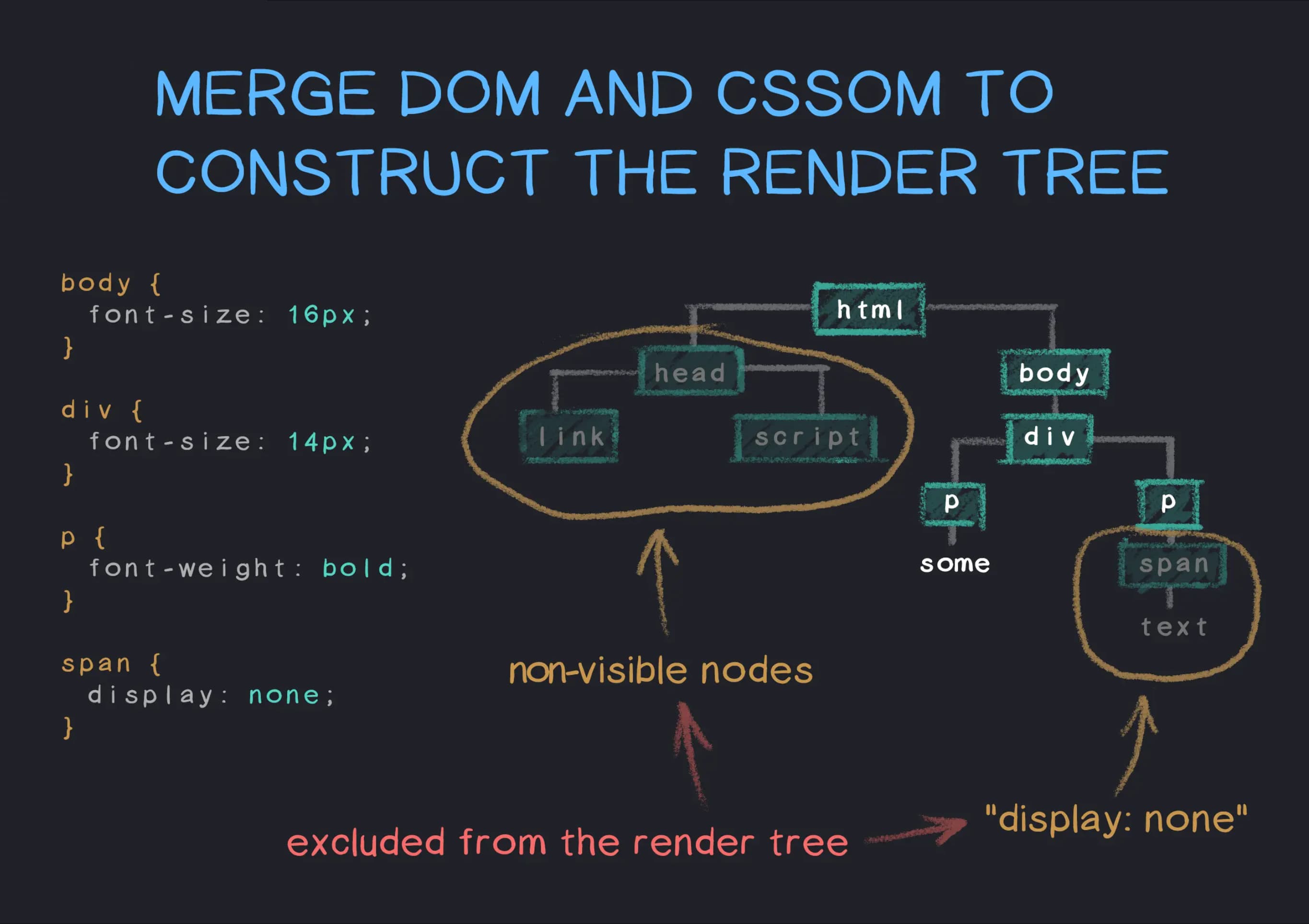
|
||||
|
||||
### 布局与重绘
|
||||
|
||||
渲染树生成后,浏览器继续执行布局和绘制操作。页面的任何样式或结构变化都会触发这些操作。
|
||||
|
||||
#### 1. **布局(Layout)**
|
||||
|
||||
在布局阶段,浏览器计算页面中每个元素的具体位置和尺寸。布局过程非常复杂,涉及元素的盒模型、文档流、浮动、定位等多种因素。任何影响页面结构或尺寸的操作(如添加新元素或调整元素大小)都会触发布局操作。
|
||||
|
||||
#### 2. **重绘(Repaint)**
|
||||
|
||||
当元素的外观属性(如颜色、阴影或背景图片)发生变化,而不会影响其位置或大小时,浏览器会触发**重绘**操作。重绘仅更新元素的视觉外观,不涉及重新计算其布局。虽然重绘比布局轻量,但频繁的重绘也会影响页面性能。
|
||||
|
||||
#### 3. **重排(Reflow)**
|
||||
|
||||
当页面的结构、尺寸或位置发生变化时,浏览器需要重新计算布局,触发**重排**(Reflow)。重排是极为耗费性能的操作,因为它需要重新计算多个元素的布局,并且可能影响整个渲染树的结构。为提升性能,开发者通常会尽量避免频繁触发重排操作,例如减少 DOM 操作或批量更新 DOM 元素。
|
||||
|
||||
## 浏览器的安全机制
|
||||
|
||||
随着互联网的普及,浏览器成为用户与网络互动的核心工具。因此,浏览器不仅需要提供流畅的用户体验,还必须确保用户的安全。为了防止潜在的攻击和数据泄露,现代浏览器引入了多种安全机制,包括同源策略、内容安全策略、沙盒机制等。以下是浏览器常见的安全机制及其实现原理。
|
||||
|
||||
### 同源策略(SOP)
|
||||
|
||||

|
||||
|
||||
#### **同源策略的定义**
|
||||
|
||||
**同源策略**(Same-Origin Policy, SOP)是浏览器中最基础、最重要的安全机制之一,旨在防止恶意网站访问其他站点的资源。根据同源策略,只有同源的网页可以相互访问和操作资源,所谓“同源”是指**协议**、**域名**和**端口号**必须完全一致。
|
||||
|
||||
- **协议**:如 `http://` 和 `https://` 是不同的协议。
|
||||
- **域名**:如 `example.com` 和 `sub.example.com` 不是同源。
|
||||
- **端口号**:如 `http://example.com:80` 和 `http://example.com:8080` 不是同源。
|
||||
|
||||
同源策略的主要目的是防止恶意脚本跨站点攻击,如盗取用户凭据、篡改数据或进行恶意操作。
|
||||
|
||||
#### **CORS(跨源资源共享)**
|
||||
|
||||
尽管同源策略有效阻止了跨域访问,但实际开发中,跨域资源共享是很常见的需求。例如,前端应用通常需要从不同的 API 或服务器获取数据。为了安全地实现跨源访问,浏览器引入了**跨源资源共享**(Cross-Origin Resource Sharing, CORS)机制。
|
||||
|
||||
CORS 允许服务器通过设置适当的 HTTP 头部,显式地告诉浏览器哪些域名、HTTP 方法和请求头可以合法地访问服务器资源。常见的 CORS 头部包括:
|
||||
|
||||
- **Access-Control-Allow-Origin**:指定允许访问的域名或 `*` 表示允许所有域。
|
||||
- **Access-Control-Allow-Methods**:列出允许的 HTTP 方法,如 `GET`、`POST` 等。
|
||||
- **Access-Control-Allow-Headers**:列出允许的自定义请求头。
|
||||
|
||||
CORS 机制不仅增强了灵活性,还确保了跨域访问的安全性。
|
||||
|
||||
### 内容安全策略(CSP)
|
||||
|
||||
#### **CSP 的作用**
|
||||
|
||||
**内容安全策略**(Content Security Policy, CSP)是浏览器用于防范**跨站脚本攻击**(Cross-Site Scripting, XSS)的重要安全机制。XSS 攻击指的是攻击者在网页中注入恶意脚本,从而盗取用户信息或执行恶意操作。CSP 通过定义一组安全策略,控制页面可以加载的资源类型和来源,有效阻止未经授权的脚本或资源执行。
|
||||
|
||||
CSP 策略通过在 HTTP 响应头中添加 `Content-Security-Policy` 字段来实现。常见的 CSP 指令包括:
|
||||
|
||||
- **script-src**:限制可以加载的 JavaScript 脚本来源。
|
||||
- **style-src**:限制可以加载的样式表来源。
|
||||
- **img-src**:限制可以加载的图片资源来源。
|
||||
- **default-src**:为所有类型的资源设置默认来源限制。
|
||||
|
||||
例如,以下 CSP 策略仅允许加载来自同源(self)和特定可信域名的脚本:
|
||||
|
||||
```http
|
||||
Content-Security-Policy: script-src 'self' https://trusted.cdn.com;
|
||||
```
|
||||
|
||||
通过严格的 CSP 配置,开发者可以有效减少网页受到 XSS、点击劫持(Clickjacking)等攻击的风险。
|
||||
|
||||
### 沙盒机制与隔离
|
||||
|
||||
#### **进程隔离与沙盒机制**
|
||||
|
||||
**沙盒机制**是一种重要的浏览器安全防护手段,旨在将浏览器内部的各个组件,如标签页、插件、扩展程序等相互隔离,防止恶意代码影响整个系统。现代浏览器(如 Chrome、Firefox、Edge)采用**多进程架构**,即每个标签页、插件和扩展程序运行在独立的进程中,这样即便某个进程被攻击或崩溃,其他进程仍能继续安全运行。
|
||||
|
||||
具体而言,沙盒机制通过以下方式保障安全:
|
||||
|
||||
- **标签页隔离**:每个标签页运行在独立的进程中,阻止跨站脚本在不同标签页之间传播。
|
||||
- **插件隔离**:插件和扩展程序运行在沙盒中,无法直接访问操作系统资源或文件系统,从而减少安全风险。
|
||||
- **权限管理**:插件和扩展的权限受到严格限制,浏览器通过权限请求机制确保用户知晓并同意插件的操作范围。
|
||||
|
||||
沙盒机制极大地提升了浏览器的安全性和稳定性,防止恶意代码对系统或用户数据造成损害。
|
||||
|
||||
#### **混合内容检测**
|
||||
|
||||
现代浏览器还引入了**混合内容检测**功能,确保 HTTPS 页面只加载安全的内容。所谓混合内容,是指 HTTPS 页面尝试加载不安全的 HTTP 资源(如脚本、图片或样式)。混合内容会导致页面的安全性降低,因为攻击者可能通过不安全的 HTTP 内容发起中间人攻击(MITM)。
|
||||
|
||||
浏览器通常会根据混合内容的类型采取不同的措施:
|
||||
|
||||
- **主动混合内容**(如 HTTP 脚本):浏览器会阻止加载,并向用户发出警告。
|
||||
- **被动混合内容**(如 HTTP 图片):浏览器可能允许加载,但会显示“不完全安全”的提示。
|
||||
|
||||
通过阻止不安全资源,浏览器能够保证 HTTPS 页面的完整性,防止敏感数据泄露或遭受攻击。
|
||||
|
||||
## 浏览器的前沿技术
|
||||
|
||||
随着 Web 技术的快速发展,现代浏览器已不再局限于传统的静态网页浏览,而是逐步向更为复杂、功能丰富的应用平台演进。为了支持这一转变,浏览器引入了多项前沿技术,如**渐进式 Web 应用(PWA)**和**WebAssembly(WASM)**,这些技术赋予 Web 应用接近原生应用的体验和性能优势。
|
||||
|
||||
### 渐进式 Web 应用(PWA)
|
||||
|
||||
**渐进式 Web 应用**(Progressive Web App, PWA)是一种旨在结合 Web 与原生应用优势的新型 Web 应用模式。PWA 通过现代 Web API 提供类似于原生应用的体验,包括离线使用、推送通知、快速加载等特性,确保用户即使在不稳定的网络环境下,依然可以流畅使用 Web 应用。
|
||||
|
||||
#### **Service Workers**
|
||||
|
||||
**Service Workers**是 PWA 的核心技术,提供了一层独立于 Web 页面的后台脚本,负责管理网络请求、缓存资源、离线支持和后台任务。它们通过拦截网络请求,实现灵活的缓存策略,从而加速页面加载速度并提供离线访问功能。
|
||||
|
||||
- **缓存管理**:Service Workers 可以根据预定义的规则缓存静态资源(如 HTML、CSS、JavaScript、图片等),从而减少重复请求,提升页面加载速度。
|
||||
- **离线支持**:在网络连接不稳定或断开时,Service Workers 可以提供缓存的内容,使用户即使离线也能使用部分功能。
|
||||
- **后台同步**:Service Workers 还支持后台同步功能,即在网络恢复后,自动发送先前存储的请求,实现数据的自动同步。
|
||||
|
||||
```javascript
|
||||
self.addEventListener('fetch', event => {
|
||||
event.respondWith(
|
||||
caches.match(event.request).then(response => {
|
||||
return response || fetch(event.request);
|
||||
})
|
||||
);
|
||||
});
|
||||
```
|
||||
|
||||
#### **Manifest 文件**
|
||||
|
||||
**Manifest 文件**为 PWA 提供了原生应用般的安装体验。它是一个 JSON 文件,用于定义 Web 应用的外观和行为。通过配置 Manifest 文件,开发者可以控制 PWA 的启动方式、图标、主题颜色以及全屏显示等行为。用户可以通过浏览器将 PWA 安装到设备的主屏幕,并像本地应用一样打开它。
|
||||
|
||||
Manifest 文件的常见字段包括:
|
||||
|
||||
- **name**:应用名称。
|
||||
- **icons**:定义应用图标的路径和不同分辨率。
|
||||
- **start_url**:定义应用启动时的默认 URL。
|
||||
- **display**:控制应用启动后的显示模式(如 `fullscreen`、`standalone`)。
|
||||
- **background_color** 和 **theme_color**:定义启动画面和主题颜色。
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "My PWA App",
|
||||
"icons": [
|
||||
{
|
||||
"src": "icon-192x192.png",
|
||||
"sizes": "192x192",
|
||||
"type": "image/png"
|
||||
}
|
||||
],
|
||||
"start_url": "/index.html",
|
||||
"display": "standalone",
|
||||
"theme_color": "#3367D6",
|
||||
"background_color": "#ffffff"
|
||||
}
|
||||
```
|
||||
|
||||
通过 Service Workers 和 Manifest 文件,PWA 应用可以离线运行、快速加载,并为用户提供接近原生应用的使用体验。
|
||||
|
||||
### WebAssembly(WASM)
|
||||
|
||||
**WebAssembly**(WASM)是一种全新的二进制格式,旨在让高性能的编程语言(如 C、C++、Rust 等)编译后在浏览器中运行。与 JavaScript 相比,WebAssembly 具有接近原生代码的执行效率,特别适合执行复杂的计算任务,如视频处理、3D 渲染、数据分析和游戏开发等。
|
||||
|
||||
#### **WebAssembly 简介**
|
||||
|
||||
WebAssembly 是一种低级别的字节码,浏览器通过高效的虚拟机直接执行它。不同于传统的 JavaScript 脚本,WebAssembly 在设计上强调性能优化,尤其是它的可预测性和跨平台特性,使得它在不同设备上都能快速、安全地执行。
|
||||
|
||||
WebAssembly 的主要优势包括:
|
||||
|
||||
- **高性能**:WebAssembly 代码的执行接近原生速度,适合对性能要求极高的应用场景,如游戏引擎、图形处理和音视频编辑等。
|
||||
- **可移植性**:WebAssembly 与平台无关,可以在各大主流浏览器(Chrome、Firefox、Safari 等)上运行,保证了代码的跨平台兼容性。
|
||||
|
||||
#### **与 JavaScript 的互操作**
|
||||
|
||||
WebAssembly 并不是用来完全取代 JavaScript,而是与其配合使用。Web 开发者可以利用 WebAssembly 执行性能敏感的任务,同时仍然依赖 JavaScript 处理页面交互、DOM 操作等业务逻辑。WebAssembly 模块可以被 JavaScript 直接调用,并与之交换数据。
|
||||
|
||||
```javascript
|
||||
// 加载和实例化WASM模块
|
||||
fetch('example.wasm').then(response =>
|
||||
response.arrayBuffer()
|
||||
).then(bytes =>
|
||||
WebAssembly.instantiate(bytes)
|
||||
).then(results => {
|
||||
const instance = results.instance;
|
||||
console.log(instance.exports.add(1, 2)); // 调用WASM中的函数
|
||||
});
|
||||
```
|
||||
|
||||
在这个示例中,WebAssembly 模块中定义的函数可以被 JavaScript 调用,并返回计算结果。这种互操作使开发者可以使用诸如 C、C++ 或 Rust 等语言编写复杂的算法或高性能代码,然后在浏览器中通过 JavaScript 无缝地调用这些模块。
|
||||
|
||||
#### **应用场景**
|
||||
|
||||
WebAssembly 的典型应用场景包括:
|
||||
|
||||
- **游戏开发**:借助 WebAssembly 的高性能,开发者可以将现有的桌面游戏移植到 Web 平台,实现流畅的 3D 渲染和复杂的物理计算。
|
||||
- **多媒体处理**:WebAssembly 可以用于音频和视频编解码、图像处理等需要大量计算的任务,提供接近原生应用的性能。
|
||||
- **科学计算与数据分析**:WebAssembly 在大规模数据处理、机器学习推理等领域也有着广泛的应用前景。
|
||||
565
Technology/WebDevelopment/1.Browser/2.Chrome.md
Normal file
565
Technology/WebDevelopment/1.Browser/2.Chrome.md
Normal file
@ -0,0 +1,565 @@
|
||||
---
|
||||
title: Chrome
|
||||
description: Google Chrome 浏览器自2008年发布以来,以其快速、安全、稳定和简洁的用户界面获得广泛使用。基于开源项目Chromium,Chrome支持多进程架构、扩展程序和跨平台兼容,拥有超过60%的市场份额。它还推动了浏览器技术的发展,如V8引擎、Blink渲染引擎、沙盒安全模型,以及对前沿技术如PWA和WebAssembly的支持。
|
||||
keywords:
|
||||
- Chrome
|
||||
- Chromium
|
||||
- 浏览器
|
||||
- 多进程架构
|
||||
- 扩展程序
|
||||
- PWA
|
||||
- WebAssembly
|
||||
tags:
|
||||
- 技术/WebDev
|
||||
- WebDev/Browser
|
||||
author: 仲平
|
||||
date: 2024-09-30
|
||||
---
|
||||
|
||||
## Chrome
|
||||
|
||||
### 概述与特点
|
||||
|
||||
#### 诞生背景
|
||||
|
||||
Google Chrome 浏览器首次发布于 2008 年 9 月,是由 Google 开发的一款免费网络浏览器。其设计初衷是为了提供更快速、稳定和安全的浏览体验。Chrome 的开发基于开源项目**Chromium**,这不仅保证了开发的透明度和社区的贡献,还促使它成为现代浏览器的技术基石之一。自发布以来,Chrome 迅速获得了全球用户的青睐,并成为当前市场上最广泛使用的浏览器之一。
|
||||
|
||||
#### 核心特性
|
||||
|
||||
- **速度**:Chrome 因其优异的性能和快速的网页加载能力而广受好评。其性能优势主要来自于高效的**V8 JavaScript 引擎**和**Blink 渲染引擎**。V8 引擎能够快速编译和执行 JavaScript 代码,而 Blink 渲染引擎负责页面的布局、渲染和绘制,这二者协同作用使 Chrome 在页面加载速度和响应能力上表现出色。
|
||||
- **简洁的用户界面**:Chrome 以其极简主义的设计风格著称,提供了简洁的用户界面,使用户可以专注于内容本身。Chrome 的设计思路是去除多余的工具栏和按钮,最大化显示网页内容,提升用户的浏览体验。
|
||||
- **多进程架构**:Chrome 率先采用了**多进程架构**,即每个标签页、插件以及渲染进程都独立运行。这种设计极大地提升了浏览器的稳定性和安全性。即使一个标签页崩溃,其他标签页依然可以正常运行,避免了浏览器整体崩溃的情况。此外,独立进程为每个页面提供了隔离,增强了浏览器的安全性,防止恶意网站对系统产生威胁。
|
||||
- **扩展支持**:Chrome 拥有丰富的扩展生态系统。用户可以通过 Chrome Web Store 下载并安装各种扩展程序,扩展程序能够大幅增强浏览器的功能,例如广告拦截、开发者工具、自动填充表单等。Chrome 的扩展系统基于 JavaScript、HTML 和 CSS 等 Web 技术,便于开发者构建并发布。
|
||||
- **跨平台兼容**:Chrome 可以在多种操作系统上运行,包括**Windows**、**macOS**、**Linux**、**Android**和**iOS**,并且提供一致的用户体验。无论是在桌面还是移动端,用户都可以享受同样流畅的浏览体验,这得益于 Chrome 对跨平台兼容性的支持。
|
||||
- **同步功能**:Chrome 允许用户通过 Google 账号实现跨设备的**数据同步**。用户只需登录 Google 账号,便可以同步书签、浏览历史记录、扩展程序和设置等内容,从而无缝衔接桌面和移动设备上的浏览体验。这一功能特别方便频繁在不同设备间切换的用户,提供了极高的便利性。
|
||||
|
||||
#### 市场份额
|
||||
|
||||
**根据多项权威的市场分析报告,Google Chrome 自发布以来迅速占据了全球浏览器市场的主导地位。** 截至目前,Chrome 在桌面和移动端的全球市场份额常年稳居第一,拥有超过 60% 的市场占有率。这一现象得益于 Chrome 持续的技术创新和用户体验的提升。Chrome 不仅在速度、稳定性和安全性方面表现出色,还在功能扩展和跨平台支持等领域提供了极大的便利,使其成为用户的首选浏览器。
|
||||
|
||||
### Chrome 与 Chromium 的关系
|
||||
|
||||
#### Chromium 项目
|
||||
|
||||
**Chromium 是 Google 主导的一个开源浏览器项目,Chrome 的开发正是基于此项目。** Chromium 作为开源项目,提供了所有 Chrome 浏览器的核心技术和渲染引擎,但它不包含某些 Google 特有的服务和功能,例如**自动更新**、内置的**Flash 插件**、某些视频编解码器的支持(如 AAC 和 H.264)以及 Chrome 专属的用户数据同步功能。由于 Chromium 是完全开源的,任何开发者都可以基于 Chromium 的代码进行修改和重新发布。
|
||||
|
||||
#### 其他基于 Chromium 的浏览器
|
||||
|
||||
许多现代浏览器都基于 Chromium 项目进行开发,利用其强大的渲染引擎和底层技术。这些浏览器在保留了 Chromium 的性能和安全特性的同时,根据各自的需求对功能和界面进行了定制。其中较为知名的浏览器包括:
|
||||
|
||||
- **Microsoft Edge**:在转向 Chromium 内核后,Edge 获得了更好的网页兼容性和性能表现,同时保留了 Microsoft 独特的服务集成(如与 Windows 系统的深度整合)。
|
||||
- **Opera**:Opera 基于 Chromium 开发,但提供了其特有的功能,如内置的广告拦截、VPN 服务和侧边栏快速访问功能。
|
||||
- **Brave**:Brave 主打隐私保护,基于 Chromium 构建,并在默认情况下屏蔽广告和跟踪器,同时引入了其独特的奖励系统(BAT),鼓励用户和内容创作者。
|
||||
|
||||
这种基于 Chromium 的浏览器生态系统的繁荣,进一步验证了 Chromium 项目的开放性和强大的技术基础。尽管这些浏览器在用户体验和功能集成方面各有特色,但它们共享了 Chromium 的核心技术,确保了与现代网页标准的兼容性和良好的性能表现。
|
||||
|
||||
## Chrome 历史发展
|
||||
|
||||
### Chrome 的发布与早期发展(2008-2010)
|
||||
|
||||
#### 首次发布
|
||||
|
||||
Google Chrome 于 2008 年 9 月推出了第一个测试版,首次发布仅支持 Windows 平台。Chrome 的推出引发了广泛关注,它标志着 Google 进军浏览器市场的开始。与当时主流的浏览器(如 Internet Explorer 和 Firefox)相比,Chrome 的设计哲学是提供**更快**、**更稳定**和**更安全**的浏览体验。Chrome 通过引入先进的**V8 JavaScript 引擎**和**多进程架构**,让其在速度和稳定性方面领先于竞争对手。
|
||||
|
||||
#### 开源项目 Chromium
|
||||
|
||||
与 Chrome 发布同步,Google 还推出了**Chromium**项目,作为 Chrome 的开源基础。Chromium 为开发者和社区提供了浏览器的核心代码。Google 发布的 Chrome 在 Chromium 的基础上,加入了一些专有组件,如**自动更新机制**和**Adobe Flash 插件支持**,这些是开源版本所不具备的。
|
||||
|
||||
Chrome 的独特架构也为浏览器带来了显著的性能提升,特别是**独立标签页崩溃保护**。通过多进程模型,Chrome 确保每个标签页独立运行,这意味着即使一个标签页崩溃,其他标签页也不会受到影响,从而极大地提高了浏览器的稳定性。
|
||||
|
||||
#### 市场影响
|
||||
|
||||
发布后不久,Chrome 的市场占有率快速攀升。其简洁的界面设计、卓越的性能以及与 Google 生态系统的深度集成,吸引了大量用户。短短几个月内,Chrome 成功从一个新兴浏览器发展为一个强有力的竞争者,并在几年内迅速获得了数百万的用户。至 2010 年,Chrome 已经成为全球第三大浏览器,仅次于 Internet Explorer 和 Firefox。
|
||||
|
||||
### Chrome 的快速迭代与功能扩展(2011-2015)
|
||||
|
||||
#### 引入扩展支持
|
||||
|
||||
2010 年,Chrome 推出了**扩展支持**,允许用户通过安装扩展程序来自定义浏览器的功能。这项功能彻底改变了用户与浏览器的交互方式,开发者也可以基于 Chrome 的扩展框架开发功能丰富的工具。通过这些扩展,用户可以轻松实现广告拦截、自动化任务和页面定制等功能,极大地增强了浏览器的灵活性。
|
||||
|
||||
#### 跨平台支持
|
||||
|
||||
Chrome 的成功不仅局限于 Windows 平台。2010 年,Google 发布了**macOS**和**Linux**版本,进一步扩大了用户群体。2012 年,Chrome 正式登陆**Android**平台,并迅速成为移动设备上的主流浏览器之一。这标志着 Chrome 进入了移动互联网的新时代,并通过跨设备的数据同步功能,提供了一致且无缝的用户体验。
|
||||
|
||||
#### Chrome Web Store 的发布
|
||||
|
||||
2011 年,Google 推出了**Chrome Web Store**,一个集中化的扩展市场,用户可以在这里下载和安装扩展、主题以及应用程序。该平台不仅为用户提供了丰富的选择,还推动了开发者社区的发展,使得 Chrome 的功能生态系统得以快速扩展。
|
||||
|
||||
#### 浏览器性能的持续提升
|
||||
|
||||
随着网络应用复杂性的不断提高,Google 持续优化 Chrome 的性能。Chrome 团队在 2011 至 2015 年间对**启动速度**、**内存占用**以及**JavaScript 引擎性能**进行了一系列改进,使其在各大基准测试中长期占据领先地位。尤其是**V8 JavaScript 引擎**的不断优化,使得 Chrome 成为了前端开发者首选的开发与测试平台。
|
||||
|
||||
### Chrome 的现代化演变(2016- 至今)
|
||||
|
||||
#### Material Design 风格引入
|
||||
|
||||
2016 年,Chrome 的界面设计进行了重大更新,正式引入了 Google 的**Material Design**设计语言。这一改动带来了更简洁的视觉风格和更加一致的用户体验。Material Design 的引入不仅优化了 Chrome 的外观,还提升了用户的操作流畅性,使得浏览体验更加直观和友好。
|
||||
|
||||
#### 对 HTTP 的安全改进
|
||||
|
||||
Google 一直致力于提高 Web 的安全性。自 2017 年起,Chrome 开始对**未使用 SSL 加密**的 HTTP 网站标注为“不安全”。这一举措是推动 Web 安全转型的重要一步,促使大量网站转向更安全的**HTTPS 协议**。Chrome 对安全性的不懈追求,加速了整个互联网向加密通信的转变,提升了用户的隐私保护和数据安全。
|
||||
|
||||
#### 逐步淘汰 Flash
|
||||
|
||||
Chrome 对**Adobe Flash**的支持逐步减少,并最终于 2020 年完全停止支持。这一决定反映了 Web 技术的演变趋势,Google 希望通过淘汰 Flash,推动更现代化的 Web 标准(如**HTML5**和**WebAssembly**)的应用,提升 Web 的开放性、安全性和性能。
|
||||
|
||||
#### Chrome DevTools 的扩展与强化
|
||||
|
||||
Chrome 不仅作为用户浏览器表现卓越,作为开发工具也同样功能强大。**Chrome DevTools**随着时间的推移不断扩展,增加了对前端开发者至关重要的功能,如**JavaScript 调试**、**网络请求分析**、**性能监控**以及**渐进式 Web 应用(PWA)** 的调试支持。Chrome DevTools 的进步,使得开发者能够更高效地分析和优化网页性能,提升开发效率。
|
||||
|
||||
#### 移动端的持续扩展与优化
|
||||
|
||||
随着移动互联网的兴起,Chrome 在移动端的表现也愈发重要。Google 通过优化**移动端浏览器的性能**、改进触屏交互以及增强**跨设备同步功能**,使用户能够在不同设备间无缝切换,进一步提升了跨平台浏览体验的流畅度。
|
||||
|
||||
#### 持续的性能优化与创新
|
||||
|
||||
Chrome 通过不断引入新技术和优化现有功能,保持了其在浏览器市场的技术领先地位。例如,**内存管理优化**和**标签页冻结**功能,减少了不活跃标签页的资源占用,大幅提高了整体性能。V8 JavaScript 引擎的持续优化、对**WebAssembly**的支持等,也为现代 Web 应用提供了强大的运行时性能,进一步推动了浏览器在复杂应用场景中的应用。
|
||||
|
||||
## Chrome 的架构
|
||||
|
||||
### 多进程架构的概述
|
||||
|
||||
**Chrome 的多进程架构设计是其性能、稳定性和安全性的重要基石。** 与传统的单进程浏览器模型不同,Chrome 将不同的浏览器任务分配给多个独立的进程,从而提升了浏览器的稳定性和安全性。具体来说,Chrome 的多进程模型可以划分为以下几类进程:
|
||||
|
||||
- **浏览器进程**:浏览器进程是整个浏览器的主进程,负责管理用户界面(UI)、网络请求、文件存储以及控制浏览器窗口和标签页的操作。它还处理用户的输入(如点击、键盘输入)并负责协调其他子进程之间的通信。
|
||||
- **渲染进程**:每个标签页都会有一个独立的渲染进程,负责渲染页面内容。渲染进程处理 HTML、CSS 解析、JavaScript 执行和页面布局等任务。为了保证安全,渲染进程通常在**沙盒**中运行,这意味着它被隔离在一个有限的权限环境中,无法直接访问操作系统的关键资源,防止恶意网页或代码对系统造成破坏。
|
||||
- **GPU 进程**:GPU 进程专门负责处理与图形相关的任务,包括页面的图层合成和硬件加速绘制。这使得页面内容能够以更高效的方式呈现,尤其是对于需要大量图形处理的页面(如 3D 图形或动画),GPU 加速能显著提高渲染性能。
|
||||
- **插件进程**:Chrome 为每个插件分配独立的插件进程,确保即使插件崩溃,也不会影响其他标签页或整个浏览器的运行。这种隔离机制同样提高了浏览器的稳定性。
|
||||
- **扩展进程**:Chrome 的扩展运行在独立的扩展进程中,与页面内容隔离。这不仅提高了浏览器的安全性,还能保证扩展不会干扰页面的正常运行。
|
||||
|
||||
### 多进程架构的优缺点
|
||||
|
||||
**优点**
|
||||
|
||||
- **稳定性**:Chrome 的多进程架构显著提升了浏览器的稳定性。每个标签页、插件和扩展都在各自的进程中运行,因此即使一个标签页崩溃,其他标签页和浏览器本身仍然可以正常工作。此外,独立的插件进程避免了插件崩溃导致整个浏览器崩溃的风险。
|
||||
- **安全性**:Chrome 通过**进程隔离**和**沙盒技术**提高了浏览器的安全性。每个渲染进程在沙盒中运行,这限制了进程对操作系统的访问权限,降低了恶意代码攻击系统的风险。即使某个标签页被恶意攻击,攻击者也难以利用其控制整个系统。
|
||||
- **并行处理**:多进程架构允许 Chrome 更好地利用现代多核 CPU。由于多个进程可以并发执行,Chrome 能够更高效地处理多个标签页的加载、渲染和执行任务,提升浏览器的整体性能。
|
||||
|
||||
**缺点**
|
||||
|
||||
- 内存占用较高:由于每个进程都有自己的独立内存空间,多进程架构导致了内存使用的显著增加。尤其是在同时打开多个标签页时,每个标签页分配一个独立的渲染进程会占用更多的内存资源。虽然多进程模型带来了稳定性和安全性,但相对于单进程浏览器,它对系统的内存消耗更大。
|
||||
|
||||
### 沙盒安全模型
|
||||
|
||||
**沙盒模型**是 Chrome 实现浏览器安全的重要机制之一。它通过将渲染进程置于受限环境中,减少了恶意网页对系统的潜在威胁。
|
||||
|
||||
- **渲染进程沙盒**:Chrome 中的渲染进程运行在沙盒中,这意味着即使渲染进程处理恶意网页,也无法直接访问操作系统的敏感资源或文件。沙盒通过限制系统调用、文件访问等权限,保护用户系统免受来自网页的潜在攻击。沙盒机制确保了即使网页中的 JavaScript 或恶意代码试图执行危险操作,这些操作也会被阻止,保证用户系统的安全。
|
||||
- **进程间通信(IPC)**:Chrome 的多进程架构依赖于**IPC(进程间通信)** 机制来实现各进程之间的数据交换。浏览器进程、渲染进程、GPU 进程等通过 IPC 协议进行通信。例如,当用户在浏览器地址栏输入网址时,浏览器进程会将请求传递给渲染进程,渲染进程完成页面加载和渲染后,再通过 IPC 将结果返回。IPC 的设计确保了即使进程之间彼此隔离,它们仍能高效合作。
|
||||
|
||||
## Chrome 的渲染机制
|
||||
|
||||
### 从输入 URL 到页面渲染的详细过程
|
||||
|
||||
当用户在浏览器地址栏中输入 URL 并按下回车键时,浏览器将开始一系列复杂的过程,从网络请求到页面渲染完成。下面是详细的步骤说明:
|
||||
|
||||
#### 浏览器请求阶段
|
||||
|
||||
- **DNS 解析**:浏览器首先通过 DNS(域名系统)将用户输入的域名转换为服务器的 IP 地址。如果该域名对应的 IP 地址已被缓存,浏览器可以直接使用缓存中的结果。否则,浏览器会通过 DNS 服务器查询 IP 地址。
|
||||
- **建立连接**:获取 IP 地址后,浏览器与服务器建立 TCP 连接。如果是 HTTPS 请求,还需进行**TLS 握手**来加密通信。通常,TCP 连接会通过三次握手来建立。
|
||||
- **发送 HTTP 请求**:连接建立后,浏览器会发起 HTTP 请求,请求的内容包括 HTML 文档及其引用的资源(如 CSS、JavaScript、图片等)。
|
||||
- **接收响应**:服务器处理请求后,返回 HTTP 响应,其中包含了请求的 HTML 文档和其他资源的 URL。浏览器根据这些资源的类型进一步请求它们,以便完成页面渲染。
|
||||
|
||||
#### 渲染流程概述
|
||||
|
||||
浏览器接收到 HTML 文档和其他资源后,开始进入渲染流程,即将网络传输的字节转换为屏幕上可见的内容。该过程包括以下几个阶段:
|
||||
|
||||
- **解析 HTML 生成 DOM 树**:浏览器解析 HTML 文档并逐步生成**DOM 树**(Document Object Model)。DOM 树是页面的内部表示,它以树结构描述页面的内容和元素关系,每个 HTML 标签对应 DOM 树中的一个节点。
|
||||
- **解析 CSS 生成 CSSOM 树**:浏览器解析外部和内联的 CSS 样式,生成**CSSOM 树**(CSS Object Model)。CSSOM 树代表页面中的所有样式规则,描述了每个 DOM 元素的样式属性。
|
||||
- **合成渲染树**:浏览器将**DOM 树**和**CSSOM 树**结合起来生成**渲染树**(Render Tree)。渲染树包含页面中的所有可见元素,并应用其样式。与 DOM 树不同,渲染树只包含需要显示的内容,诸如 `<head>` 标签或带有 `display: none` 样式的元素不会被包括在内。
|
||||
- **布局(Layout)**:渲染树生成后,浏览器开始进行**布局**计算,也称为 " 回流 "。在此步骤中,浏览器计算每个元素的具体大小和位置。布局过程基于 CSS 盒模型,通过对渲染树进行遍历来确定元素的几何属性,如宽度、高度、相对位置等。
|
||||
- **绘制(Painting)**:完成布局后,浏览器将**绘制**页面的内容。绘制包括文本、颜色、背景、边框、阴影等各类视觉样式。此时,渲染树中的元素被绘制成位图。
|
||||
- **合成与图层管理(Compositing)**:页面中可能有多个图层(如浮动的元素、动画等),这些图层需要由**合成器线程**进行合成处理。合成器将这些图层组合成最终的页面视图,并通过 GPU 进行硬件加速渲染,从而提高渲染性能,尤其是复杂页面的绘制效率。
|
||||
|
||||
### Chrome 的 Blink 渲染引擎
|
||||
|
||||
#### Blink 引擎概述
|
||||
|
||||
**Blink**是 Google Chrome 使用的渲染引擎,它是从 WebKit 渲染引擎的一个分支,专门用于处理 HTML、CSS、JavaScript 等 Web 内容,并将其转化为屏幕上可见的页面。Blink 的高效性和现代化设计使得 Chrome 具备了快速的页面加载和渲染能力。
|
||||
|
||||
#### 渲染树的生成与作用
|
||||
|
||||
- **渲染树生成**:Blink 通过解析 DOM 树和 CSSOM 树来生成**渲染树**。渲染树只包含可见的页面元素及其样式,因此相比 DOM 树,渲染树结构更加精简且高效。
|
||||
- **渲染树的作用**:渲染树是后续布局和绘制过程的基础。它提供了每个可见元素的样式和层次关系,供浏览器在布局计算和最终绘制时使用。Blink 通过对渲染树的处理,将页面内容准确地呈现给用户。
|
||||
|
||||
#### 合成器线程(Compositor Thread)
|
||||
|
||||
为了提高渲染性能,Blink 引入了**合成器线程**。合成器线程专门处理图层的合成任务,避免主线程(负责执行 JavaScript 和处理页面逻辑)因繁重的渲染任务而被阻塞。合成器线程通过协调各个图层的绘制,确保页面即使在存在复杂动画或大量图层时,仍能流畅地进行渲染。
|
||||
|
||||
### V8 JavaScript 引擎
|
||||
|
||||
**V8**是 Chrome 中的 JavaScript 引擎,负责将 JavaScript 代码转换为机器码并执行。作为一款高性能引擎,V8 在 JavaScript 的执行效率、内存管理和性能优化上有许多先进的设计。
|
||||
|
||||
#### 即时编译(JIT,Just-in-Time)
|
||||
|
||||
V8 采用了**即时编译**(JIT)技术,通过将 JavaScript 代码在执行时即时编译为机器码,避免了传统解释器逐行解释执行代码的低效问题。JIT 编译大大提升了 JavaScript 的执行速度,使得现代 Web 应用中的 JavaScript 代码能够在浏览器中快速运行。
|
||||
|
||||
#### 垃圾回收机制
|
||||
|
||||
V8 通过**分代式垃圾回收**(Generational Garbage Collection)来管理内存。分代垃圾回收将内存中的对象分为“新生代”和“老生代”两个区域。新生代对象是刚刚创建的对象,回收频率较高,而老生代对象则是存活时间较长的对象。通过对新生代对象进行快速清理,并采用更复杂的策略回收老生代对象,V8 能够有效降低内存泄漏,并保证应用的平稳运行。
|
||||
|
||||
## Chrome 的性能优化
|
||||
|
||||
优化 Chrome 浏览器中的页面性能和网络性能是提升用户体验和提高应用响应速度的关键。在现代 Web 开发中,合理管理关键渲染路径、减少不必要的 DOM 操作、以及充分利用网络协议和缓存机制,能够显著提高 Web 应用的整体表现。
|
||||
|
||||
### 页面性能优化
|
||||
|
||||
**页面性能优化的核心在于减少渲染的阻塞、减少 DOM 操作的开销,以及最大限度地优化资源加载和渲染流程。**
|
||||
|
||||
#### 关键渲染路径优化
|
||||
|
||||
**关键渲染路径**(Critical Rendering Path)是浏览器从获取 HTML 文件到将页面内容呈现在屏幕上的一系列步骤。为了加快页面渲染速度,开发者应尽量减少阻塞渲染的关键资源,并异步加载非必要的资源。
|
||||
|
||||
- **减少阻塞资源**:CSS 和 JavaScript 文件会阻塞页面的渲染,尤其是位于页面头部的资源。为了优化关键渲染路径,可以使用 `<link rel="preload">` 预加载关键资源,减少首次渲染时间。
|
||||
- **异步加载 JavaScript**:使用 `async` 或 `defer` 属性加载 JavaScript 文件。`async` 属性允许脚本并行下载并尽快执行,而 `defer` 则在 HTML 解析完成后才执行脚本,避免阻塞页面的渲染。
|
||||
|
||||
```javascript
|
||||
<script src="script.js" async></script>
|
||||
<script src="deferred.js" defer></script>
|
||||
```
|
||||
|
||||
- **CSS 优化**:将关键的 CSS 直接内联到 HTML 文件中,减少渲染的阻塞时间。对于非关键 CSS 文件,使用 `media` 属性延迟其加载。
|
||||
|
||||
```html
|
||||
<link rel="stylesheet" href="style.css" media="print" onload="this.media='all'">
|
||||
```
|
||||
|
||||
#### 减少重绘与回流
|
||||
|
||||
- **重绘(Repaint)**:发生在元素的视觉外观发生改变时,例如颜色、背景或阴影变化,但不影响其布局。重绘虽然比回流开销小,但仍然影响性能。
|
||||
- **回流(Reflow)**:回流是布局的重新计算,发生在元素的大小、位置或结构发生改变时,需要重新计算渲染树。回流比重绘开销大,频繁的回流会显著影响性能。
|
||||
|
||||
优化策略:
|
||||
|
||||
- **减少 DOM 操作**:频繁修改 DOM 会引发回流。应尽量避免多次操作 DOM,代之以**批量操作**。例如,使用 `DocumentFragment` 来集中处理多次 DOM 修改,最后一次性插入页面。
|
||||
- **避免触发回流属性**:访问或修改像 `offsetWidth`、`offsetHeight`、`scrollTop` 等属性会强制触发浏览器的回流。将这些操作集中到一个步骤中,避免在同一循环中反复读取和修改布局属性。
|
||||
- **CSS 优化**:将影响性能的动画限制在 `transform` 和 `opacity` 上,这样可以避免触发回流。
|
||||
|
||||
### 网络性能优化
|
||||
|
||||
网络优化是页面快速加载的另一个重要环节,优化网络请求的数量和质量能够显著加快页面的初次渲染。
|
||||
|
||||
#### HTTP/2 与 HTTP/3 的使用
|
||||
|
||||
- **HTTP/2**:通过**多路复用**技术,HTTP/2 允许多个请求同时通过一个 TCP 连接传输,减少了连接的建立和关闭时间。同时,HTTP/2 支持**头部压缩**,通过减少冗余的 HTTP 请求头部信息,进一步减少了网络传输的开销。
|
||||
- **HTTP/3**:基于 UDP 协议的 HTTP/3,利用**QUIC**协议减少了 TCP 的握手延迟,并且可以在网络不稳定时更加高效地恢复数据传输,进一步提升了网站的加载速度。
|
||||
|
||||
#### CDN 和缓存优化
|
||||
|
||||
- **CDN(内容分发网络)**:通过使用 CDN,将静态资源分布到多个地理位置的服务器上,确保用户从最近的服务器获取资源,减少传输延迟。CDN 还能有效减轻源服务器的负担,提高整体响应速度。
|
||||
- **缓存策略**:合理利用浏览器缓存能够极大提升页面加载性能。通过配置 `Cache-Control` 和 `ETag` 等 HTTP 头部,可以控制资源的缓存时间和验证机制,避免重复下载未更改的资源。
|
||||
- **`Cache-Control`**:设置资源的缓存有效期,例如使用 `max-age` 指定资源在多少秒内有效。
|
||||
- **`ETag`**:利用 ETag 头部标识资源的版本,当资源没有变化时,服务器可以返回 304 状态码,告知浏览器使用本地缓存,减少网络带宽的消耗。
|
||||
|
||||
```html
|
||||
Cache-Control: max-age=31536000, public
|
||||
ETag: "abc123"
|
||||
```
|
||||
|
||||
#### Lazy Load 技术
|
||||
|
||||
**懒加载(Lazy Loading)**是优化初次加载时的资源利用效率的重要技术,尤其适用于图片和视频等较大资源。懒加载技术会延迟加载那些在页面初始化时不需要立即显示的资源,直到用户滚动到这些资源的位置时才加载它们。
|
||||
|
||||
- **图片懒加载**:在现代浏览器中,可以通过为 `<img>` 标签添加 `loading="lazy"` 属性,轻松实现图片的懒加载。
|
||||
|
||||
```html
|
||||
<img src="large-image.jpg" loading="lazy" alt="Lazy loaded image">
|
||||
```
|
||||
|
||||
- **视频懒加载**:类似的,视频也可以使用懒加载技术,只有当用户即将观看时才加载视频内容。
|
||||
|
||||
通过这些技术,页面的初始加载时间和数据传输量都能够显著减少,从而提升页面的响应速度。
|
||||
|
||||
## Chrome 浏览器的安全机制
|
||||
|
||||
Chrome 浏览器的安全机制旨在保护用户的数据和隐私,防止恶意网站或代码对用户系统造成危害。它通过多种技术手段确保网页和扩展的安全性,包括同源策略、沙盒机制和内容安全策略(CSP)。
|
||||
|
||||
### 同源策略(SOP, Same-Origin Policy)
|
||||
|
||||
#### 同源策略的定义
|
||||
|
||||
**同源策略**(Same-Origin Policy, SOP)是 Web 安全模型的核心之一,它限制了不同来源(origin)之间的文档和脚本如何进行交互。浏览器将每个网页的资源视为具有特定的来源,只有在同源的情况下,页面之间的脚本才能进行互相访问。这种机制极大地减少了潜在的安全威胁,例如跨站脚本(XSS)和跨站请求伪造(CSRF)。
|
||||
|
||||
- **来源的定义**:同源意味着两个 URL 具有相同的**协议**、**域名**和**端口**。例如,`https://example.com:443` 与 `https://example.com` 视为同源,但 `https://example.com` 与 `http://example.com`、`https://sub.example.com` 则被视为不同源。
|
||||
|
||||
通过同源策略,Chrome 可以有效防止恶意网站通过脚本读取、修改或操纵其他站点的敏感信息,从而提升用户数据的安全性。
|
||||
|
||||
#### 跨源资源共享(CORS, Cross-Origin Resource Sharing)
|
||||
|
||||
尽管同源策略能够提高安全性,但它也对合法的跨域资源访问造成了限制。为了解决这一问题,**跨源资源共享**(CORS)机制应运而生。CORS 允许服务器通过 HTTP 头部信息明确声明哪些外部来源可以访问其资源,进而控制跨域请求的安全性。
|
||||
|
||||
CORS 的工作机制包括:
|
||||
|
||||
- **预检请求**:当浏览器发送跨域请求时,首先会通过 `OPTIONS` 方法发出**预检请求**,询问服务器是否允许该跨域访问。服务器通过响应头中的 `Access-Control-Allow-Origin`、`Access-Control-Allow-Methods` 等字段来决定是否允许请求。
|
||||
- **跨域响应头**:服务器可以通过设置 `Access-Control-Allow-Origin` 头部,指定允许访问资源的来源。设置为 `*` 表示允许任何源访问该资源。
|
||||
|
||||
```http
|
||||
Access-Control-Allow-Origin: https://example.com
|
||||
```
|
||||
|
||||
通过 CORS,Chrome 浏览器能够灵活处理跨域资源请求,确保在安全框架下允许合法的跨域数据交互。
|
||||
|
||||
### 沙盒机制与浏览器安全
|
||||
|
||||
#### 沙盒隔离
|
||||
|
||||
Chrome 的**沙盒机制**是其安全架构的核心之一。**沙盒**将每个标签页、插件或扩展的渲染进程与操作系统隔离开来,限制其对系统资源的访问。这意味着,即使某个网页包含恶意代码,该代码也无法直接访问或修改用户的文件、网络连接或其他敏感资源。
|
||||
|
||||
- 沙盒隔离的优点:
|
||||
- **限制访问权限**:沙盒通过减少进程的权限,确保恶意网站或代码只能在受控的环境中运行,无法对系统核心组件造成威胁。
|
||||
- **安全分区**:每个标签页的渲染进程都在沙盒中独立运行,如果一个标签页崩溃或受到攻击,其他标签页不会受到影响,保障了浏览器的稳定性和安全性。
|
||||
|
||||
这种基于沙盒的隔离策略,不仅防止了浏览器内恶意脚本的横向移动,还阻止了潜在攻击对操作系统和用户数据的直接访问。
|
||||
|
||||
#### 内容安全策略(CSP, Content Security Policy)
|
||||
|
||||
**内容安全策略**(Content Security Policy, CSP)是 Chrome 中用于防止常见 Web 攻击(如 XSS)的关键机制。CSP 通过定义允许网页加载的资源类型和来源,帮助开发者控制网页内容的来源,防止恶意脚本或未经授权的资源注入页面。
|
||||
|
||||
- CSP 的作用:
|
||||
- **防止 XSS 攻击**:通过 CSP,开发者可以禁止网页加载未经授权的脚本,从而阻止恶意脚本通过漏洞注入到网页中执行。
|
||||
- **限制资源加载**:CSP 允许开发者指定页面能够加载的资源来源(如脚本、样式、图像等),从而限制外部资源对页面的影响。例如,开发者可以使用 CSP 规定只有从可信的域名加载 JavaScript 文件。
|
||||
|
||||
CSP 示例:
|
||||
|
||||
```http
|
||||
Content-Security-Policy: script-src 'self' https://trusted.cdn.com; object-src 'none';
|
||||
```
|
||||
|
||||
该策略仅允许从当前来源(`self`)和受信任的 CDN(`https://trusted.cdn.com`)加载脚本,并禁止页面加载任何插件或嵌入式对象(`object-src 'none'`)。通过这种方式,CSP 可以极大地减少攻击面,防止常见的跨站脚本攻击。
|
||||
|
||||
## Chrome 扩展开发
|
||||
|
||||
### Chrome 扩展的核心概念
|
||||
|
||||
Chrome 扩展是用于增强浏览器功能的模块,允许用户根据需求自定义浏览体验。开发 Chrome 扩展需要遵循特定的结构和 API 规范。以下是 Chrome 扩展的核心概念和主要组成部分:
|
||||
|
||||
#### `manifest.json` 文件
|
||||
|
||||
**`manifest.json`**是每个 Chrome 扩展的核心配置文件,负责定义扩展的基本信息、权限、功能以及相关资源。该文件的内容决定了扩展的行为方式以及可以访问的浏览器功能。主要字段包括:
|
||||
|
||||
- **`name`**:扩展的名称。
|
||||
- **`version`**:扩展的版本号。
|
||||
- **`manifest_version`**:Chrome 扩展的规范版本(目前为 3)。
|
||||
- **`permissions`**:扩展所需的权限,如访问特定网站、读取浏览历史、操作标签页等。
|
||||
- **`background`**:定义扩展的**背景脚本**,可以长期运行并处理后台任务。
|
||||
- **`content_scripts`**:定义**内容脚本**,它们能够注入到网页中,操纵 DOM 结构。
|
||||
- **`icons`**:扩展所使用的图标。
|
||||
|
||||
示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "My Chrome Extension",
|
||||
"version": "1.0",
|
||||
"manifest_version": 3,
|
||||
"permissions": ["tabs", "storage"],
|
||||
"background": {
|
||||
"service_worker": "background.js"
|
||||
},
|
||||
"content_scripts": [
|
||||
{
|
||||
"matches": ["https://*.example.com/*"],
|
||||
"js": ["content.js"]
|
||||
}
|
||||
],
|
||||
"icons": {
|
||||
"16": "icon16.png",
|
||||
"48": "icon48.png",
|
||||
"128": "icon128.png"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 背景脚本(Background Scripts)
|
||||
|
||||
**背景脚本**负责管理扩展的长时间运行任务,通常用于事件监听、消息传递和执行特定的操作。背景脚本在后台运行,不会直接与网页交互,它们可以通过**chrome API**与浏览器进行通信。例如,它可以监听标签页的创建、关闭或消息传递。
|
||||
|
||||
在 Manifest Version 3 中,背景脚本被**Service Workers**取代,进一步增强了扩展的性能和安全性,确保扩展在不活动时不占用系统资源。
|
||||
|
||||
示例:
|
||||
|
||||
```javascript
|
||||
chrome.runtime.onInstalled.addListener(() => {
|
||||
console.log("Extension installed");
|
||||
});
|
||||
|
||||
chrome.tabs.onUpdated.addListener((tabId, changeInfo, tab) => {
|
||||
if (changeInfo.status === "complete") {
|
||||
console.log("Tab updated:", tab.url);
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
#### 内容脚本(Content Scripts)
|
||||
|
||||
**内容脚本**运行在特定网页的上下文中,允许开发者直接操作网页的 DOM 结构。它们可以修改页面的内容、插入样式或脚本,但不能直接访问 Chrome 扩展的 API。为了与背景脚本或扩展其他部分通信,内容脚本可以使用**消息传递机制**。
|
||||
|
||||
内容脚本与页面的 JavaScript 环境是分离的,虽然它们能够操作 DOM,但无法直接访问页面的全局变量或函数。
|
||||
|
||||
示例:
|
||||
|
||||
```javascript
|
||||
document.body.style.backgroundColor = "yellow";
|
||||
```
|
||||
|
||||
### 扩展的安全模型
|
||||
|
||||
为了防止恶意扩展滥用浏览器功能,Chrome 扩展的安全模型设计了严格的权限和跨域请求限制。开发者必须声明扩展所需的所有权限,并且 Chrome 会在扩展安装或运行时提示用户。
|
||||
|
||||
#### 权限模型
|
||||
|
||||
每个 Chrome 扩展必须在 `manifest.json` 中明确声明其所需的权限,如访问特定网站的权限、读取或修改浏览历史的权限、操作 Cookie 或标签页的权限等。Chrome 通过这种机制限制扩展的访问范围,以减少潜在的安全威胁。
|
||||
|
||||
常见权限示例:
|
||||
|
||||
- `"tabs"`:允许扩展访问和操作浏览器的标签页。
|
||||
- `"cookies"`:访问和修改网站的 Cookie。
|
||||
- `"storage"`:使用 Chrome 的本地存储功能。
|
||||
- `"activeTab"`:允许扩展与当前活动的标签页交互。
|
||||
|
||||
#### 跨域请求
|
||||
|
||||
Chrome 扩展可以通过 `chrome.extension` API**执行跨域请求,而无需遵守浏览器通常的**同源策略**(Same-Origin Policy)。然而,为了保证安全,开发者必须在 `manifest.json` 中声明明确的权限,允许扩展访问特定域名。这种设计确保扩展不会随意访问或篡改用户的数据。
|
||||
|
||||
```json
|
||||
{
|
||||
"permissions": [
|
||||
"https://api.example.com/"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
通过这种方式,用户可以清楚地了解扩展的访问权限,防止扩展未经许可访问敏感数据。
|
||||
|
||||
### 开发与调试
|
||||
|
||||
Chrome 扩展的开发过程中,Chrome 浏览器提供了丰富的调试工具,帮助开发者在不同的环境下进行测试和调试。
|
||||
|
||||
#### Chrome DevTools
|
||||
|
||||
Chrome DevTools 不仅可以用于调试网页,还支持对 Chrome 扩展进行调试。开发者可以通过以下功能调试扩展:
|
||||
|
||||
- **调试内容脚本**:通过“Sources”选项卡,调试注入到网页中的内容脚本,设置断点、查看 DOM 结构或检查网络请求。
|
||||
- **调试背景脚本**:在“Background page”中,开发者可以查看并调试背景脚本的运行状态,监控事件、网络请求和消息传递行为。
|
||||
- **消息传递调试**:通过检查“Console”选项卡中的日志信息,分析内容脚本与背景脚本之间的通信是否正常。
|
||||
|
||||
#### 发布到 Chrome Web Store
|
||||
|
||||
扩展开发完成后,开发者可以将其打包并发布到**Chrome Web Store**。发布步骤如下:
|
||||
|
||||
1. **打包扩展**:在 Chrome 的扩展管理页面中,将开发完成的扩展打包为 `.zip` 文件。
|
||||
2. **注册开发者账号**:开发者需拥有 Google 账号并注册成为 Chrome Web Store 的开发者。
|
||||
3. **上传扩展**:通过 Chrome Web Store 管理后台上传打包的扩展文件。
|
||||
4. **填写扩展信息**:包括扩展名称、描述、版本信息、权限说明、截图等。
|
||||
5. **审核和发布**:Chrome Web Store 会对扩展进行安全审核,确保其符合安全规范和隐私政策。审核通过后,用户可以从 Chrome Web Store 下载安装扩展。
|
||||
|
||||
## Chrome 的前沿技术
|
||||
|
||||
Chrome 浏览器始终处于推动 Web 技术发展的前沿,不断引入新的技术来增强 Web 应用的功能和性能。以下是两项重要的前沿技术:**渐进式 Web 应用(PWA)\**和\**WebAssembly(WASM)**。
|
||||
|
||||
### 渐进式 Web 应用(PWA, Progressive Web App)
|
||||
|
||||
渐进式 Web 应用(PWA)是一种结合了 Web 和原生应用优势的新型 Web 应用模型。PWA 可以在网络不稳定的情况下正常运行,并且能够像原生应用一样被安装到用户设备上,提供离线功能、推送通知和快捷启动等特性。
|
||||
|
||||
#### PWA 的核心技术
|
||||
|
||||
- **Service Workers**:**Service Workers**是 PWA 的核心技术,运行在浏览器的后台,独立于网页本身。它能够拦截网络请求,缓存静态资源,从而实现离线访问。通过 Service Workers,PWA 可以在没有网络连接时继续工作,提供类似原生应用的用户体验。
|
||||
|
||||
另一个关键功能是**推送通知**。即使应用未被打开,Service Workers 也可以通过服务器推送消息,提供消息通知功能。此外,Service Workers 还可以控制更新策略,确保应用始终保持最新版本。
|
||||
|
||||
```javascript
|
||||
// 注册 Service Worker
|
||||
if ('serviceWorker' in navigator) {
|
||||
navigator.serviceWorker.register('/sw.js').then(registration => {
|
||||
console.log('Service Worker registered with scope:', registration.scope);
|
||||
}).catch(error => {
|
||||
console.log('Service Worker registration failed:', error);
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
- **Manifest 文件**:**Web App Manifest**是一个 JSON 文件,定义了 PWA 的启动行为、图标、显示模式(如全屏、固定窗口等),使 Web 应用在外观和使用上更接近原生应用。通过 Manifest 文件,用户可以将 PWA 应用安装到主屏幕,并通过自定义图标和启动界面提供一致的用户体验。
|
||||
|
||||
示例 `manifest.json` 文件:
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "My PWA",
|
||||
"short_name": "PWA",
|
||||
"start_url": "/index.html",
|
||||
"icons": [
|
||||
{
|
||||
"src": "/images/icon-192.png",
|
||||
"sizes": "192x192",
|
||||
"type": "image/png"
|
||||
},
|
||||
{
|
||||
"src": "/images/icon-512.png",
|
||||
"sizes": "512x512",
|
||||
"type": "image/png"
|
||||
}
|
||||
],
|
||||
"background_color": "#ffffff",
|
||||
"display": "standalone"
|
||||
}
|
||||
```
|
||||
|
||||
#### PWA 在 Chrome 中的支持与调试
|
||||
|
||||
Chrome 对 PWA 提供了全面的支持,并且可以通过**Chrome DevTools**对 PWA 的功能进行调试:
|
||||
|
||||
- **离线缓存调试**:在 Chrome DevTools 的 "Application" 面板中,开发者可以查看和管理 Service Workers 的缓存状态,查看哪些资源被缓存,以及何时清理缓存。
|
||||
- **推送通知调试**:DevTools 允许调试 PWA 的推送通知行为,查看消息是否成功推送,并在控制台模拟推送事件。
|
||||
- **Manifest 文件调试**:通过 DevTools 的 "Application" 面板,开发者可以检查 PWA 的 Manifest 文件配置,确保应用图标、启动 URL 等内容符合预期。
|
||||
|
||||
### WebAssembly(WASM)
|
||||
|
||||
**WebAssembly**(WASM)是一种基于字节码的编程语言,它允许开发者在浏览器中运行接近原生性能的代码。WASM 的出现使得高性能计算和复杂的应用场景(如游戏、图像处理、数据分析等)可以在浏览器中高效运行。
|
||||
|
||||
#### WebAssembly 简介
|
||||
|
||||
WebAssembly 是一种**平台无关的二进制格式**,通过编译其他高级语言(如 C、C++、Rust)生成字节码,在浏览器中执行这些代码时能够接近原生应用的性能。WASM 的设计目标是让 Web 应用能够高效地处理复杂计算任务,如 3D 图形、音频处理和加密等,这些通常是 JavaScript 难以胜任的场景。
|
||||
|
||||
WebAssembly 的主要优点包括:
|
||||
|
||||
- **高性能**:相比于 JavaScript,WASM 以二进制形式传输和执行,具有更快的解析速度和更高效的运行性能。
|
||||
- **跨平台**:WASM 是跨浏览器、跨平台的,Chrome、Firefox、Edge、Safari 等主流浏览器都支持运行 WASM 模块。
|
||||
- **语言无关性**:WebAssembly 不依赖于某一种编程语言,开发者可以用多种高级语言编写代码并编译为 WASM。
|
||||
|
||||
#### 与 JavaScript 互操作
|
||||
|
||||
WebAssembly 并非要完全取代 JavaScript,而是与其互补。开发者可以在 JavaScript 中**调用 WASM 模块**,同时利用 JavaScript 的灵活性和 WASM 的高效计算能力,结合两者的优势构建复杂的 Web 应用。
|
||||
|
||||
下面是一个基本的 WASM 和 JavaScript 互操作示例:
|
||||
|
||||
1. 编译 C 代码为 WASM: 假设我们有一个 C 函数 `add`,将其编译为 WASM 模块。
|
||||
|
||||
```c
|
||||
// add.c
|
||||
int add(int a, int b) {
|
||||
return a + b;
|
||||
}
|
||||
```
|
||||
|
||||
使用 `emscripten` 工具链将 C 代码编译为 WebAssembly:
|
||||
|
||||
```shell
|
||||
emcc add.c -s WASM=1 -o add.wasm
|
||||
```
|
||||
|
||||
2. 在 JavaScript 中加载和调用 WASM 模块:
|
||||
|
||||
```javascript
|
||||
const importObject = {
|
||||
env: {
|
||||
// 可以定义一些供WASM使用的全局变量或函数
|
||||
}
|
||||
};
|
||||
|
||||
WebAssembly.instantiateStreaming(fetch('add.wasm'), importObject)
|
||||
.then(obj => {
|
||||
const add = obj.instance.exports.add;
|
||||
console.log("Result of 3 + 4 =", add(3, 4)); // 输出:Result of 3 + 4 = 7
|
||||
});
|
||||
```
|
||||
|
||||
在这个示例中,WASM 模块定义了一个 `add` 函数,并通过 JavaScript 进行调用。WebAssembly 模块可以高效执行数值运算、处理复杂算法,从而显著提升应用的性能。
|
||||
565
Technology/WebDevelopment/1.Browser/3.Firefox.md
Normal file
565
Technology/WebDevelopment/1.Browser/3.Firefox.md
Normal file
@ -0,0 +1,565 @@
|
||||
---
|
||||
title: Firefox
|
||||
description: Mozilla Firefox 是一款开源网络浏览器,由 Mozilla 基金会开发,以隐私保护和开源社区支持而闻名。自2004年发布以来,它提供了高速浏览体验,并通过诸如Gecko渲染引擎、SpiderMonkey JavaScript引擎、以及Quantum项目等技术创新不断优化性能。Firefox 支持跨平台使用,提供扩展兼容性,并注重用户隐私与安全。
|
||||
keywords:
|
||||
- Firefox
|
||||
- Mozilla
|
||||
- 开源浏览器
|
||||
- 隐私保护
|
||||
- 性能优化
|
||||
- 扩展支持
|
||||
tags:
|
||||
- 技术/WebDev
|
||||
- WebDev/Browser
|
||||
author: 仲平
|
||||
date: 2024-09-30
|
||||
---
|
||||
|
||||
## Firefox
|
||||
|
||||
### Firefox 的概述与特点
|
||||
|
||||
#### 诞生背景
|
||||
|
||||
**Firefox 是由 Mozilla 基金会发布的开源浏览器,其历史可以追溯到 2002 年以“Phoenix”项目为起点。** 作为 Netscape 浏览器的继承者,Firefox 的目标是提供一个**开放源代码、隐私保护至上**的浏览器,推动开放互联网的发展。2004 年,Firefox 正式推出 1.0 版本,并迅速成为主流浏览器,打破了当时 Internet Explorer 的垄断地位。
|
||||
|
||||
#### 核心特性
|
||||
|
||||
- **速度**:Firefox 使用的**Gecko 渲染引擎**和**SpiderMonkey JavaScript 引擎**对页面加载和执行速度进行了持续优化。通过引入**Quantum 项目**,Firefox 的性能在 2017 年得到了显著提升,特别是在多核处理器上的并发执行效率方面。Quantum 通过改进 Gecko 引擎的架构,使得浏览器在处理复杂网页时的速度和响应能力大幅提高。
|
||||
- **隐私与安全**:Firefox 以其**强大的隐私保护功能**著称。浏览器内置了**增强型追踪保护**,可以阻止广告追踪器、第三方 Cookie 以及恶意脚本的运行。此外,Firefox 还提供了**隐私浏览模式**,自动清除会话结束后的所有历史记录和数据。Mozilla 还在持续开发工具,如**Firefox Monitor**,帮助用户检测数据泄露,进一步保障用户隐私。
|
||||
- **扩展支持**:Firefox 支持广泛的扩展生态系统,并且与 Chrome 的扩展框架兼容,采用了**WebExtensions API**。这意味着大多数为 Chrome 开发的扩展可以轻松移植到 Firefox,用户可以访问大量扩展程序来定制浏览器功能。
|
||||
- **开源与透明**:作为一个开源项目,Firefox 的源代码对公众开放,任何开发者都可以查看、贡献或修改其代码。Mozilla 通过社区驱动的开发模式,确保了浏览器的透明性和公正性。Firefox 的开放性不仅为开发者提供了自由,也使得用户能够信任该平台不会滥用数据或隐私。
|
||||
- **跨平台支持**:Firefox 支持多种操作系统,包括**Windows**、**macOS**、**Linux**、**Android**和**iOS**。无论在哪个平台上,Firefox 都提供一致的用户体验和功能集成,确保用户在不同设备上能够无缝切换浏览体验。
|
||||
- **同步功能**:Firefox 提供**同步功能**,允许用户通过创建 Firefox 账户,同步书签、浏览历史、扩展、密码和设置等信息。这一功能对于在多个设备上使用 Firefox 的用户而言,极大地提升了便利性和一致性。
|
||||
|
||||
#### 市场份额
|
||||
|
||||
**尽管 Firefox 的市场份额较谷歌 Chrome 有所减少,但它在隐私保护、开发者工具以及开源社区中的影响力依然显著。** 尤其是在注重隐私和安全的用户群体以及开发者社区中,Firefox 继续保持较高的忠诚度。开发者工具(如**Firefox DevTools**)提供了与 Chrome DevTools 类似的功能,吸引了大量开发者使用 Firefox 作为调试和开发环境。
|
||||
|
||||
### Firefox 与 Mozilla 的关系
|
||||
|
||||
#### Mozilla 基金会
|
||||
|
||||
**Mozilla 基金会**是非营利组织,成立于 2003 年,负责 Firefox 浏览器的开发与维护。Mozilla 的使命是促进开放、可访问、隐私保护的互联网发展。与一些商业浏览器不同,Mozilla 的非营利性质确保了其不会依赖广告和数据追踪来获利,从而进一步保障了用户的隐私和数据安全。
|
||||
|
||||
#### Gecko 引擎
|
||||
|
||||
**Gecko**是 Mozilla 独立开发的渲染引擎,与 Chrome 的 Blink 引擎不同。Gecko 是开源的,旨在符合 W3C 的最新 Web 标准,并且经过了持续的优化,以提高性能、兼容性和安全性。它为 Firefox 提供了强大的 Web 渲染能力,并支持复杂的网页布局和动画处理。
|
||||
|
||||
#### Quantum 项目
|
||||
|
||||
**Quantum 项目**是 Mozilla 于 2017 年启动的重大性能提升计划,旨在彻底重构 Firefox 的引擎架构,使其更快、更高效。Quantum 通过并行处理、多线程任务调度和内存管理的优化,使得 Firefox 在多核处理器上可以更好地利用硬件资源。这一项目极大提升了 Firefox 的加载速度、响应性和稳定性,并缩小了与其他主流浏览器的性能差距。
|
||||
|
||||
Quantum 项目的推出标志着 Firefox 进入了一个新的性能时代,使其在与 Chrome 的竞争中具有了更强的技术基础。
|
||||
|
||||
## Firefox 历史发展
|
||||
|
||||
### Firefox 的早期发展(2002-2010)
|
||||
|
||||
#### Phoenix 和 Firebird
|
||||
|
||||
Firefox 的历史可以追溯到 2002 年,当时 Mozilla 社区开发了一个名为**Phoenix**的浏览器,作为 Netscape Navigator 的继承者。Phoenix 以其轻量、快速和灵活的特性,试图与当时市场主导的 Internet Explorer 竞争。由于与另一个软件发生商标冲突,Phoenix 被改名为**Firebird**。但很快,Mozilla 决定将其最终命名为**Firefox**。
|
||||
|
||||
2004 年,Mozilla 发布了**Firefox 1.0**,这是第一个正式版本。它以简洁的界面和卓越的性能迅速吸引了用户。当时,Firefox 作为开源的替代选择,提供了更强的安全性、隐私保护和浏览体验,受到广大用户的欢迎。2004 年底,Firefox 的下载量突破了 100 万次,标志着其作为主流浏览器的崛起。
|
||||
|
||||
#### Mozilla 的开放源代码理念
|
||||
|
||||
Firefox 的诞生与发展深受**Mozilla 开放源代码理念**的影响。作为一个完全开源的浏览器,Firefox 的代码对全球开发者开放,任何人都可以为其做出贡献。这种开发模式使得 Firefox 能够快速响应用户需求,进行持续的改进与创新。
|
||||
|
||||
开源社区的支持不仅推动了 Firefox 技术的进步,还帮助其打造了一个高度活跃的开发者生态系统。这一生态系统为 Firefox 带来了新的功能和修复,也使得它能够快速跟进和实施最新的 Web 标准。
|
||||
|
||||
#### Firefox 扩展生态的建立
|
||||
|
||||
Firefox 在早期就意识到了**扩展支持**的重要性。它为用户提供了高度可定制的浏览体验,允许开发者创建扩展来增强浏览器的功能。通过 Firefox 扩展生态,用户可以安装广告拦截器、开发者工具、密码管理器等各种插件,满足不同的使用需求。
|
||||
|
||||
Firefox 的扩展系统帮助它迅速积累了大批忠实用户和开发者。Firefox 成为了第一款主流浏览器中提供强大扩展支持的产品,这不仅增加了用户粘性,也推动了 Firefox 作为创新平台的形象。
|
||||
|
||||
### Firefox 的技术革新与竞争(2011-2015)
|
||||
|
||||
#### 多进程架构
|
||||
|
||||
Firefox 最初采用单进程架构,即所有标签页、扩展和插件都在一个进程中运行。这导致了性能问题,尤其是当某个标签页崩溃时,会影响整个浏览器的稳定性。与采用多进程架构的 Chrome 相比,Firefox 在性能和稳定性方面处于劣势。
|
||||
|
||||
2011 年,Mozilla 启动了**Electrolysis(e10s)项目,逐步将 Firefox 转向多进程架构**。通过这一架构,每个标签页、插件和扩展都在独立的进程中运行,从而提高浏览器的稳定性、安全性和性能。这一转变帮助 Firefox 缩小了与竞争对手 Chrome 在性能上的差距。
|
||||
|
||||
#### 扩展支持的改进
|
||||
|
||||
为了提升扩展的兼容性,Firefox 逐步过渡到**WebExtensions API**,该 API 与 Google Chrome 的扩展框架兼容。这使得开发者可以更轻松地将 Chrome 扩展移植到 Firefox 上,丰富了 Firefox 的扩展生态。
|
||||
|
||||
这一变化使得 Firefox 能够继续保持其高度可定制的特性,同时确保扩展的安全性和性能。与 Chrome 的兼容性也使得用户可以在两个平台之间无缝切换扩展,提升了用户体验。
|
||||
|
||||
#### Firefox OS 项目
|
||||
|
||||
Mozilla 在此期间也探索了移动平台的可能性,推出了基于 Web 技术的移动操作系统**Firefox OS**。该系统主要面向低成本的智能手机市场,旨在通过开放的 Web 技术推动移动互联网的普及。尽管 Firefox OS 未能在市场上取得预期的成功,并于 2016 年停止开发,但其在推动 Web 技术向移动端发展的过程中贡献显著。
|
||||
|
||||
### Firefox 的现代化演变(2016- 至今)
|
||||
|
||||
#### Quantum 项目的引入
|
||||
|
||||
2017 年,Mozilla 推出了**Quantum 项目**,这是 Firefox 现代化演变的标志性事件。Quantum 项目通过重构 Firefox 的浏览器引擎,带来了性能的质变提升。该项目引入了并行处理和多核优化,确保 Firefox 可以更高效地利用现代硬件资源。
|
||||
|
||||
Quantum 项目显著提升了 Firefox 的速度和内存管理效率,特别是在处理复杂网页和多任务操作时的表现。Quantum 还引入了基于 GPU 的图形渲染,进一步提升了网页的加载速度和流畅度,使得 Firefox 能够与 Chrome 等浏览器竞争。
|
||||
|
||||
#### 引入 Servo 技术
|
||||
|
||||
Firefox 在 Quantum 项目中部分采用了由 Mozilla 开发的**Servo 引擎**技术。Servo 是一个基于 Rust 语言的新型浏览器引擎,具备高并发处理和安全特性。Rust 语言的内存安全特性减少了传统 C/C++ 代码中的漏洞风险,这使得 Firefox 在性能与安全性上更具优势。
|
||||
|
||||
Servo 的引入使得 Firefox 能够更高效地进行并发任务处理,优化了渲染速度和内存使用,并为未来进一步提升性能提供了坚实基础。
|
||||
|
||||
#### 隐私保护的创新
|
||||
|
||||
随着用户隐私日益受到关注,Firefox 通过不断引入新的隐私保护功能,进一步巩固了其在隐私领域的领先地位。2018 年,Firefox 推出了**增强型跟踪保护(Enhanced Tracking Protection)**,旨在阻止广告追踪器和第三方 Cookie,从而保护用户隐私。
|
||||
|
||||
Mozilla 还推出了专注于隐私保护的浏览器**Firefox Focus**,它默认启用广告拦截和隐私保护功能,不保留浏览记录,成为注重隐私用户的首选浏览器之一。
|
||||
|
||||
#### 逐步淘汰旧技术
|
||||
|
||||
随着 Web 技术的发展,Firefox 逐步淘汰了一些过时的技术,如**Adobe Flash**。Mozilla 通过推动现代 Web 标准(如**HTML5**、**WebAssembly**、**WebRTC**)的采用,促进了 Web 平台的进步。WebAssembly 的引入,使得开发者能够在浏览器中运行接近原生性能的代码,为高性能 Web 应用提供了强大的支持。
|
||||
|
||||
## Firefox 的架构
|
||||
|
||||
### 多进程架构的概述
|
||||
|
||||
**多进程架构是现代浏览器中重要的设计模式**,通过将不同功能模块分离到独立的进程中,提高浏览器的稳定性、安全性和性能。**Electrolysis(e10s)项目**是 Mozilla 为 Firefox 引入多进程架构的关键项目,旨在解决传统单进程浏览器存在的崩溃、性能和安全性问题。通过 e10s,Firefox 在架构上经历了重大革新,将用户界面、内容渲染和后台任务处理分布在多个独立的进程中,从而显著提升了用户体验。
|
||||
|
||||
#### Electrolysis(e10s)项目
|
||||
|
||||
**Electrolysis**项目的推出,是 Firefox 从单进程架构转向多进程架构的里程碑。单进程浏览器模式将所有页面、插件和 UI 渲染放在同一进程中,导致一个标签页或插件的崩溃会引发整个浏览器的崩溃。Electrolysis 通过将浏览器的 UI 和页面内容分离到不同的进程中,解决了这一问题。
|
||||
|
||||
核心目标:
|
||||
|
||||
- **稳定性**:通过进程隔离,确保单个页面的崩溃不会影响其他标签页或浏览器主进程。
|
||||
- **性能**:分离进程后,Firefox 能够更高效地分配资源,避免单个任务占用过多系统资源。
|
||||
- **安全性**:独立的内容进程运行在受限的权限范围内,减少了恶意脚本对系统造成威胁的可能性。
|
||||
|
||||
#### 进程模型设计
|
||||
|
||||
Firefox 的多进程架构将不同的功能模块分配到独立的进程中,优化了浏览器的资源管理和任务调度。
|
||||
|
||||
- **主进程**:**浏览器主进程**(Browser Process)负责管理 Firefox 的 UI,包括标签页、窗口、工具栏和菜单。同时,它也负责处理网络请求、文件下载和各个进程之间的协调工作。主进程起到了控制中心的作用,确保浏览器的核心功能顺畅运行。
|
||||
- **内容进程**:每个标签页在一个独立的**内容进程**中渲染和执行页面内容,避免了页面之间的相互干扰。每个内容进程负责解析 HTML、CSS 和 JavaScript,执行页面脚本并进行 DOM 操作。通过这种设计,内容进程的崩溃不会影响浏览器的主进程或其他标签页的运行,极大提升了浏览器的稳定性。
|
||||
- **GPU 进程**:**GPU 进程**(Graphics Processing Unit Process)是专门用于处理与图形相关的任务,如页面渲染、动画和视频播放等。通过将这些资源密集型任务交给 GPU 处理,Firefox 能够更高效地渲染复杂的网页内容,同时减少对 CPU 的依赖,提升整体性能。
|
||||
|
||||
此外,Firefox 的架构还包括一些辅助进程,例如:
|
||||
|
||||
- **插件进程**:负责运行传统的浏览器插件(如 Flash),这些插件与页面内容隔离,避免其崩溃影响浏览器稳定性。
|
||||
- **扩展进程**:负责执行 Firefox 扩展程序,使其与页面内容独立运行,增强浏览器的安全性和稳定性。
|
||||
|
||||
### 多进程架构的优缺点
|
||||
|
||||
**优点**
|
||||
|
||||
- **稳定性提升**:多进程架构显著提升了 Firefox 的稳定性。每个标签页的内容进程独立运行,这意味着即使一个页面崩溃,其他标签页和浏览器本身仍能正常工作。主进程仅负责用户界面的管理和进程之间的通信,从而减少了浏览器整体崩溃的可能性。
|
||||
- **安全性增强**:多进程架构为安全性提供了更高的保障。内容进程运行在一个受限的环境(沙盒)中,不能直接访问用户的系统资源。这种隔离有效防止了恶意网站或脚本通过浏览器对用户的系统进行攻击。此外,进程间的隔离机制进一步减少了跨站脚本攻击(XSS)和跨站请求伪造(CSRF)等网络攻击的风险。
|
||||
- **并行处理**:通过将渲染和脚本执行任务分配到多个进程中,Firefox 能够更好地利用现代多核 CPU 的优势。各个进程可以并行执行,提升了整体的浏览性能和响应速度,特别是在多任务处理和高负载情况下。
|
||||
- **资源分配优化**:多进程模型使 Firefox 能够更细粒度地控制资源分配。每个进程独立管理内存和 CPU 资源,防止单个任务占用过多资源。这对于复杂的 Web 应用和动态页面特别重要,避免了单个页面造成浏览器性能下降的情况。
|
||||
|
||||
**缺点**
|
||||
|
||||
- **内存占用较高**:多进程架构的一个主要缺点是内存占用较高。每个独立进程都会占用一定的系统资源,尤其是在同时打开多个标签页时,每个内容进程独立运行,导致内存需求增大。对于低内存设备或需要长时间打开大量标签页的用户,这可能会影响系统的性能。
|
||||
- **启动速度影响**:多进程架构可能在某些情况下影响浏览器的启动速度,特别是在需要为每个进程分配资源并初始化时,可能会增加启动延迟。不过,随着硬件性能的提升和 Firefox 的持续优化,这一问题已逐渐得到缓解。
|
||||
|
||||
## Firefox 的渲染机制
|
||||
|
||||
### 从输入 URL 到页面渲染的详细过程
|
||||
|
||||
当用户在浏览器中输入 URL 并按下回车键时,浏览器开始从请求页面到呈现页面内容的整个渲染过程。Firefox 使用其独特的**Gecko 渲染引擎**来解析和渲染页面,具体过程如下:
|
||||
|
||||
#### 请求阶段
|
||||
|
||||
- DNS 解析与 HTTP 请求:
|
||||
- 首先,Firefox 会通过**DNS 解析**将用户输入的域名(如 `example.com`)转换为对应的 IP 地址。获取 IP 地址后,浏览器通过**TCP 连接**与服务器建立通信。如果是 HTTPS 请求,还会进行**TLS 握手**来确保通信的加密安全。
|
||||
- 随后,浏览器向服务器发起**HTTP/HTTPS 请求**,请求获取页面的资源。这些资源包括 HTML 文档、CSS 文件、JavaScript 脚本、图片等。
|
||||
|
||||
#### 渲染流程
|
||||
|
||||
在获取页面资源后,Firefox 开始进入渲染阶段,将资源转化为用户可见的页面内容。
|
||||
|
||||
- **HTML 解析与 DOM 树生成**:浏览器首先解析 HTML 文档并构建**DOM 树**(Document Object Model)。DOM 树是页面内容的内部表示结构,每个 HTML 标签对应 DOM 树中的一个节点。这一步骤为页面的逻辑和结构提供基础。
|
||||
- **CSS 解析与 CSSOM 生成**:同时,浏览器解析外部的 CSS 样式文件以及内联样式,生成**CSSOM 树**(CSS Object Model)。CSSOM 树描述了页面中每个 DOM 元素的样式属性。DOM 树和 CSSOM 树结合,决定页面元素如何呈现。
|
||||
- **布局与绘制**:通过结合 DOM 树和 CSSOM 树,浏览器生成**渲染树**,表示页面中需要显示的可见元素。接着进入**布局(Layout)**阶段,浏览器计算每个元素的大小、位置,确定它们在页面中的精确布局。完成布局后,浏览器进入**绘制(Painting)**阶段,将渲染树的内容绘制到屏幕上。这包括绘制元素的文本、颜色、边框、背景图片等视觉效果。
|
||||
- **合成与图层管理**:为了提升复杂页面的渲染效率,Firefox 将页面内容分割成多个图层,通过**GPU 进程**进行图层合成和渲染。页面中的动画、视频、图形处理都会通过**GPU 加速**,以提高渲染速度和流畅度。最后,浏览器将这些图层组合在一起,呈现在用户屏幕上。
|
||||
|
||||
### Gecko 渲染引擎
|
||||
|
||||
#### Gecko 概述
|
||||
|
||||
**Gecko**是 Mozilla 专为 Firefox 开发的渲染引擎,用于解析和渲染 HTML、CSS、JavaScript 以及其他 Web 内容。作为一个完全支持现代 Web 标准的引擎,Gecko 支持最新的 HTML5、CSS3、JavaScript(ES6+)等技术,并且经过了多年的迭代优化。
|
||||
|
||||
Gecko 负责处理 Web 内容的呈现,从 HTML 解析、DOM 树构建到最终的页面绘制。它与 Firefox 的 JavaScript 引擎**SpiderMonkey**协同工作,确保动态内容能够快速渲染。
|
||||
|
||||
#### Servo 项目的引入
|
||||
|
||||
**Servo**是由 Mozilla 开发的基于 Rust 语言的浏览器引擎,旨在利用现代多核处理器的优势来并行处理页面渲染任务。Servo 具备较高的并发处理能力和内存安全性,能够避免许多传统引擎中的内存管理问题。
|
||||
|
||||
在**Quantum 项目**中,Firefox 逐步将**Servo**的技术引入到**Gecko**中。通过这种混合架构,Firefox 的渲染速度大幅提升,特别是在多核处理器上,Servo 的并发处理特性让 Firefox 在渲染复杂页面时更加高效和流畅。
|
||||
|
||||
Quantum 项目引入了 Servo 的部分技术,比如图层管理和并行化 CSS 处理,极大地改善了渲染性能和内存管理,使得 Firefox 在与 Chrome 等竞争对手的比较中不再处于劣势。
|
||||
|
||||
### SpiderMonkey JavaScript 引擎
|
||||
|
||||
#### SpiderMonkey 概述
|
||||
|
||||
**SpiderMonkey**是 Firefox 的 JavaScript 引擎,专门用于解析、编译和执行 JavaScript 代码。它支持现代 JavaScript 的所有功能,包括 ES6 及以后的标准。SpiderMonkey 在性能优化方面做了大量工作,以确保能够高效处理复杂的 Web 应用。
|
||||
|
||||
- **即时编译(JIT,Just-in-Time)**:SpiderMonkey 使用了即时编译技术,将 JavaScript 代码在运行时编译为机器码,这样可以显著提升执行速度,尤其是在处理复杂的动态脚本时。
|
||||
- SpiderMonkey 通过优化代码执行和内存管理,确保页面脚本的快速执行。
|
||||
|
||||
#### 性能优化
|
||||
|
||||
SpiderMonkey 在性能优化上进行了许多改进,尤其是**垃圾回收**(Garbage Collection)机制。
|
||||
|
||||
- **增量垃圾回收**:传统的垃圾回收策略会在回收时暂停应用的执行,导致用户在运行时感受到明显的卡顿。为了解决这一问题,SpiderMonkey 引入了**增量垃圾回收**机制,通过分阶段、逐步清理内存中的无效对象,减少垃圾回收过程对页面性能的影响。
|
||||
- **内存管理优化**:SpiderMonkey 通过精细的内存管理策略,优化了对对象的创建和销毁,提高了浏览器的整体性能和响应能力。尤其是在处理大规模 JavaScript 对象时,这种优化能够显著减少内存泄漏的风险,并保持页面的流畅运行。
|
||||
|
||||
## Firefox 的性能优化
|
||||
|
||||
优化页面和网络性能是提升 Firefox 浏览器中 Web 应用响应速度和用户体验的关键步骤。通过合理的资源管理、延迟加载技术以及网络请求优化,开发者可以大幅减少加载时间、提升页面交互流畅度。此外,使用**Firefox DevTools**进行性能分析,可以帮助开发者识别和解决性能瓶颈。
|
||||
|
||||
### 页面性能优化
|
||||
|
||||
#### Lazy Loading 与资源延迟加载
|
||||
|
||||
**Lazy Loading**(懒加载)是一种优化页面加载性能的技术,主要针对图片、视频等非关键资源。懒加载技术使得资源只在用户滚动到页面相应部分时才加载,而不是在页面初次加载时就全部下载。这种方式有效减少了页面的初次渲染时间,加速了页面的可用性。
|
||||
|
||||
- **应用场景**:图片、视频、iframe 等资源。
|
||||
- **实现方式**:在 HTML 中使用 `loading="lazy"` 属性,或通过 JavaScript 动态加载资源。
|
||||
|
||||
```html
|
||||
<img src="image.jpg" loading="lazy" alt="Lazy loaded image">
|
||||
```
|
||||
|
||||
通过这种延迟加载,用户在没有浏览到相应内容时不会浪费带宽下载资源,从而提高了页面的响应速度。
|
||||
|
||||
#### 减少回流与重绘
|
||||
|
||||
- **回流(Reflow)**:回流发生在页面的布局发生变化时,浏览器需要重新计算元素的大小、位置并重新绘制页面。这是一个性能开销较大的过程,因此需要尽量减少不必要的回流。
|
||||
|
||||
**优化策略**:
|
||||
|
||||
- 避免逐步操作 DOM,尽量批量更新。可以使用 `DocumentFragment` 或批量操作 CSS 属性来减少 DOM 操作的次数。
|
||||
- 避免频繁读取导致回流的属性(如 `offsetHeight`、`scrollTop` 等),应将它们的读取和写入操作分开。
|
||||
|
||||
- **重绘(Repaint)**:重绘发生在元素的视觉样式发生变化(如颜色、背景等),但不影响布局时。虽然重绘的开销小于回流,但频繁的重绘仍然会影响性能。
|
||||
|
||||
**优化策略**:
|
||||
|
||||
- 将影响页面显示的操作尽量集中在一次操作中完成,避免频繁更新样式。
|
||||
- 使用 `transform` 和 `opacity` 属性进行动画和视觉效果处理,因为这些属性不会触发回流或重绘。
|
||||
|
||||
### 网络性能优化
|
||||
|
||||
#### HTTP/2 与 HTTP/3 支持
|
||||
|
||||
**HTTP/2**和**HTTP/3**是现代的网络协议,它们通过多路复用、头部压缩等技术显著提高了网络性能。Firefox 支持这两种协议,开发者可以利用它们减少请求延迟、提高资源传输效率。
|
||||
|
||||
- **多路复用**:HTTP/2 允许在单一的 TCP 连接上同时传输多个请求和响应,减少了建立多次连接的开销。
|
||||
- **头部压缩**:HTTP/2 通过对 HTTP 头部进行压缩,减少了数据传输量,提高了响应速度。
|
||||
- **HTTP/3**:基于 UDP 的 HTTP/3 协议,通过**QUIC**协议进一步减少了连接建立的延迟,并提高了在网络条件不佳时的传输稳定性。
|
||||
|
||||
#### 缓存优化
|
||||
|
||||
有效利用浏览器的缓存机制可以显著减少不必要的网络请求,提升页面加载速度。通过合理配置 `Cache-Control` 和 `ETag` 头部信息,开发者可以确保资源在合适的时间内被缓存,并避免重复加载。
|
||||
|
||||
- **`Cache-Control`**:指定资源的缓存策略,如 `max-age` 来定义缓存的有效期。
|
||||
|
||||
```http
|
||||
Cache-Control: max-age=3600, public
|
||||
```
|
||||
|
||||
- **`ETag`**:用于标识资源的版本,当资源未发生变化时,服务器可以返回 304 状态码,指示浏览器使用本地缓存。
|
||||
|
||||
```http
|
||||
ETag: "abc123"
|
||||
```
|
||||
|
||||
通过这些缓存优化,浏览器能够减少向服务器请求的次数,加快页面加载速度,尤其是在用户频繁访问相同资源时。
|
||||
|
||||
#### CDN 与预加载
|
||||
|
||||
- **CDN(内容分发网络)**:使用 CDN 将静态资源分发到多个地理位置的服务器上,确保用户能够从离自己最近的服务器获取资源,减少了传输延迟。
|
||||
|
||||
**优化策略**:
|
||||
|
||||
- 将静态资源(如图片、CSS、JavaScript 文件)托管到 CDN。
|
||||
- 确保 CDN 能够根据用户的地理位置选择最优的资源节点进行分发。
|
||||
|
||||
- **预加载技术**:通过预加载关键资源,可以确保浏览器在用户需要时已经提前下载了这些资源,从而减少等待时间。
|
||||
|
||||
```http
|
||||
<link rel="preload" href="/style.css" as="style">
|
||||
```
|
||||
|
||||
预加载可以显著加快关键资源(如 CSS 文件、字体、重要的 JavaScript 库)的加载速度,优化用户的首次访问体验。
|
||||
|
||||
## Firefox 的安全机制
|
||||
|
||||
Firefox 通过多层次的安全机制来保障用户的隐私和系统安全,防止恶意网站或代码对用户造成危害。这些安全机制包括**同源策略(SOP)**、**沙盒隔离机制**和**内容安全策略(CSP)**,共同为用户提供全面的浏览器安全保障。
|
||||
|
||||
### 同源策略(SOP, Same-Origin Policy)
|
||||
|
||||
#### 同源策略
|
||||
|
||||
**同源策略**(Same-Origin Policy, SOP)是 Web 浏览器最基本的安全机制之一。它限制了来自不同来源的网页内容之间的交互,以防止恶意网站访问或篡改用户的敏感数据。同源策略通过控制文档、脚本和资源的交互权限,确保用户数据的隐私和安全。
|
||||
|
||||
- **同源的定义**:同源指的是两个 URL 具有相同的**协议**(如 HTTP/HTTPS)、**域名**和**端口**。如果这些信息中有任何一个不同,则被认为是不同源。
|
||||
|
||||
例如,`https://example.com:443` 与 `http://example.com`、`https://sub.example.com` 都被视为不同源,这意味着它们之间不能直接共享数据。
|
||||
|
||||
- **安全性作用**:同源策略通过限制不同来源的网站之间的脚本交互,防止恶意网站读取用户会话、访问其他页面的 Cookie 或通过脚本窃取数据。它是防御跨站脚本(XSS)和跨站请求伪造(CSRF)等攻击的重要安全措施。
|
||||
|
||||
#### 1.2 CORS(跨源资源共享)
|
||||
|
||||
尽管同源策略限制了不同来源的交互,但某些情况下,合法的跨域请求仍然是必要的。**CORS(跨源资源共享)**机制允许服务器明确控制哪些外部来源可以访问其资源。
|
||||
|
||||
- **CORS 的工作机制**:当浏览器发出跨域请求时,服务器可以在响应头中设置 `Access-Control-Allow-Origin`,指定哪些来源可以访问资源。如果跨域请求被允许,浏览器才会继续处理请求。
|
||||
|
||||
```http
|
||||
Access-Control-Allow-Origin: https://example.com
|
||||
```
|
||||
|
||||
对于复杂请求,浏览器会先发起**预检请求**(OPTIONS 方法),询问服务器是否允许跨域请求。服务器通过返回适当的 CORS 响应头部来决定是否允许跨源访问。
|
||||
|
||||
通过 CORS,服务器能够精细控制跨域请求的权限,确保合法请求被接受,而非法请求则被拒绝,从而进一步增强了跨域资源共享的安全性。
|
||||
|
||||
### 沙盒隔离机制
|
||||
|
||||
#### 内容进程的沙盒化
|
||||
|
||||
**沙盒化**是一种有效的安全技术,通过将运行的程序与系统核心资源隔离开来,限制其对操作系统的访问权限。Firefox 使用**多进程架构**,每个网页的内容渲染都在**内容进程**中进行,而内容进程被放置在一个受限的沙盒环境中运行。
|
||||
|
||||
- **沙盒隔离的作用:** 内容进程只能访问特定的、受限的资源,它不能直接读取或写入用户的文件系统、摄像头、麦克风等关键系统资源。即便网页中包含恶意代码,由于沙盒的隔离作用,攻击者也难以突破浏览器的限制,损害用户的系统安全。
|
||||
- **减少恶意威胁:** 沙盒化机制有效阻止了通过浏览器攻击系统核心的企图,使得恶意网站、脚本无法获取到系统敏感资源。它还能够减少浏览器插件或第三方扩展中的潜在安全漏洞对系统的威胁。
|
||||
|
||||
通过内容进程的沙盒化,Firefox 在保护用户免受恶意网站攻击方面大大增强了安全性。
|
||||
|
||||
### 内容安全策略(CSP, Content Security Policy)
|
||||
|
||||
**内容安全策略**(Content Security Policy, CSP)是用于防止跨站脚本(XSS)和数据注入攻击的浏览器安全机制。CSP 允许 Web 开发者通过设置 HTTP 头部,明确指定哪些外部资源可以加载,哪些资源应被禁止。
|
||||
|
||||
#### 防止 XSS 攻击
|
||||
|
||||
**跨站脚本攻击(XSS)**是最常见的网络攻击之一,攻击者通过在网页中插入恶意脚本,窃取用户数据或执行不受信任的操作。CSP 通过限制哪些外部脚本可以加载,帮助开发者防止这些攻击。
|
||||
|
||||
- **CSP 的工作机制**:开发者可以在响应头中指定允许加载的资源源,例如脚本、样式、图像等。只有符合 CSP 策略的资源才会被浏览器加载。
|
||||
|
||||
示例 CSP 头部:
|
||||
|
||||
```http
|
||||
Content-Security-Policy: script-src 'self' https://trusted.cdn.com
|
||||
```
|
||||
|
||||
在上面的示例中,只有来自当前站点(`self`)和受信任的 CDN(`https://trusted.cdn.com`)的脚本才能被加载,其他来源的脚本将被阻止执行。
|
||||
|
||||
- **防止恶意注入**:通过严格控制资源加载的来源,CSP 可以有效阻止通过注入 HTML、JavaScript 或第三方插件带来的潜在安全威胁,尤其是那些试图窃取用户会话或操控页面行为的攻击。
|
||||
|
||||
CSP 不仅是防御 XSS 攻击的关键工具,还能用于加强其他安全防护措施,防止未经授权的内容加载到网页中。
|
||||
|
||||
## Firefox 扩展开发
|
||||
|
||||
Firefox 通过**WebExtensions API**提供了一个强大且灵活的扩展开发平台,允许开发者创建**与 Chrome 等其他浏览器兼容的跨浏览器扩展。**开发者可以通过 Firefox 的工具和平台进行调试和发布扩展,确保其符合安全和性能标准。
|
||||
|
||||
### WebExtensions API
|
||||
|
||||
**WebExtensions API**是 Firefox 的标准扩展开发框架,旨在简化扩展开发,并与其他主流浏览器(如 Chrome、Edge 和 Opera)的扩展生态系统兼容。WebExtensions API 使得开发者能够编写一个扩展,在多个浏览器上运行,大大降低了开发和维护的复杂性。
|
||||
|
||||
#### 扩展兼容性
|
||||
|
||||
Firefox 支持基于**WebExtensions API**的扩展,与 Chrome 等浏览器的扩展系统高度兼容。开发者可以使用几乎相同的代码库在不同浏览器上发布扩展,这使得跨浏览器扩展的开发变得更加方便和高效。
|
||||
|
||||
WebExtensions API 通过统一的接口,提供访问浏览器的核心功能(如标签管理、网络请求拦截、书签操作等)。这意味着开发者可以为多个浏览器创建同一个扩展,而无需为每个浏览器单独开发版本。
|
||||
|
||||
#### manifest.json 文件
|
||||
|
||||
每个 Firefox 扩展都有一个**manifest.json**文件,它是扩展的核心配置文件,定义了扩展的权限、图标、背景脚本、内容脚本和其他关键信息。它的结构与 Chrome 扩展的 manifest 文件非常相似,使得开发者能够轻松适配其他浏览器。
|
||||
|
||||
**基本结构**:
|
||||
|
||||
```json
|
||||
{
|
||||
"manifest_version": 2,
|
||||
"name": "My Firefox Extension",
|
||||
"version": "1.0",
|
||||
"description": "An example of a Firefox extension",
|
||||
"icons": {
|
||||
"48": "icons/icon-48.png",
|
||||
"96": "icons/icon-96.png"
|
||||
},
|
||||
"permissions": [
|
||||
"storage",
|
||||
"activeTab",
|
||||
"tabs"
|
||||
],
|
||||
"background": {
|
||||
"scripts": ["background.js"]
|
||||
},
|
||||
"content_scripts": [
|
||||
{
|
||||
"matches": ["*://*.example.com/*"],
|
||||
"js": ["content.js"]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**关键字段**:
|
||||
|
||||
- **`name`**:扩展的名称。
|
||||
- **`version`**:扩展的版本号。
|
||||
- **`permissions`**:定义扩展所需的权限,如访问标签页、存储数据、修改页面内容等。
|
||||
- **`background`**:指定运行在后台的脚本,用于处理事件和状态。
|
||||
- **`content_scripts`**:注入到特定页面的脚本,用于操作页面 DOM 或修改其行为。
|
||||
|
||||
通过 manifest 文件,开发者可以定义扩展的行为和所需的浏览器权限,以确保功能的实现和资源的适当管理。
|
||||
|
||||
### 开发与调试
|
||||
|
||||
#### Firefox DevTools
|
||||
|
||||
Firefox 提供了强大的**DevTools**,帮助开发者调试扩展的运行状态。DevTools 可以调试扩展的**内容脚本**和**后台脚本**,分析其执行流程,查看网络请求,甚至调试扩展与浏览器之间的消息传递。
|
||||
|
||||
- **调试内容脚本**:开发者可以通过 DevTools 的“Inspector”选项卡,查看页面上注入的内容脚本是否正确执行,以及是否对 DOM 进行了预期的修改。
|
||||
|
||||
- **调试后台脚本**:通过 DevTools 中的“Debugger”工具,开发者可以调试后台脚本,设置断点、查看变量、跟踪事件响应等。后台脚本是扩展中的长期运行脚本,常用于管理事件监听和状态维护。
|
||||
|
||||
**示例:调试后台脚本**
|
||||
|
||||
```javascript
|
||||
chrome.runtime.onInstalled.addListener(function() {
|
||||
console.log("Extension installed");
|
||||
});
|
||||
|
||||
chrome.tabs.onUpdated.addListener(function(tabId, changeInfo, tab) {
|
||||
if (changeInfo.status === "complete") {
|
||||
console.log("Tab updated:", tab.url);
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
通过 DevTools,开发者可以轻松排查扩展中的问题,确保它们在不同浏览器上下文中正确运行。
|
||||
|
||||
#### 扩展开发流程
|
||||
|
||||
- **安装扩展**:在 Firefox 的扩展管理界面,开发者可以将扩展以开发者模式加载到浏览器中,无需发布到 AMO。这可以方便开发和测试过程。
|
||||
- **调试与日志**:开发者可以在扩展中使用 `console.log` 进行调试,所有的日志输出都可以通过 DevTools 的“Console”面板查看。
|
||||
|
||||
### 发布扩展
|
||||
|
||||
#### 发布到 AMO 平台
|
||||
|
||||
**addons.mozilla.org(AMO)**是 Mozilla 官方的扩展发布平台。开发者在完成扩展开发后,可以通过 AMO 将扩展发布给全球用户。与 Chrome Web Store 相比,Firefox 对扩展的审查要求更为严格,重点关注隐私和安全性。
|
||||
|
||||
- 审查流程:
|
||||
- 扩展提交到 AMO 后,会经过自动和手动审查。审查主要检测扩展的代码是否包含恶意行为,是否有不必要的权限请求,以及是否符合 Mozilla 的隐私政策。
|
||||
- **权限审核**:Firefox 对扩展请求的权限有着严格的要求,开发者必须在 manifest 文件中明确声明所需权限,并确保这些权限的使用符合隐私保护要求。
|
||||
|
||||
#### 3.2 扩展的打包和上传
|
||||
|
||||
- **打包扩展**:开发者需要将扩展打包为 `.zip` 或 `.xpi` 文件格式。在开发完成后,可以通过扩展管理页面或命令行工具进行打包。
|
||||
- **上传扩展**:进入 AMO 开发者页面后,开发者可以上传打包好的扩展。上传后,扩展将进入审查队列,审查通过后即可公开发布。
|
||||
- **开发者控制面板**:AMO 为开发者提供了详细的扩展管理控制面板,开发者可以管理扩展的版本更新、用户反馈和下载统计。
|
||||
|
||||
## Firefox 的前沿技术
|
||||
|
||||
Firefox 始终致力于推动 Web 技术的前沿发展,并为开发者提供功能强大的平台,以构建高效、现代化的 Web 应用。**渐进式 Web 应用(PWA)**和**WebAssembly(WASM)**是两项重要的前沿技术,Firefox 通过持续优化对这些技术的支持,推动 Web 应用的性能、可用性和开发效率的提升。
|
||||
|
||||
### 渐进式 Web 应用(PWA, Progressive Web App)
|
||||
|
||||
渐进式 Web 应用(PWA)旨在提供类原生应用的 Web 体验,通过增加离线支持、推送通知和跨设备兼容等功能,使 Web 应用更加灵活、强大。Firefox 对 PWA 的支持为用户带来了高效、流畅的使用体验,增强了 Web 应用的功能性。
|
||||
|
||||
#### Service Workers 与缓存
|
||||
|
||||
**Service Workers** 是 PWA 的核心技术之一,运行在浏览器后台,独立于主页面,提供了强大的功能,如离线支持、缓存管理和通知推送。Firefox 对 Service Workers 的支持使得 PWA 能够在网络不稳定甚至无网络的情况下正常运行。
|
||||
|
||||
- **离线支持**:通过 Service Workers,PWA 可以缓存关键资源,并在用户离线时使用这些缓存资源来渲染页面。缓存的资源可以包括 HTML、CSS、JavaScript 和图片等,确保用户能够在没有网络连接的情况下使用应用。
|
||||
|
||||
**示例:Service Worker 的缓存机制**:
|
||||
|
||||
```javascript
|
||||
self.addEventListener('install', (event) => {
|
||||
event.waitUntil(
|
||||
caches.open('my-cache').then((cache) => {
|
||||
return cache.addAll([
|
||||
'/',
|
||||
'/index.html',
|
||||
'/styles.css',
|
||||
'/script.js'
|
||||
]);
|
||||
})
|
||||
);
|
||||
});
|
||||
|
||||
self.addEventListener('fetch', (event) => {
|
||||
event.respondWith(
|
||||
caches.match(event.request).then((response) => {
|
||||
return response || fetch(event.request);
|
||||
})
|
||||
);
|
||||
});
|
||||
```
|
||||
|
||||
- **通知推送**:Service Workers 还能接收推送通知,即使 PWA 未被打开时,用户也能收到消息。这使得 PWA 具备了与原生应用类似的互动功能,增强了用户参与度。
|
||||
|
||||
#### Manifest 文件与图标管理
|
||||
|
||||
**Manifest 文件** 是 PWA 的配置文件,用于定义应用的名称、图标、启动 URL、显示模式(如全屏或固定窗口)、主题颜色等。通过 Manifest 文件,PWA 能够在用户设备上创建一个快捷方式,提供类似原生应用的启动体验。
|
||||
|
||||
- **图标与启动配置**:Manifest 文件定义了 PWA 的图标、启动画面以及显示模式。通过这些配置,PWA 不仅可以在桌面或移动设备上创建图标,还能够控制应用在不同设备上的呈现方式,如全屏模式运行或以固定窗口形式显示。
|
||||
|
||||
**示例:manifest.json 文件**:
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "My Progressive Web App",
|
||||
"short_name": "MyPWA",
|
||||
"start_url": "/index.html",
|
||||
"icons": [
|
||||
{
|
||||
"src": "/icons/icon-192.png",
|
||||
"sizes": "192x192",
|
||||
"type": "image/png"
|
||||
},
|
||||
{
|
||||
"src": "/icons/icon-512.png",
|
||||
"sizes": "512x512",
|
||||
"type": "image/png"
|
||||
}
|
||||
],
|
||||
"background_color": "#ffffff",
|
||||
"theme_color": "#2196F3",
|
||||
"display": "standalone"
|
||||
}
|
||||
```
|
||||
|
||||
- **Firefox 对 PWA 的支持**:Firefox 允许用户将 PWA 应用安装到设备桌面,并通过 Manifest 文件管理图标和启动行为,提供更接近原生应用的用户体验。此外,Firefox 的**开发者工具(DevTools)**中还包含 PWA 调试功能,开发者可以检查缓存、查看 Service Worker 的状态等。
|
||||
|
||||
### WebAssembly(WASM)
|
||||
|
||||
**WebAssembly(WASM)** 是一种二进制指令格式,允许开发者在浏览器中运行接近原生性能的代码。Firefox 对 WebAssembly 的支持,极大提升了浏览器中运行复杂任务的效率,如 3D 渲染、加密运算和高性能游戏。
|
||||
|
||||
#### WebAssembly 在 Firefox 中的支持
|
||||
|
||||
WebAssembly 提供了运行高效代码的能力,使得浏览器不仅能够处理传统的 Web 任务,还能承担一些计算密集型的操作,如图像处理、机器学习模型训练、游戏渲染等。
|
||||
|
||||
- **高性能计算**:WASM 通过将高级语言(如 C、C++、Rust)编译成高效的字节码,并在浏览器中运行,从而实现接近原生性能的执行速度。它专为性能而设计,能够在浏览器中快速运行复杂算法、3D 图形处理和实时视频编辑等任务。
|
||||
- **跨平台支持**:WASM 是一种跨浏览器、跨平台的技术,Firefox 和其他主流浏览器(如 Chrome、Edge)都支持 WebAssembly,这使得开发者能够编写一次代码,在多个平台上高效运行。
|
||||
|
||||
#### JavaScript 与 WASM 的互操作
|
||||
|
||||
虽然 WebAssembly 具有很高的性能,但它与 JavaScript 并不是竞争关系,而是互为补充。开发者可以在 JavaScript 代码中调用 WebAssembly 模块,并通过 API 在两者之间进行数据交换和函数调用。JavaScript 负责页面交互、UI 控制等任务,而 WebAssembly 处理高性能计算任务。
|
||||
|
||||
- **调用 WASM 模块**:开发者可以通过 JavaScript 加载 WASM 模块,并调用其中的函数。通过这种互操作机制,开发者可以结合两者的优势,构建高效的 Web 应用。
|
||||
|
||||
**示例:JavaScript 调用 WASM 模块**:
|
||||
|
||||
```javascript
|
||||
fetch('module.wasm').then(response =>
|
||||
response.arrayBuffer()
|
||||
).then(bytes =>
|
||||
WebAssembly.instantiate(bytes)
|
||||
).then(results => {
|
||||
console.log(results.instance.exports.add(5, 10)); // 假设WASM模块中有add函数
|
||||
});
|
||||
```
|
||||
|
||||
- **数据交换与性能优化**:JavaScript 和 WebAssembly 之间的通信性能已经被大幅优化,特别是在处理大数据集和复杂的计算时,WASM 可以显著提升速度,而 JavaScript 则提供了灵活的控制和接口。
|
||||
251
Technology/WebDevelopment/1.Browser/4.DevTools.md
Normal file
251
Technology/WebDevelopment/1.Browser/4.DevTools.md
Normal file
@ -0,0 +1,251 @@
|
||||
---
|
||||
title: DevTools
|
||||
description: Chrome DevTools 是一组内置于 Google Chrome 浏览器中的前端开发和调试工具,为开发者提供页面结构分析、性能优化等全方位支持。它包括实时编辑、JavaScript调试、性能分析、网络请求分析等多种功能,旨在提升调试效率和开发体验。
|
||||
keywords:
|
||||
- DevTools
|
||||
- 调试
|
||||
- 性能优化
|
||||
- 实时编辑
|
||||
- 网络分析
|
||||
tags:
|
||||
- 标签
|
||||
author: 仲平
|
||||
date: 2024-09-30
|
||||
---
|
||||
|
||||
## DevTools
|
||||
|
||||
|
||||
|
||||
**Chrome DevTools 是 Google Chrome 浏览器内置的一套强大且灵活的前端开发和调试工具集。** 它为前端开发人员提供了从页面结构分析到性能优化的全方位支持,能够大幅提升调试效率与开发体验。通过 DevTools,开发者可以深入页面渲染过程,实时修改资源,查看并优化性能瓶颈,确保应用程序的高效运行。
|
||||
|
||||
> [Chrome DevTools 官方文档](https://developer.chrome.com/docs/devtools?hl=zh-cn)
|
||||
|
||||
### DevTools 核心功能
|
||||
|
||||
Chrome DevTools 提供了一系列关键功能,涵盖了从调试到优化的多种开发需求。以下是其主要功能模块:
|
||||
|
||||
#### 调试和诊断
|
||||
|
||||
- **JavaScript 调试:** 提供断点调试功能,允许开发者在代码执行时设置断点,逐步执行代码,查看变量的实时值,从而定位和修复问题。
|
||||
- **DOM 事件追踪:** 支持追踪和监控 DOM 元素的事件绑定情况,帮助开发者理解事件触发顺序及其背后的逻辑。
|
||||
- **网络请求分析:** 通过网络面板(Network Tab),开发者可以查看所有页面加载的 HTTP 请求,包括资源的加载时间、状态码、请求头和响应头等,帮助分析网络层面的性能瓶颈。
|
||||
|
||||
#### 性能分析
|
||||
|
||||
- **页面加载时间分析:** 通过 Timeline 和 Performance 面板,开发者可以检测页面从加载到完成渲染的各个阶段的性能,帮助定位造成加载缓慢的原因。
|
||||
- **帧率监控:** 帧率(FPS)是衡量页面交互性能的重要指标,DevTools 能够展示页面在用户交互过程中每一帧的渲染时间,便于分析动画和过渡效果的流畅性。
|
||||
- **内存占用分析:** Memory 面板允许开发者分析页面的内存使用情况,检测内存泄漏并优化内存管理,特别是对单页应用(SPA)而言,这一功能尤为重要。
|
||||
|
||||
#### 实时编辑
|
||||
|
||||
- **DOM 和 CSS 的实时修改:** Elements 面板允许开发者直接在浏览器中编辑 HTML 和 CSS,实时查看修改效果,支持快速调试页面样式和布局。
|
||||
- **JavaScript 实时执行:** 在 Console 面板中,开发者可以直接输入 JavaScript 代码并立即执行,这种交互式的代码运行方式便于快速测试脚本功能。
|
||||
- **样式计算与渲染分析:** DevTools 提供了渲染树的可视化工具,展示元素的样式计算和渲染情况,有助于理解页面样式的层叠与继承机制。
|
||||
|
||||
### DevTools 的跨平台支持
|
||||
|
||||
**作为 Chrome 浏览器的内置工具,DevTools 在多个操作系统上具有一致的功能表现。** 无论是在 Windows、macOS 还是 Linux 系统上,开发者均可通过相同的界面与功能集进行调试。Chrome 的跨平台支持确保了开发者在不同开发环境中的无缝切换,从而提高开发效率。
|
||||
|
||||
### DevTools 的开放性与扩展性
|
||||
|
||||
除了内置的功能外,DevTools 还支持扩展和自定义功能。开发者可以利用 Chrome DevTools Protocol 与自身的调试流程进行集成,并创建自定义工具以满足特定的调试需求。同时,随着前端技术的演进,DevTools 也不断更新,增加了如 Lighthouse 这样的工具模块,用于自动化页面性能和可访问性分析。
|
||||
|
||||
## DevTools 的核心面板
|
||||
|
||||
### Elements 面板
|
||||
|
||||
|
||||
|
||||
#### DOM 树与实时编辑
|
||||
|
||||
- **DOM 树的可视化展示**:Elements 面板通过树状结构显示页面的 DOM(文档对象模型)树,帮助开发者了解页面的层次结构及其元素的相互关系。
|
||||
- **实时编辑功能**:开发者可以直接在 DOM 树中编辑 HTML 标签、属性和内容,修改的结果会立即反映在浏览器中。这使得前端开发和调试过程更高效,便于快速迭代和视觉验证。
|
||||
- **DOM 节点操作**:除了编辑现有的 DOM 节点,开发者还可以通过上下文菜单添加、删除或重新排列元素,帮助更深入地理解页面结构。
|
||||
|
||||
#### CSS 样式调试
|
||||
|
||||
- **样式面板的动态编辑**:Elements 面板中的样式子面板允许开发者实时查看和编辑选中元素的 CSS 样式。通过修改现有规则、添加新规则或删除冗余样式,开发者可以快速调试布局和视觉问题。
|
||||
- **伪类状态模拟**:样式面板支持模拟特定的 CSS 伪类状态(如 `:hover`、`:focus`、`:active` 等),便于调试元素在不同交互状态下的样式。这在设计复杂交互时,尤其有用。
|
||||
- **CSS 样式层叠与优先级**:样式面板还展示了所有适用的 CSS 规则,并按照优先级排序,开发者可以查看哪个规则覆盖了其他规则,并深入了解 CSS 样式的层叠和继承机制。
|
||||
|
||||
#### 布局与盒模型
|
||||
|
||||
- **盒模型的可视化分析**:Elements 面板展示了所选元素的盒模型,明确显示其宽度、高度、内边距(padding)、边框(border)、外边距(margin)等信息。开发者可以点击并修改每个部分的数值,直观地调整布局。
|
||||
- **CSS Grid 和 Flexbox 调试工具**:对使用 CSS Grid 和 Flexbox 布局的页面,DevTools 提供了专门的可视化工具。开发者可以通过这些工具清楚地看到网格或弹性布局的结构和每个子元素的位置,方便调试和优化复杂布局。
|
||||
|
||||
### Console 面板
|
||||
|
||||
|
||||
|
||||
#### 调试与输出
|
||||
|
||||
- **实时日志输出**:Console 面板是调试 JavaScript 代码的主要工具之一,开发者可以使用 `console.log()`、`console.warn()`、`console.error()` 等方法输出不同类型的日志,以便查看变量值、函数执行结果或错误信息。
|
||||
- **交互式命令行**:Console 面板也充当了一个 JavaScript REPL(Read-Eval-Print Loop),允许开发者直接在其中输入并执行 JavaScript 代码,实时查看结果。这使得在无需刷新页面的情况下,快速验证代码片段或逻辑成为可能。
|
||||
- **自动补全与历史命令**:Console 提供智能代码补全和历史命令功能,帮助开发者更快地输入代码,并快速调用之前执行的命令,提高工作效率。
|
||||
|
||||
#### 错误和警告
|
||||
|
||||
- **错误检测**:当页面中出现 JavaScript 错误、网络请求失败或其他问题时,Console 面板会自动显示详细的错误信息。包括错误的具体行号、调用栈等,帮助开发者迅速定位并修复问题。
|
||||
- **日志过滤与级别分类**:开发者可以根据不同的日志级别(如信息、警告、错误)筛选输出内容,以便在调试时聚焦于关键问题。通过日志过滤功能,能够更好地管理大量输出信息。
|
||||
|
||||
### Sources 面板
|
||||
|
||||
|
||||
|
||||
#### 文件调试
|
||||
|
||||
- **文件浏览与加载**:Sources 面板显示页面中加载的所有 JavaScript 文件及其依赖项。开发者可以逐个浏览这些文件,并在需要的地方进行调试。
|
||||
- **代码断点设置**:通过在代码行上点击设置断点,开发者可以在代码执行时暂停,检查变量状态、调用栈和当前上下文,从而更加精确地定位和修复问题。
|
||||
|
||||
#### 断点调试
|
||||
|
||||
- 多种断点类型:
|
||||
- **行断点**:在特定的行设置断点,代码执行到此行时将暂停。
|
||||
- **条件断点**:开发者可以设置条件表达式,代码仅在条件满足时才会暂停执行。
|
||||
- **XHR 断点**:可以在发起特定的网络请求时自动暂停代码执行,方便调试 AJAX 请求等异步操作。
|
||||
- **调用栈分析**:当代码暂停时,开发者可以查看当前的调用栈,了解函数调用顺序及其参数和返回值,帮助理解代码的执行流。
|
||||
|
||||
#### 实时编辑和本地覆盖
|
||||
|
||||
- **JavaScript 实时编辑**:开发者可以在 Sources 面板中直接修改 JavaScript 文件,并立即预览这些修改在页面上的效果。这为临时调试提供了便捷方式,无需修改源码后再重新部署。
|
||||
- **Local Overrides**:通过 Local Overrides 功能,开发者可以将更改保存到本地,使页面在每次加载时都应用这些更改,从而模拟持久化修改,特别适用于调试第三方库或 CDN 加载的脚本。
|
||||
|
||||
#### JavaScript 执行顺序与异步堆栈
|
||||
|
||||
- **异步调试工具**:Sources 面板提供了异步任务的堆栈跟踪功能(如 `setTimeout`、`Promise`、`async/await`),允许开发者查看异步操作的执行顺序及其影响。这个功能使得调试异步代码变得更加直观,并帮助开发者理解 JavaScript 的事件循环和异步执行机制。
|
||||
|
||||
## DevTools 的性能优化功能
|
||||
|
||||
### Performance 面板
|
||||
|
||||
|
||||
|
||||
**Performance 面板提供了对页面加载、渲染和执行性能的全面分析。** 开发者可以通过点击**录制**按钮开始捕获页面的性能数据,并生成一份详细的时间轴报告。这些数据展示了从页面开始加载到用户可交互之间的整个过程,帮助开发者全面了解性能瓶颈所在。
|
||||
|
||||
在页面性能问题的定位过程中,Performance 面板可以捕获特定的时间段,如页面的首次加载、用户滚动、元素交互等,开发者可以选择性地关注和分析这些关键时刻的表现。
|
||||
|
||||
#### 关键性能指标
|
||||
|
||||
- **渲染路径分析**:Performance 面板通过详细的瀑布图展示页面的关键渲染路径,开发者可以识别导致性能瓶颈的因素,如长时间的 JavaScript 执行、阻塞式渲染、过多的重排和重绘等操作。通过这些信息,可以优化脚本加载顺序、减少不必要的 DOM 操作。
|
||||
- **FPS 分析**:帧率(FPS)是衡量动画和交互是否流畅的重要指标。Performance 面板实时监控页面的帧率,通过直观的图表展示页面在不同操作(如滚动、动画播放)下的帧率变化。帧率过低可能导致卡顿,特别是在复杂的视觉效果或页面滚动时,开发者可以通过优化动画性能或减少不必要的绘制操作提升用户体验。
|
||||
|
||||
#### 瀑布图与事件分析
|
||||
|
||||
- **瀑布图的可视化分析**:Performance 面板生成的瀑布图通过展示页面加载、脚本执行、样式计算、渲染和绘制的每一步,帮助开发者掌握页面每个事件的执行顺序与耗时。这些信息对于识别性能瓶颈(如阻塞的 JavaScript、慢速网络请求等)尤为关键。
|
||||
- **Layout Shift 与 CLS 分析**:性能优化过程中,**CLS(累计布局偏移)** 是一个重要的用户体验指标。Performance 面板可以展示页面布局的变化和偏移,帮助开发者识别不必要的页面元素重排和重绘,减少影响用户体验的布局移动,从而优化关键性能指标如 CLS。
|
||||
|
||||
### Lighthouse 面板
|
||||
|
||||
Lighthouse 是一个集成在 Chrome DevTools 中的开源性能分析工具,旨在自动化页面性能评估。它不仅能分析页面的性能,还覆盖了 SEO、可访问性、最佳实践和渐进式 Web 应用(PWA)支持等多个维度。通过 Lighthouse,开发者可以生成一份涵盖全面优化建议的评分报告,帮助提升 Web 应用的质量和用户体验。
|
||||
|
||||
#### Lighthouse 分析报告
|
||||
|
||||
- **自动化评分报告生成**:Lighthouse 通过自动化测试生成一份页面性能报告,评分范围从 0 到 100,涵盖页面性能的多个方面。每个维度都附带详细的改进建议,例如减少未使用的 JavaScript、优化图片加载、提升初始渲染速度等。
|
||||
- 核心 Web 指标(Core Web Vitals):报告特别关注核心 Web 指标,这些是评估用户体验的关键性能指标,包括:
|
||||
- **LCP(最大内容绘制)**:衡量页面主内容的加载速度,理想情况下应在 2.5 秒内完成。
|
||||
- **FID(首次输入延迟)**:反映页面的响应速度,较长的延迟会导致用户输入操作的迟滞。
|
||||
- **CLS(累计布局偏移)**:衡量页面中不可预见的视觉布局移动,得分越低越好,以确保视觉稳定性。
|
||||
|
||||
#### SEO 与可访问性
|
||||
|
||||
- **SEO 评估**:Lighthouse 的 SEO 模块分析页面是否符合搜索引擎优化(SEO)最佳实践,例如适当使用元标签、优化结构化数据、提升可抓取性等。优化页面的 SEO 有助于提高其在搜索引擎中的排名,从而吸引更多的访问者。
|
||||
- **可访问性分析**:Lighthouse 还评估页面的可访问性,确保网站对残障用户的友好程度。这包括检查页面元素的对比度、表单的可标记性、语义化 HTML 的使用等。提高页面的可访问性不仅符合道德规范和法律要求,还能提升所有用户的使用体验。
|
||||
|
||||
## DevTools 的网络分析功能
|
||||
|
||||
### Network 面板
|
||||
|
||||
|
||||
|
||||
Network 面板是调试和优化网络性能的核心工具,展示页面加载过程中所有的网络请求,包含 HTML、CSS、JavaScript、图片、字体等资源。开发者可以清晰地看到每个请求的加载顺序、状态码、文件大小、请求方法(如 GET、POST)和响应时间等详细信息,从而帮助分析和优化资源加载过程。
|
||||
|
||||
#### 资源加载时序图
|
||||
|
||||
- **时序图的可视化分析**:Network 面板中的时序图(Waterfall Chart)通过可视化的方式展示各个资源的加载时序,帮助开发者识别性能瓶颈。时序图按时间顺序排列资源请求,明确区分了各个阶段(如 DNS 解析、TCP 连接、请求发起与响应接收等)的时间消耗。借助这些信息,开发者可以发现阻塞渲染的资源,优化资源加载顺序,缩短关键渲染路径的时间。
|
||||
- 优化建议:
|
||||
- **图像优化**:图片文件过大是常见的加载瓶颈之一,开发者可以在 Network 面板中识别较大的图像资源,并通过使用更高效的图像格式(如 WebP)或压缩技术来减少文件大小。
|
||||
- **脚本异步加载**:Network 面板能够帮助开发者识别阻塞渲染的 JavaScript 文件,通过引入 `async` 或 `defer` 属性,开发者可以优化脚本加载顺序,防止页面渲染被阻塞。
|
||||
|
||||
#### HTTP 请求与响应
|
||||
|
||||
- **请求与响应的详细信息**:通过 Network 面板,开发者可以查看每个 HTTP 请求的完整信息,包括请求头(Request Headers)、响应头(Response Headers)、状态码(如 200、404、500 等)以及响应内容(如 HTML、JSON、图片等)。这有助于理解每个请求的交互过程以及网络层次上的问题。
|
||||
- **状态码与错误处理**:开发者可以轻松定位状态码为 4xx 或 5xx 的请求,以此诊断客户端或服务器端的错误。针对特定的错误,Network 面板还显示详细的调用信息,有助于快速定位问题的源头。
|
||||
- **缓存控制**:Network 面板可以展示每个资源的缓存命中情况,包括 Cache-Control 和 ETag 等缓存策略。通过分析这些缓存控制头信息,开发者可以判断资源是否被浏览器或 CDN 有效缓存,避免不必要的网络请求,提升页面加载速度。
|
||||
|
||||
#### 带宽与网络状况模拟
|
||||
|
||||
- **网络条件模拟**:Network 面板支持模拟不同的网络环境,开发者可以通过内置的带宽模拟器(如 3G、4G、慢速网络等)测试页面在各种网络条件下的表现。这有助于开发者验证页面在低带宽或高延迟环境中的响应速度,从而进行相应的优化。
|
||||
- **离线模式测试**:开发者还可以启用离线模式,模拟用户在没有网络连接时的页面表现,特别是对渐进式 Web 应用(PWA)的开发和调试非常有用。
|
||||
|
||||
### Application 面板
|
||||
|
||||
|
||||
|
||||
#### 存储与缓存
|
||||
|
||||
- 本地存储管理:Application 面板提供了对浏览器本地存储机制的全面访问,支持查看和管理以下几种存储类型:
|
||||
- **Cookie**:显示页面使用的所有 Cookie,开发者可以查看每个 Cookie 的详细信息(如名称、值、域名、到期时间、路径等),并直接编辑或删除它们以便调试用户会话和身份验证相关的问题。
|
||||
- **Local Storage 和 Session Storage**:开发者可以使用 Application 面板查看和编辑 Local Storage(本地存储)与 Session Storage(会话存储)中的键值对数据。这些存储机制常用于保存轻量级的用户数据,帮助页面实现状态持久化。
|
||||
- **IndexedDB 和 Web SQL**:对于更复杂的数据存储需求,开发者可以通过 Application 面板查看 IndexedDB 和 Web SQL 数据库中的信息。IndexedDB 是一种结构化的存储机制,适合存储大量数据或执行离线操作。
|
||||
- **缓存与存储管理**:Application 面板允许开发者管理页面缓存,包括浏览器缓存、Service Worker 缓存和离线缓存。开发者可以清除特定的缓存数据,或者检查缓存是否命中,以此调试页面的离线功能或缓存策略。
|
||||
|
||||
#### Service Workers 与 PWA 支持
|
||||
|
||||
Application 面板提供了对 Service Workers 的调试支持,开发者可以查看和管理页面注册的所有 Service Workers,并控制其生命周期(如启用、禁用或更新)。Service Workers 是 PWA 实现离线功能的核心组件,通过它们可以缓存页面资源,从而支持离线访问和增强的用户体验。
|
||||
|
||||
- **缓存策略优化**:开发者可以通过调试 Service Worker 的缓存策略,确保资源在离线状态下的可用性,同时避免过时的资源被长期缓存。Application 面板还允许模拟离线模式,从而验证 PWA 应用在无网络时的表现。
|
||||
- **PWA Manifest 调试**:Application 面板支持对 PWA Manifest 文件进行调试,确保页面具备符合 PWA 标准的元数据。Manifest 文件定义了 PWA 应用的名称、图标、启动 URL、主题颜色等,调试过程中,开发者可以检查这些属性是否正确配置,以确保应用在不同平台上的表现一致。
|
||||
|
||||
## DevTools 的调试与调试增强功能
|
||||
|
||||
### JavaScript 调试与断点管理
|
||||
|
||||
#### 断点类型
|
||||
|
||||
- **行断点**:最常见的断点类型,允许开发者在特定的代码行暂停执行,方便检查代码状态。通过在 Sources 面板中点击代码行数即可添加断点。
|
||||
- **条件断点**:适用于需要更精准调试的场景,开发者可以为断点指定条件表达式,只有当条件为真时,才会暂停执行代码。此功能极大减少了不必要的中断,提升调试效率。
|
||||
- **DOM 断点**:开发者可以对特定 DOM 元素设置断点,在其属性或结构发生变化时自动暂停代码执行。这种类型的断点特别适合调试复杂的页面交互和动态 DOM 操作。
|
||||
- **XHR 断点**:允许在发起或响应特定的网络请求时暂停 JavaScript 执行,便于调试 AJAX 请求、网络交互及其处理逻辑。
|
||||
- **断点调试**:设置断点后,开发者可以逐步执行代码,使用“步进(Step Over)”、“步入(Step Into)”和“步出(Step Out)”等操作控制代码的执行流程。调试过程中可以查看变量值、调用栈和上下文,帮助分析和理解代码的执行逻辑。
|
||||
|
||||
### DOM 断点与事件监听
|
||||
|
||||
#### DOM 断点
|
||||
|
||||
- **监控 DOM 变化**:DOM 断点能够精确捕捉页面结构的变化。例如,开发者可以在某个节点上设置断点,当该节点的内容、属性或位置发生修改时,代码执行会自动暂停。这对于调试意外的 DOM 修改、追踪动态内容生成非常有用。
|
||||
- **追踪 DOM 操作**:通过 DOM 断点,开发者可以调试那些可能由 JavaScript 动态修改的页面元素,定位哪一行代码引发了特定 DOM 节点的变化(如添加、删除、重排等)。
|
||||
|
||||
#### 事件监听
|
||||
|
||||
- **事件流追踪**:DevTools 提供事件监听功能,允许开发者查看页面上发生的所有事件(如鼠标点击、键盘输入等),并以列表形式显示事件的执行顺序和关联的元素。这对于调试复杂交互或事件冲突非常有效。
|
||||
- **事件断点**:开发者可以为特定的事件类型(如点击、提交等)设置全局断点,无论该事件在哪个元素上触发,代码都会暂停。这个功能帮助开发者从更高层次追踪整个事件流,从而掌握复杂的交互行为。
|
||||
|
||||
## DevTools 扩展与自定义
|
||||
|
||||
### DevTools 扩展与调试
|
||||
|
||||
#### 扩展 DevTools
|
||||
|
||||
Chrome 提供了丰富的 API,允许开发者通过编写扩展(Extension)来增强 DevTools 的功能。开发者可以为特定的调试需求定制工具,比如开发特定框架的调试插件(如 React 或 Vue)。
|
||||
|
||||
借助 Chrome DevTools Protocol,开发者可以构建自定义面板、工具条或其他 UI 组件,整合到 DevTools 中,满足复杂调试场景的个性化需求。自定义插件不仅可以扩展功能,还能改善调试体验,提高开发效率。
|
||||
|
||||
#### 远程调试
|
||||
|
||||
- **远程调试移动设备**:DevTools 提供了远程调试功能,开发者可以通过 USB 或无线连接调试 Android 设备上的移动端页面。在移动端性能优化、响应式设计调试等场景中,远程调试功能非常实用,能帮助开发者在真实设备上进行调试和优化。
|
||||
- **跨平台调试支持**:不仅限于 Android,DevTools 还支持远程调试其他平台上的 Web 应用,如在 Chrome 浏览器中远程调试不同操作系统的浏览器实例。
|
||||
|
||||
## DevTools 的前沿功能
|
||||
|
||||
### 进阶的性能优化与分析
|
||||
|
||||
#### WebAssembly 调试
|
||||
|
||||
- **调试 WebAssembly 模块**:DevTools 提供对 WebAssembly(WASM)的原生支持,允许开发者调试 WASM 代码,查看二进制模块的执行过程。开发者可以使用断点调试 WebAssembly 与 JavaScript 的交互,确保二者的无缝配合和高效执行。
|
||||
- **性能分析**:由于 WebAssembly 通常用于计算密集型任务,通过 DevTools 调试可以检测模块的执行效率,确保其能充分发挥出高性能优势,并发现潜在的性能瓶颈。
|
||||
|
||||
#### CPU 与内存分析
|
||||
|
||||
- **CPU 剖析器**:DevTools 提供的 CPU 剖析器可以帮助开发者检测 JavaScript 代码的执行时间,分析函数调用的耗时及其频率。对于计算密集型或复杂交互型页面,剖析器能直观展示代码的性能表现,帮助开发者找到最耗费 CPU 资源的部分,进行性能优化。
|
||||
- **内存使用检测**:通过 Memory 面板,开发者可以跟踪页面的内存使用情况,监控对象的分配与释放。借助内存快照和内存泄漏检测工具,开发者能够发现和修复内存泄漏问题,从而优化应用的内存使用,提高应用稳定性和性能。
|
||||
Loading…
Reference in New Issue
Block a user