Compare commits
6 Commits
4f56a4fe80
...
74d0cf7b7f
| Author | SHA1 | Date | |
|---|---|---|---|
|
74d0cf7b7f
|
|||
|
1ed6a5c193
|
|||
|
6b341f6031
|
|||
|
aaa7792970
|
|||
|
|
a84864d7e6
|
||
|
dc50f048aa
|
48
Journal/2024/W30/2024-07-25.md
Normal file
48
Journal/2024/W30/2024-07-25.md
Normal file
@ -0,0 +1,48 @@
|
||||
## 📅 Info
|
||||
|
||||
| Date | Lunar | Weather | Moon |
|
||||
| ------------------------------ | ------------------------- | ------------------------------------------------------------- | ----------------------------------------------- |
|
||||
| 周四 23:52 | 甲辰龙年 辛未月 庚寅日 农历六月二十 | 郑州 +27°C 🌦 | 🌖 |
|
||||
|
||||
## 📖 Daily
|
||||
|
||||
雾露夜侵衣,关山晓催轴。——吴均(南北朝)
|
||||
|
||||
## 😊 Emotions
|
||||
|
||||
- [ ] 😊 Happy
|
||||
- [ ] 😢 Sad
|
||||
- [x] 😡 Angry
|
||||
- [x] 😔 Disappointed
|
||||
- [ ] 😂 Laughing
|
||||
- [ ] 😭 Crying
|
||||
- [ ] 😱 Scared
|
||||
|
||||
## 🍎 Habits
|
||||
|
||||
- [ ] 🌅 Early to bed, early to rise
|
||||
- [x] 🥕 Healthy eating
|
||||
- [x] ☕️ Drink more hot water
|
||||
- [ ] 💪 Keep exercising
|
||||
- [ ] 🧘♂️ Meditation
|
||||
|
||||
## 📋 To-do List
|
||||
|
||||
- [x] 📰 Read news
|
||||
- [x] 📖 Read a book today
|
||||
- [ ] 📝 Make a plan for today
|
||||
- [ ] 🖋️ Calligraphy practice
|
||||
- [ ] 🎯 deliberate practice
|
||||
|
||||
## 🌟 Best Things
|
||||
|
||||
清理卫生
|
||||
计算机存储方面的学习
|
||||
|
||||
## 📝 Notes
|
||||
|
||||
今天真的无敌气,生活真的是一地鸡毛蒜皮。我也是真的非常之无奈!
|
||||
|
||||
不知道咋说了,瞎几把过吧。
|
||||
|
||||
晚安
|
||||
708
Tech/computer-storage/0. 大纲.md
Normal file
708
Tech/computer-storage/0. 大纲.md
Normal file
@ -0,0 +1,708 @@
|
||||
## 第一部分:基础知识
|
||||
|
||||
### 1. 计算机存储基础
|
||||
|
||||
#### 1.1 存储概念与术语
|
||||
|
||||
#### 1.2 存储介质类型
|
||||
|
||||
- 磁盘
|
||||
- SSD
|
||||
- 光盘
|
||||
- 磁带
|
||||
|
||||
#### 1.3 存储单元与数据表示
|
||||
|
||||
- 比特
|
||||
- 字节
|
||||
- 文件系统
|
||||
|
||||
#### 1.4 存储性能指标
|
||||
|
||||
- IOPS
|
||||
- 带宽
|
||||
- 延迟
|
||||
|
||||
#### 1.5 存储寿命和耐久性
|
||||
|
||||
#### 1.6 存储访问模式
|
||||
|
||||
- 顺序访问
|
||||
- 随机访问
|
||||
|
||||
### 2. 存储硬件
|
||||
|
||||
#### 2.1 磁盘驱动器(HDD)工作原理
|
||||
|
||||
- 垂直记录
|
||||
- 叠瓦式磁记录(SMR)
|
||||
|
||||
#### 2.2 固态驱动器(SSD)工作原理
|
||||
|
||||
- NVMe SSD 与 SATA SSD 的对比
|
||||
|
||||
#### 2.3 RAID(独立磁盘冗余阵列)技术
|
||||
|
||||
#### 2.4 磁带机与光盘存储
|
||||
|
||||
#### 2.5 硬盘缓存技术
|
||||
|
||||
### 3. 存储架构
|
||||
|
||||
#### 3.1 直接附加存储(DAS)
|
||||
|
||||
#### 3.2 网络附加存储(NAS)
|
||||
|
||||
#### 3.3 存储区域网络(SAN)
|
||||
|
||||
#### 3.4 存储架构的演变与发展
|
||||
|
||||
#### 3.5 存储网关和中继技术
|
||||
|
||||
## 第二部分:中级知识
|
||||
|
||||
### 4. 文件系统与数据管理
|
||||
|
||||
#### 4.1 文件系统类型
|
||||
|
||||
- **Linux 主流文件系统**
|
||||
- EXT 系列(EXT2、EXT3、EXT4)
|
||||
- Btrfs
|
||||
- XFS
|
||||
- ZFS
|
||||
- **Windows 主流文件系统**
|
||||
- NTFS
|
||||
- FAT32
|
||||
- exFAT
|
||||
- ReFS
|
||||
- **MacOS 主流文件系统**
|
||||
- HFS+
|
||||
- APFS
|
||||
|
||||
#### 4.2 文件系统结构与管理
|
||||
|
||||
- **文件系统结构**
|
||||
- 文件系统层次结构
|
||||
- 超级块、索引节点(Inode)、数据块
|
||||
- **文件系统管理**
|
||||
- 文件系统的创建与挂载
|
||||
- 文件系统的格式化和修复
|
||||
- 文件权限与用户管理
|
||||
|
||||
#### 4.3 数据冗余与备份策略
|
||||
|
||||
- **数据冗余技术**
|
||||
- RAID 类型与应用
|
||||
- 镜像、奇偶校验与分布式冗余
|
||||
- **备份策略**
|
||||
- 全量备份、增量备份与差异备份
|
||||
- 本地备份与远程备份
|
||||
- 备份的恢复与验证
|
||||
|
||||
#### 4.4 分布式文件系统与本地文件系统的对比
|
||||
|
||||
- **分布式文件系统**
|
||||
- Hadoop Distributed File System (HDFS)
|
||||
- Google File System (GFS)
|
||||
- GlusterFS
|
||||
- CephFS
|
||||
- **本地文件系统**
|
||||
- 单机文件系统的特性与应用场景
|
||||
- **对比分析**
|
||||
- 性能
|
||||
- 可扩展性
|
||||
- 数据一致性
|
||||
- 容错性
|
||||
|
||||
#### 4.5 数据完整性与校验技术
|
||||
|
||||
- **数据完整性**
|
||||
- 数据一致性检查
|
||||
- 数据腐败检测与恢复
|
||||
- **校验技术**
|
||||
- 校验和(Checksum)
|
||||
- 哈希函数
|
||||
- ECC(Error Correction Code)
|
||||
|
||||
#### 4.6 存储空间配额管理
|
||||
|
||||
- **配额管理概述**
|
||||
- 配额管理的意义与作用
|
||||
- **配额管理技术**
|
||||
- 用户配额与组配额
|
||||
- 软配额与硬配额
|
||||
- **管理工具与实践**
|
||||
- Linux 下的配额管理工具(如 `quota` 命令)
|
||||
- Windows 下的配额管理工具(如 FSRM)
|
||||
|
||||
### 5. 存储虚拟化
|
||||
|
||||
#### 5.1 存储虚拟化概念与原理
|
||||
|
||||
- **定义**:存储虚拟化是一种将物理存储资源抽象为虚拟存储资源的技术,使得存储设备可以更灵活和高效地被管理和使用。
|
||||
- **基本原理**:通过在存储资源和主机之间引入一个虚拟层,存储虚拟化将多个物理存储设备整合为一个或多个虚拟存储池。虚拟层负责管理和分配存储资源,提供统一的存储访问接口。
|
||||
- **优势**:
|
||||
- 提高存储利用率:通过整合分散的存储资源,减少未使用的存储空间。
|
||||
- 简化存储管理:提供集中化的管理界面,简化存储设备的配置和维护。
|
||||
- 提高灵活性:能够动态调整和分配存储资源,满足不同应用的需求。
|
||||
- 提高数据保护:通过快照、复制等技术增强数据的可靠性和可用性。
|
||||
|
||||
#### 5.2 虚拟存储设备与 LUN(逻辑单元号)
|
||||
|
||||
- **虚拟存储设备**:
|
||||
- 是由存储虚拟化软件创建的抽象存储单元,可以映射到物理存储设备或存储池。
|
||||
- 为主机和应用程序提供统一的存储访问接口。
|
||||
- **逻辑单元号(LUN)**:
|
||||
- LUN 是存储虚拟化环境中用于标识虚拟存储设备的唯一标识符。
|
||||
- 主机通过 LUN 访问虚拟存储设备,将其视为普通的存储卷。
|
||||
- LUN 的创建、分配和管理由存储虚拟化软件控制,能够灵活调整大小和性能参数。
|
||||
|
||||
#### 5.3 软件定义存储(SDS)
|
||||
|
||||
- **定义**:SDS 是一种通过软件实现存储资源管理和控制的技术,将存储硬件和软件解耦。
|
||||
- **关键特性**:
|
||||
- **硬件独立性**:支持多种存储硬件,不受特定厂商限制。
|
||||
- **灵活扩展性**:通过添加软件和硬件资源,可以线性扩展存储容量和性能。
|
||||
- **自动化管理**:利用软件自动完成存储资源的配置、分配和优化,减少人工干预。
|
||||
- **数据服务**:提供高级数据服务,如快照、复制、压缩和重删,增强数据保护和效率。
|
||||
- **主要组件**:
|
||||
- **控制层**:负责存储资源的管理和调度,包括存储池的创建和管理。
|
||||
- **数据层**:实际存储数据的物理存储设备,通常包括磁盘、SSD 等。
|
||||
- **管理层**:提供集中化的管理界面和 API,供管理员配置和监控存储系统。
|
||||
|
||||
#### 5.4 存储虚拟化在数据中心的应用
|
||||
|
||||
- **资源整合**:将分散的存储设备整合为统一的存储池,提高存储资源利用率。
|
||||
- **高可用性**:通过虚拟化技术实现存储的冗余和故障转移,确保数据的高可用性和可靠性。
|
||||
- **动态资源分配**:根据业务需求动态调整存储资源的分配,优化性能和成本。
|
||||
- **数据保护**:利用快照、复制和备份等技术增强数据的保护能力,防止数据丢失和损坏。
|
||||
- **简化管理**:集中化的管理界面和自动化工具简化了存储设备的配置、监控和维护,降低了管理复杂度。
|
||||
|
||||
#### 5.5 常见的存储虚拟化解决方案
|
||||
|
||||
- **VMware vSAN**:
|
||||
- **概述**:VMware vSAN 是集成在 VMware vSphere 中的软件定义存储解决方案,通过将服务器的本地存储资源整合为共享存储池。
|
||||
- **特性**:
|
||||
- 高性能:利用闪存和 SSD 提高存储性能。
|
||||
- 高可用性:提供存储冗余和自动故障转移。
|
||||
- 可扩展性:支持线性扩展存储容量和性能。
|
||||
- 集中管理:通过 vSphere 管理界面进行统一管理。
|
||||
- **Microsoft Storage Spaces Direct (S2D)**:
|
||||
- **概述**:S2D 是 Microsoft Windows Server 中的一项功能,通过聚合本地存储资源提供高性能、高可用性的存储解决方案。
|
||||
- **特性**:
|
||||
- 高性能:支持使用 NVMe、SSD 和 HDD 实现多层次存储。
|
||||
- 高可用性:通过镜像、条带化和纠删码提供数据保护。
|
||||
- 可扩展性:支持从两个节点扩展到多个节点的集群。
|
||||
- 集成管理:与 Windows Server 深度集成,提供统一的管理和监控工具。
|
||||
|
||||
### 6. 存储网络
|
||||
|
||||
#### 6.1 网络存储协议
|
||||
|
||||
- **iSCSI(Internet Small Computer System Interface)**:
|
||||
|
||||
- **定义**:一种基于 IP 网络的存储协议,通过 TCP/IP 传输 SCSI 指令,使存储设备可以通过网络连接到主机。
|
||||
- **优势**:低成本、易于配置和扩展,适用于中小型企业。
|
||||
- **应用场景**:虚拟化环境、远程备份和恢复、灾难恢复等。
|
||||
- **Fibre Channel(FC)**:
|
||||
|
||||
- **定义**:一种高速网络协议,专门用于存储区域网络(SAN),通过光纤或铜缆传输数据。
|
||||
- **优势**:高带宽、低延迟、可靠性高,适用于大规模数据中心。
|
||||
- **应用场景**:企业级存储网络、大型数据库和高性能计算等。
|
||||
- **NFS(Network File System)**:
|
||||
|
||||
- **定义**:一种网络文件系统协议,允许不同操作系统的计算机通过网络共享文件。
|
||||
- **优势**:跨平台兼容、易于配置和管理,适用于文件共享和协作。
|
||||
- **应用场景**:企业文件共享、网络附加存储(NAS)设备、虚拟化环境等。
|
||||
- **SMB(Server Message Block)**:
|
||||
|
||||
- **定义**:一种网络文件共享协议,允许计算机通过网络访问和共享文件、打印机和串行端口。
|
||||
- **优势**:与 Windows 系统深度集成、易于使用,适用于 Windows 环境的文件共享。
|
||||
- **应用场景**:企业文件共享、家庭网络、网络附加存储(NAS)设备等。
|
||||
|
||||
#### 6.2 存储网络架构与配置
|
||||
|
||||
- **存储区域网络(SAN)**:
|
||||
|
||||
- **定义**:一种专用的高性能网络,用于连接存储设备和服务器,提供块级存储访问。
|
||||
- **架构**:由存储设备、交换机、HBA(主机总线适配器)和光纤通道组成。
|
||||
- **配置**:包括存储设备的分配和管理、交换机的配置和优化、HBA 的安装和配置。
|
||||
- **网络附加存储(NAS)**:
|
||||
|
||||
- **定义**:一种通过网络提供文件级存储访问的设备,通常包含一个或多个硬盘,连接到网络并提供文件共享服务。
|
||||
- **架构**:由 NAS 设备、网络交换机和客户端设备组成。
|
||||
- **配置**:包括 NAS 设备的设置、网络连接和文件共享配置。
|
||||
|
||||
#### 6.3 数据传输与吞吐量优化
|
||||
|
||||
- **带宽管理**:确保存储网络有足够的带宽处理数据传输,避免网络拥堵。
|
||||
- **负载均衡**:分配数据流量到多个路径,优化网络资源利用率,减少单点故障。
|
||||
- **QoS(服务质量)**:设置网络服务质量参数,优先处理关键任务的数据流,提高传输效率。
|
||||
- **缓存技术**:使用缓存设备或技术(如 SSD 缓存)加速数据读取和写入,提高整体吞吐量。
|
||||
|
||||
#### 6.4 存储网络的拓扑结构设计
|
||||
|
||||
- **星型拓扑**:所有存储设备和服务器通过中央交换机连接,便于管理和扩展。
|
||||
- **树型拓扑**:分级连接多个交换机,适用于大规模网络,提高网络的扩展性和容错性。
|
||||
- **环型拓扑**:设备之间通过环形连接,提供冗余路径,提高网络的可靠性。
|
||||
- **网状拓扑**:每个设备都与多个其他设备连接,提供高度冗余和灵活性,但管理复杂度高。
|
||||
|
||||
#### 6.5 存储网络的安全性与防护
|
||||
|
||||
- **访问控制**:通过用户身份验证和访问控制列表(ACL)限制对存储资源的访问。
|
||||
- **数据加密**:在传输和存储过程中对数据进行加密,防止数据泄露和未授权访问。
|
||||
- **防火墙和 VPN**:使用防火墙保护存储网络免受外部攻击,通过 VPN 实现安全的远程访问。
|
||||
- **日志和审计**:记录所有访问和操作日志,定期审计以发现和处理安全威胁。
|
||||
|
||||
#### 6.6 存储网络的监控与故障排除
|
||||
|
||||
- **监控工具**:使用存储网络监控工具(如 Nagios、SolarWinds)实时监控网络性能和健康状态。
|
||||
- **性能分析**:定期分析网络性能指标(如带宽利用率、延迟、吞吐量)识别潜在问题。
|
||||
- **故障排除**:
|
||||
- **诊断工具**:使用网络诊断工具(如 Wireshark)捕获和分析网络流量。
|
||||
- **日志分析**:检查设备日志和错误报告,定位问题源。
|
||||
- **冗余路径**:利用网络冗余路径和设备快速恢复故障,提高网络可用性。
|
||||
|
||||
## 第三部分:高级知识
|
||||
|
||||
### 7. 高性能存储技术
|
||||
|
||||
#### 7.1 NVMe(非易失性内存快车)
|
||||
|
||||
- **定义**:NVMe(Non-Volatile Memory Express)是一种专为 SSD 设计的高性能接口协议,通过 PCIe 总线直接与 CPU 通信,减少了传统 SATA/SAS 接口的瓶颈。
|
||||
- **优势**:
|
||||
- **低延迟**:直接访问闪存,减少了中间层带来的延迟。
|
||||
- **高吞吐量**:通过并行处理大量 I/O 请求,提高了数据传输速度。
|
||||
- **高并发性**:支持多个并发命令队列,适用于高性能计算和大数据处理。
|
||||
- **应用场景**:高性能数据库、虚拟化环境、大数据分析和实时应用等。
|
||||
|
||||
#### 7.2 3D NAND 闪存技术
|
||||
|
||||
- **定义**:3D NAND 是一种垂直堆叠的闪存技术,通过将多个闪存单元垂直堆叠在一起,增加存储密度和容量。
|
||||
- **优势**:
|
||||
- **高密度**:相比传统 2D NAND,3D NAND 能够在相同面积上提供更多的存储容量。
|
||||
- **高耐久性**:改进的制造工艺和材料使用,延长了闪存的寿命。
|
||||
- **低成本**:更高的存储密度和更低的单位存储成本。
|
||||
- **应用场景**:消费级 SSD、企业级存储设备和移动设备等。
|
||||
|
||||
#### 7.3 储存级内存(SCM)
|
||||
|
||||
- **定义**:储存级内存(Storage Class Memory,SCM)是一种介于 DRAM 和传统存储设备之间的存储技术,结合了内存的高速度和存储设备的非易失性特点。
|
||||
- **类型**:
|
||||
- **Intel Optane**:基于 3D XPoint 技术的 SCM,具有高速度和高耐久性。
|
||||
- **MRAM(磁性随机存取存储器)**:利用磁性材料实现数据存储,具有高速度和非易失性。
|
||||
- **优势**:
|
||||
- **低延迟**:接近 DRAM 的速度,适用于高性能应用。
|
||||
- **高耐久性**:相比传统闪存,具有更高的写入耐久性。
|
||||
- **数据持久性**:断电后数据不会丢失。
|
||||
- **应用场景**:实时数据处理、内存密集型应用和高性能计算等。
|
||||
|
||||
#### 7.4 低延迟存储技术
|
||||
|
||||
- **Optane 存储**:
|
||||
- **定义**:基于 3D XPoint 技术的存储解决方案,提供了接近 DRAM 的速度和传统存储的非易失性。
|
||||
- **优势**:
|
||||
- **超低延迟**:大大降低了读取和写入延迟,提高了系统响应速度。
|
||||
- **高耐久性**:支持大量的写入操作,适用于高负载环境。
|
||||
- **大容量**:提供了比传统 DRAM 更高的容量选择。
|
||||
- **应用场景**:高频交易、实时分析、内存数据库和高性能计算等。
|
||||
|
||||
#### 7.5 存储缓存层和 Tiering 技术
|
||||
|
||||
- **存储缓存层**:
|
||||
|
||||
- **定义**:在存储系统中引入高速缓存层,将经常访问的数据存储在高速设备上,提高数据访问速度。
|
||||
- **技术**:
|
||||
- **SSD 缓存**:将部分数据缓存到 SSD,提高传统 HDD 的访问速度。
|
||||
- **RAM 缓存**:利用内存作为缓存,加速数据的读取和写入操作。
|
||||
- **优势**:提高系统的整体性能,减少数据访问延迟。
|
||||
- **应用场景**:数据库加速、虚拟化环境和高性能存储系统等。
|
||||
- **Tiering 技术**:
|
||||
|
||||
- **定义**:将存储系统中的数据根据访问频率和重要性分层存储在不同性能和成本的存储设备上。
|
||||
- **技术**:
|
||||
- **自动分层**:通过存储管理软件自动识别和移动数据到合适的存储层。
|
||||
- **手动分层**:管理员根据业务需求手动调整数据存储位置。
|
||||
- **优势**:优化存储资源利用,提高存储系统的性能和成本效益。
|
||||
- **应用场景**:企业存储系统、大数据分析和混合存储环境等。
|
||||
|
||||
### 8. 数据保护与安全
|
||||
|
||||
#### 8.1 数据加密技术
|
||||
|
||||
- **定义**:数据加密是通过算法将明文数据转换为密文,只有授权用户才能解密和访问数据。
|
||||
- **类型**:
|
||||
- **对称加密**:使用同一个密钥进行加密和解密,如 AES、DES。
|
||||
- **非对称加密**:使用公钥加密,私钥解密,如 RSA、ECC。
|
||||
- **应用**:
|
||||
- **存储加密**:对存储设备中的数据进行加密,保护静态数据的安全。
|
||||
- **传输加密**:对网络传输的数据进行加密,保护传输过程中的数据安全。
|
||||
- **实施**:
|
||||
- **硬件加密**:利用硬件设备(如硬件安全模块,HSM)进行数据加密。
|
||||
- **软件加密**:通过软件工具(如 OpenSSL)实现数据加密。
|
||||
|
||||
#### 8.2 存储安全策略与实施
|
||||
|
||||
- **定义**:存储安全策略是为保护存储系统及其数据免受威胁和攻击而制定的规则和措施。
|
||||
- **主要策略**:
|
||||
- **访问控制**:通过身份验证和授权管理,限制对存储系统和数据的访问。
|
||||
- **数据隔离**:将敏感数据与其他数据隔离,减少数据泄露风险。
|
||||
- **审计和监控**:对存储系统的访问和操作进行记录和监控,及时发现和应对安全事件。
|
||||
- **实施步骤**:
|
||||
- **风险评估**:识别存储系统的安全风险和漏洞。
|
||||
- **策略制定**:根据风险评估结果,制定存储安全策略。
|
||||
- **部署和实施**:将安全策略应用于存储系统,并定期更新和优化。
|
||||
|
||||
#### 8.3 数据灾难恢复与业务连续性
|
||||
|
||||
- **定义**:数据灾难恢复和业务连续性是为确保在灾难发生后快速恢复数据和业务运营而采取的措施。
|
||||
- **主要措施**:
|
||||
- **备份策略**:定期备份重要数据,确保数据在灾难发生后可以恢复。
|
||||
- **容灾方案**:建立异地灾难恢复中心,确保在主数据中心发生灾难时,业务可以快速切换到备用中心。
|
||||
- **业务连续性计划(BCP)**:制定详细的业务连续性计划,包括灾难应对措施、恢复步骤和责任分工。
|
||||
- **实施步骤**:
|
||||
- **风险评估**:识别可能影响业务连续性的灾难和威胁。
|
||||
- **策略制定**:根据风险评估结果,制定备份和容灾策略。
|
||||
- **演练和测试**:定期进行灾难恢复和业务连续性演练,确保计划可行。
|
||||
|
||||
#### 8.4 数据防篡改技术
|
||||
|
||||
- **定义**:数据防篡改技术是为保护数据的完整性,防止未经授权的修改而采取的措施。
|
||||
- **主要技术**:
|
||||
- **数字签名**:利用公钥加密技术生成数据的数字签名,验证数据的完整性和来源。
|
||||
- **哈希函数**:生成数据的唯一哈希值,用于检测数据是否被篡改。
|
||||
- **区块链技术**:利用区块链的不可篡改性和分布式账本技术,保护数据的完整性。
|
||||
- **应用**:
|
||||
- **文件完整性验证**:使用哈希值验证文件的完整性。
|
||||
- **数据审计**:利用数字签名和区块链技术,记录和验证数据操作的合法性。
|
||||
|
||||
#### 8.5 安全合规性标准与法规
|
||||
|
||||
- **GDPR(General Data Protection Regulation)**:
|
||||
|
||||
- **定义**:GDPR 是欧盟颁布的《通用数据保护条例》,旨在保护欧盟公民的个人数据隐私。
|
||||
- **主要要求**:
|
||||
- 数据收集和处理需获得用户明确同意。
|
||||
- 用户有权访问、修改和删除其个人数据。
|
||||
- 企业需采取适当措施保护用户数据,并在数据泄露时及时通知用户。
|
||||
- **实施**:企业需制定隐私政策,进行数据保护影响评估(DPIA),确保数据处理符合 GDPR 要求。
|
||||
- **HIPAA(Health Insurance Portability and Accountability Act)**:
|
||||
|
||||
- **定义**:HIPAA 是美国颁布的《健康保险携带和责任法案》,旨在保护患者的健康信息隐私。
|
||||
- **主要要求**:
|
||||
- 医疗机构需确保患者的健康信息机密性和安全性。
|
||||
- 采取技术和管理措施防止数据泄露和未经授权访问。
|
||||
- 提供数据访问和修改权限给患者,并在数据泄露时通知患者。
|
||||
- **实施**:医疗机构需制定和实施数据保护策略,进行定期安全审计和风险评估,确保符合 HIPAA 要求。
|
||||
|
||||
### 9. 云存储
|
||||
|
||||
#### 9.1 云存储概念与架构
|
||||
|
||||
- **定义**:云存储是一种通过互联网提供的在线存储服务,允许用户将数据存储在远程服务器上,随时随地访问和管理数据。
|
||||
- **架构**:
|
||||
- **前端接口**:用户通过 API、控制台或客户端应用访问云存储服务。
|
||||
- **存储层**:包括分布式文件系统、对象存储和块存储,负责数据的存储和管理。
|
||||
- **管理层**:提供数据管理、监控、备份和恢复等功能。
|
||||
- **网络层**:通过高速网络连接用户和存储服务器,确保数据传输的稳定性和安全性。
|
||||
|
||||
#### 9.2 公有云、私有云与混合云存储
|
||||
|
||||
- **公有云存储**:
|
||||
- **定义**:由第三方云服务提供商提供的存储服务,用户通过互联网访问和管理存储资源。
|
||||
- **优势**:无需购买和维护硬件设备,按需付费,具备高可扩展性和灵活性。
|
||||
- **应用场景**:中小企业、初创公司、动态负载应用等。
|
||||
- **私有云存储**:
|
||||
- **定义**:在企业内部或由第三方托管的数据中心部署的专用存储服务,企业独享存储资源。
|
||||
- **优势**:更高的安全性和控制性,满足合规性要求,性能可控。
|
||||
- **应用场景**:大型企业、政府机构、金融和医疗行业等。
|
||||
- **混合云存储**:
|
||||
- **定义**:结合公有云和私有云的存储解决方案,允许数据和应用在公有云和私有云之间自由迁移和管理。
|
||||
- **优势**:兼具公有云的灵活性和私有云的安全性,优化资源利用,降低成本。
|
||||
- **应用场景**:需要同时满足高安全性和高灵活性需求的企业。
|
||||
|
||||
#### 9.3 云存储服务
|
||||
|
||||
- **AWS S3(Amazon Simple Storage Service)**:
|
||||
- **特点**:高可用性、高持久性、可无限扩展的对象存储服务,提供多种存储类型(标准、智能分层、Glacier)。
|
||||
- **功能**:数据加密、访问控制、版本控制、跨区域复制、事件通知等。
|
||||
- **应用场景**:数据备份和恢复、大数据分析、内容分发、应用存储等。
|
||||
- **Azure Blob Storage**:
|
||||
- **特点**:适用于非结构化数据存储的对象存储服务,提供热存储、冷存储和存档存储三种层级。
|
||||
- **功能**:数据加密、访问控制、生命周期管理、静态网站托管等。
|
||||
- **应用场景**:备份和归档、流媒体存储、日志存储和分析、数据湖等。
|
||||
- **Google Cloud Storage**:
|
||||
- **特点**:全球统一命名空间的对象存储服务,提供标准、近线、冷线和存档四种存储类型。
|
||||
- **功能**:数据加密、访问控制、版本控制、跨区域复制、对象生命周期管理等。
|
||||
- **应用场景**:数据分析、机器学习、媒体内容存储、灾难恢复等。
|
||||
|
||||
#### 9.4 云存储的数据迁移策略
|
||||
|
||||
- **定义**:将数据从本地存储或其他存储平台迁移到云存储的过程和方法。
|
||||
- **策略**:
|
||||
- **离线迁移**:通过物理设备(如硬盘)将数据离线传输到云服务提供商的数据中心。
|
||||
- **在线迁移**:通过网络直接将数据传输到云存储,常用工具包括 AWS Snowball、Azure Data Box、Google Transfer Appliance。
|
||||
- **混合迁移**:结合离线和在线迁移方法,根据数据量和传输速度选择合适的策略。
|
||||
- **步骤**:
|
||||
- **评估和规划**:分析数据量、传输速度、安全性要求,制定迁移计划。
|
||||
- **数据准备**:对数据进行清理、压缩和加密,确保数据完整性和安全性。
|
||||
- **迁移执行**:按照计划进行数据迁移,监控迁移过程,处理异常情况。
|
||||
- **验证和优化**:迁移完成后,验证数据完整性和可访问性,进行性能优化和成本管理。
|
||||
|
||||
#### 9.5 云存储的成本管理与优化
|
||||
|
||||
- **定义**:通过优化资源使用和费用支出,提高云存储的成本效益。
|
||||
- **方法**:
|
||||
- **选择合适的存储类型**:根据数据访问频率选择合适的存储层级(如热存储、冷存储、存档存储)。
|
||||
- **生命周期管理**:设置数据生命周期策略,自动将不常访问的数据转移到低成本存储层级。
|
||||
- **数据压缩和重删**:减少存储空间占用,降低存储成本。
|
||||
- **监控和分析**:使用监控工具(如 AWS Cost Explorer、Azure Cost Management)实时监控存储费用,分析成本构成,优化资源使用。
|
||||
- **按需付费和预留实例**:结合按需付费和预留实例,平衡灵活性和成本效益。
|
||||
|
||||
#### 9.6 混合云环境下的数据管理
|
||||
|
||||
- **定义**:在混合云环境中,对分布在公有云和私有云的数据进行统一管理和协调。
|
||||
- **方法**:
|
||||
- **统一管理平台**:使用混合云管理平台(如 VMware Cloud Foundation、Microsoft Azure Arc)实现跨云的数据管理和协调。
|
||||
- **数据同步和复制**:设置数据同步和复制策略,确保公有云和私有云之间的数据一致性和高可用性。
|
||||
- **数据安全和合规**:在混合云环境中,确保数据传输和存储的安全性,符合相关法规和标准(如 GDPR、HIPAA)。
|
||||
- **性能优化**:监控和优化跨云数据传输性能,减少延迟,提高访问速度。
|
||||
- **成本管理**:通过统一管理和监控工具,优化混合云环境中的存储成本。
|
||||
|
||||
### 10. 大数据存储
|
||||
|
||||
#### 10.1 大数据存储需求与挑战
|
||||
|
||||
- **数据量**:随着数据量的爆炸式增长,传统存储系统难以应对海量数据的存储需求。
|
||||
- **数据类型**:大数据不仅包括结构化数据,还包括半结构化和非结构化数据,如文本、图像、视频等。
|
||||
- **数据访问**:需要高效的数据读取和写入性能,以支持大数据分析和实时处理。
|
||||
- **成本控制**:在满足性能需求的同时,控制存储系统的成本是一个重要挑战。
|
||||
- **数据安全与隐私**:在存储和传输过程中,确保数据的安全性和隐私保护。
|
||||
- **数据管理**:有效地管理和维护大量的数据,包括数据备份、恢复和生命周期管理。
|
||||
|
||||
#### 10.2 分布式文件系统
|
||||
|
||||
- **HDFS(Hadoop Distributed File System)**
|
||||
|
||||
- **架构**:NameNode 和 DataNode 的角色分工,主从架构。
|
||||
- **数据存储**:数据分块存储和副本机制,提高数据的可靠性和可用性。
|
||||
- **优缺点**:高容错性和可扩展性,但对小文件支持不佳。
|
||||
- **其他分布式文件系统**
|
||||
|
||||
- **Ceph**:一种统一的分布式存储系统,支持对象、块和文件存储。
|
||||
- **GlusterFS**:开源的分布式文件系统,具备高可用性和高扩展性。
|
||||
|
||||
#### 10.3 对象存储系统
|
||||
|
||||
- **概念**:对象存储将数据作为对象进行管理,每个对象包含数据、元数据和唯一标识符。
|
||||
- **优势**:高扩展性、支持海量数据存储、灵活的数据管理和检索方式。
|
||||
- **常见对象存储系统**
|
||||
- **Amazon S3**:AWS 提供的对象存储服务,具有高可用性和高耐久性。
|
||||
- **OpenStack Swift**:开源的对象存储系统,支持大规模集群部署。
|
||||
- **MinIO**:高性能的对象存储系统,兼容 Amazon S3 API。
|
||||
|
||||
#### 10.4 大数据存储的典型案例
|
||||
|
||||
- **Hadoop**
|
||||
|
||||
- **架构**:基于 HDFS 进行数据存储,利用 MapReduce 进行数据处理。
|
||||
- **应用场景**:适用于批量数据处理、大规模数据分析。
|
||||
- **优缺点**:强大的数据处理能力,但实时性较差。
|
||||
- **Cassandra**
|
||||
|
||||
- **架构**:去中心化、无主节点的分布式数据库,支持多数据中心的高可用性。
|
||||
- **数据模型**:基于列族存储,适合处理高吞吐量的写操作。
|
||||
- **应用场景**:实时数据分析、事务处理、日志记录。
|
||||
- **优缺点**:高扩展性和可用性,但查询复杂性较高。
|
||||
|
||||
#### 10.5 大数据存储的性能优化
|
||||
|
||||
- **数据分区**:通过数据分区提高数据访问的并行度。
|
||||
- **缓存机制**:利用缓存机制减少磁盘 I/O,提高访问速度。
|
||||
- **压缩技术**:通过数据压缩减少存储空间占用和数据传输时间。
|
||||
- **硬件优化**:使用高速硬盘(如 SSD)和高带宽网络设备,提升整体性能。
|
||||
- **数据预处理**:在数据写入前进行预处理,减少后续的处理负担。
|
||||
|
||||
#### 10.6 大数据存储的扩展性设计
|
||||
|
||||
- **水平扩展**:增加节点来扩展存储容量和计算能力,确保系统能处理越来越多的数据。
|
||||
- **负载均衡**:通过负载均衡机制,均匀分配数据和请求,避免单点瓶颈。
|
||||
- **自动化运维**:利用自动化工具进行运维管理,确保系统在扩展过程中的稳定性和可靠性。
|
||||
- **容错机制**:设计健壮的容错机制,确保在硬件故障或网络中断时,数据不丢失且系统能快速恢复。
|
||||
- **弹性计算**:结合云计算资源,实现按需扩展,满足动态变化的业务需求。
|
||||
|
||||
## 第四部分:现代化与分布式存储
|
||||
|
||||
### 11. 自建分布式存储系统
|
||||
|
||||
#### 11.1 分布式存储概念与优势
|
||||
|
||||
- **分布式存储的定义**:介绍分布式存储系统的基本概念,数据分布在多个节点上,通过网络进行访问和管理。
|
||||
- **优势**:
|
||||
- **扩展性**:能够根据需要增加存储节点,实现存储容量的线性扩展。
|
||||
- **高可用性**:通过数据冗余和多副本机制,确保系统在部分节点故障时仍能正常工作。
|
||||
- **高性能**:分布式存储能够利用多节点并行处理,提升数据读写速度。
|
||||
- **成本效益**:利用普通硬件构建高性能存储系统,降低成本。
|
||||
|
||||
#### 11.2 MinIO 安装与配置
|
||||
|
||||
- **MinIO 简介**:介绍 MinIO 的特点和应用场景。
|
||||
- **安装步骤**:
|
||||
- **环境准备**:系统要求和依赖安装。
|
||||
- **下载和安装**:从官网下载 MinIO 并进行安装。
|
||||
- **配置**:配置 MinIO 的存储路径、访问密钥等。
|
||||
- **启动和访问**:
|
||||
- **启动 MinIO 服务**。
|
||||
- **通过 Web 界面或命令行工具访问 MinIO**。
|
||||
|
||||
#### 11.3 Ceph 存储集群部署
|
||||
|
||||
- **Ceph 简介**:Ceph 的架构和核心组件(如 OSD、Monitor、MDS 等)。
|
||||
- **部署步骤**:
|
||||
- **环境准备**:系统要求、网络配置和依赖安装。
|
||||
- **集群初始化**:安装 Ceph 部署工具(如 ceph-deploy),初始化集群。
|
||||
- **节点部署**:添加 OSD 节点、Monitor 节点等。
|
||||
- **配置和调优**:配置 Ceph 的存储池、CRUSH map 等。
|
||||
- **使用和管理**:
|
||||
- **数据存储和访问**:通过 RADOS、CephFS、RBD 等方式访问存储数据。
|
||||
- **集群管理**:常用管理命令和操作(如监控、扩展、维护)。
|
||||
|
||||
#### 11.4 GlusterFS 架构与使用
|
||||
|
||||
- **GlusterFS 简介**:介绍 GlusterFS 的架构、特点和应用场景。
|
||||
- **安装与配置**:
|
||||
- **环境准备**:系统要求和依赖安装。
|
||||
- **安装 GlusterFS**:在各节点上安装 GlusterFS 软件包。
|
||||
- **配置卷**:创建和配置分布式卷、复制卷等。
|
||||
- **使用与管理**:
|
||||
- **挂载和访问**:客户端挂载 GlusterFS 卷,读写数据。
|
||||
- **管理操作**:卷扩展、缩减、迁移等操作。
|
||||
|
||||
#### 11.5 分布式存储系统的负载均衡
|
||||
|
||||
- **负载均衡的概念**:介绍负载均衡在分布式存储系统中的作用。
|
||||
- **实现策略**:
|
||||
- **数据分片**:将数据分散存储在不同节点上,实现负载均衡。
|
||||
- **读写分离**:将读写操作分离,分别处理,减少单节点负担。
|
||||
- **动态调整**:根据节点负载情况,动态调整数据分布和请求路由。
|
||||
- **工具与实践**:
|
||||
- **常用负载均衡工具**:如 HAProxy、LVS 等。
|
||||
- **实际案例分析**:分析具体分布式存储系统中的负载均衡实现。
|
||||
|
||||
#### 11.6 数据复制与同步策略
|
||||
|
||||
- **数据复制的必要性**:确保数据的高可用性和可靠性。
|
||||
- **复制策略**:
|
||||
- **同步复制**:实时同步数据,保证数据一致性。
|
||||
- **异步复制**:延迟同步,减少实时同步带来的性能开销。
|
||||
- **多副本机制**:设置多个数据副本,提高数据冗余度。
|
||||
- **同步工具与技术**:
|
||||
- **常用同步工具**:如 rsync、DRBD 等。
|
||||
- **实际应用**:在具体分布式存储系统中的数据同步实现。
|
||||
|
||||
#### 11.7 分布式存储系统的监控与维护
|
||||
|
||||
- **监控的必要性**:实时了解系统运行状态,预防和快速响应故障。
|
||||
- **监控工具**:
|
||||
- **常用监控工具**:如 Prometheus、Grafana、Zabbix 等。
|
||||
- **日志管理工具**:如 ELK(Elasticsearch、Logstash、Kibana)栈。
|
||||
- **维护实践**:
|
||||
- **常见问题排查**:识别和解决存储系统中的常见问题。
|
||||
- **系统升级和扩展**:无缝升级系统和增加存储节点。
|
||||
- **备份与恢复**:定期进行数据备份,制定灾难恢复计划。
|
||||
|
||||
### 12. 分布式文件系统与对象存储
|
||||
|
||||
#### 12.1 分布式文件系统原理与实现
|
||||
|
||||
- **基本概念**:
|
||||
- 分布式文件系统的定义和作用。
|
||||
- 常见的分布式文件系统(如 HDFS、Ceph、GlusterFS 等)。
|
||||
- **体系结构**:
|
||||
- 分布式文件系统的整体架构和组成部分(如客户端、元数据服务器、数据节点)。
|
||||
- 数据存储和访问机制。
|
||||
- **实现原理**:
|
||||
- 文件切分和分块存储。
|
||||
- 数据冗余和副本机制。
|
||||
- 负载均衡和数据分布策略。
|
||||
- **关键技术**:
|
||||
- 数据分片和分布算法。
|
||||
- 元数据管理和一致性模型。
|
||||
- 容错和恢复机制。
|
||||
|
||||
#### 12.2 对象存储与块存储的区别与应用场景
|
||||
|
||||
- **基本概念**:
|
||||
- 对象存储、块存储和文件存储的定义。
|
||||
- 三者的主要区别和各自的优缺点。
|
||||
- **对象存储**:
|
||||
- 对象存储的架构和实现方式。
|
||||
- 对象存储的特点(如可扩展性、元数据自描述、扁平化存储结构)。
|
||||
- 常见的对象存储系统(如 Amazon S3、OpenStack Swift、MinIO 等)。
|
||||
- 典型应用场景(如大数据分析、备份和归档、内容分发网络)。
|
||||
- **块存储**:
|
||||
- 块存储的架构和实现方式。
|
||||
- 块存储的特点(如高性能、低延迟、适合结构化数据存储)。
|
||||
- 常见的块存储系统(如 iSCSI、Fibre Channel、NVMe-oF)。
|
||||
- 典型应用场景(如数据库、虚拟机存储、事务处理)。
|
||||
|
||||
#### 12.3 高可用与数据一致性策略
|
||||
|
||||
- **高可用性**:
|
||||
- 高可用性的定义和重要性。
|
||||
- 实现高可用的技术(如副本机制、自动故障转移、负载均衡)。
|
||||
- 分布式文件系统和对象存储的高可用设计。
|
||||
- **数据一致性**:
|
||||
- 数据一致性的基本概念和类型(如强一致性、最终一致性、因果一致性)。
|
||||
- 一致性协议和算法(如 Paxos、Raft)。
|
||||
- CAP 定理及其影响。
|
||||
- 数据一致性在分布式文件系统和对象存储中的实现策略。
|
||||
|
||||
#### 12.4 分布式文件系统的元数据管理
|
||||
|
||||
- **元数据管理的作用**:
|
||||
- 元数据的定义和重要性。
|
||||
- 元数据在分布式文件系统中的角色。
|
||||
- **元数据架构**:
|
||||
- 集中式元数据管理和分布式元数据管理的对比。
|
||||
- 常见的元数据管理方式(如主从复制、一致性哈希)。
|
||||
- **元数据操作**:
|
||||
- 元数据创建、更新和删除的操作流程。
|
||||
- 元数据的高效查询和检索机制。
|
||||
- **元数据一致性**:
|
||||
- 元数据一致性的挑战和解决方案。
|
||||
- 元数据的一致性模型和实现策略。
|
||||
|
||||
#### 12.5 对象存储的生命周期管理
|
||||
|
||||
- **生命周期管理的概念**:
|
||||
- 对象存储生命周期的定义和重要性。
|
||||
- 生命周期管理的基本操作(如创建、修改、归档、删除)。
|
||||
- **生命周期策略**:
|
||||
- 自动化生命周期管理策略的制定和应用。
|
||||
- 生命周期管理规则的配置和优化。
|
||||
- **版本控制**:
|
||||
- 对象存储的版本控制机制。
|
||||
- 版本管理和恢复操作。
|
||||
- **数据迁移和归档**:
|
||||
- 数据迁移策略和工具。
|
||||
- 数据归档和删除策略。
|
||||
- 数据治理和合规性管理。
|
||||
|
||||
#### 12.6 分布式文件系统和对象存储的实际应用案例分析
|
||||
|
||||
- **案例选择**:
|
||||
- 选择具有代表性的分布式文件系统和对象存储案例。
|
||||
- 分析案例的背景和需求。
|
||||
- **系统架构**:
|
||||
- 详细描述系统的架构设计。
|
||||
- 分析系统的组件和功能模块。
|
||||
- **实现过程**:
|
||||
- 描述系统的实现过程和技术选型。
|
||||
- 分析系统在实施过程中遇到的问题和解决方案。
|
||||
- **性能和优化**:
|
||||
- 系统的性能评估和优化策略。
|
||||
- 系统的可扩展性和维护性分析。
|
||||
- **总结和反思**:
|
||||
- 总结案例的成功经验和不足之处。
|
||||
- 提出改进建议和未来发展方向。
|
||||
775
Tech/computer-storage/4. 文件系统.md
Normal file
775
Tech/computer-storage/4. 文件系统.md
Normal file
@ -0,0 +1,775 @@
|
||||
---
|
||||
title: 4. 文件系统
|
||||
description: 描述
|
||||
keywords:
|
||||
- 关键字
|
||||
tags:
|
||||
- 标签
|
||||
author: 仲平
|
||||
date: 2024-07-29
|
||||
---
|
||||
|
||||
## 文件系统
|
||||
|
||||
### Linux 文件系统
|
||||
|
||||
Linux 文件系统始于 1987 年,当时 Linus Torvalds 在创建 Linux 内核时,选择了 Minix 文件系统。Minix 文件系统由 Andrew S. Tanenbaum 为 Minix 操作系统设计,具有简单且可靠的特点。然而,由于其最大文件和文件系统大小仅为 64MB,以及文件名长度限制为 14 字符,无法满足更复杂的需求。
|
||||
|
||||
1992 年,Rémy Card 开发了第一个专为 Linux 设计的文件系统 **Extended File System (EXT)**,以解决 Minix 文件系统的限制问题。EXT 的最大文件和文件系统大小分别为 2GB,文件名长度扩展到 255 字符。然而,EXT 仍然缺乏日志功能和对更大规模的支持。
|
||||
|
||||
1993 年,Rémy Card 发布了 EXT2 文件系统,这成为 Linux 内核 2.0 版的默认文件系统。EXT2 支持的最大文件大小为 2TB,最大文件系统大小为 4TB,尽管没有日志功能,但它提供了更大的文件和文件系统支持,并改进了性能。
|
||||
|
||||
1994 年,Silicon Graphics(SGI)开发了 **XFS 文件系统**,最初用于其 IRIX 操作系统。XFS 以其高性能和可扩展性在科学计算和数据密集型应用中广泛使用,支持的最大文件和文件系统大小分别为 18EB,具有高效的日志记录机制。
|
||||
|
||||
2001 年,Stephen Tweedie 发布了 EXT3 文件系统,这是 EXT2 的升级版本,增加了日志功能以提高数据可靠性和系统恢复速度。EXT3 保持了 EXT2 的文件和文件系统大小限制,并且向后兼容 EXT2。同年,Hans Reiser 开发了 ReiserFS,这是第一个默认支持日志功能的文件系统,支持的最大文件和文件系统大小分别为 8TB 和 16TB。ReiserFS 以高效的小文件存储和快速目录查找而闻名,但后续发展受限,逐渐被其他文件系统取代。
|
||||
|
||||
2004 年,Sun Microsystems 开发并发布了 **ZFS 文件系统**,最初用于 Solaris 操作系统,现在已移植到多个平台。ZFS 提供了极高的数据完整性和灵活性,支持的最大文件和文件系统大小为 256 兆亿亿字节,并集成了文件系统和逻辑卷管理、数据完整性校验、快照和复制、自动修复等新特性,适用于企业存储解决方案和云存储环境。
|
||||
|
||||
2007 年,Oracle 公司开发的 **Btrfs 文件系统**首次发布,旨在提供高级管理功能和高可靠性。Btrfs 支持的最大文件和文件系统大小均为 16EB,具有快照、内联数据压缩、子卷管理和在线文件系统检查等新特性,适用于需要高级存储管理和数据保护的场景。
|
||||
|
||||
2008 年,由 Theodore Ts'o 领导开发的 EXT4 文件系统发布,成为 EXT3 的继任者。EXT4 显著改进了性能和可靠性,支持的最大文件大小达到 1EB,最大文件系统大小为 16TB,并引入了延迟分配、多块分配、无日志模式和在线碎片整理等新特性。
|
||||
|
||||
Linux 文件系统从 Minix 到 EXT,再到更高级的 EXT4、Btrfs、XFS 和 ZFS 的发展过程中,每一次升级都带来了更大的存储支持、更高的性能和可靠性,以及更多的管理功能。
|
||||
|
||||
#### EXT4
|
||||
|
||||
EXT4(Fourth Extended File System)于 2008 年发布,由 Theodore Ts'o 领导开发,作为 EXT3 的继任者。EXT4 的发展旨在解决 EXT3 在大规模存储和性能上的限制,并引入了许多新特性和性能改进。EXT4 成为现代 Linux 系统的主流文件系统,广泛应用于各种场景,从个人电脑到企业级服务器。它的设计兼顾了向后兼容和未来扩展的需求,使其在稳定性和性能上都有显著提升。
|
||||
|
||||
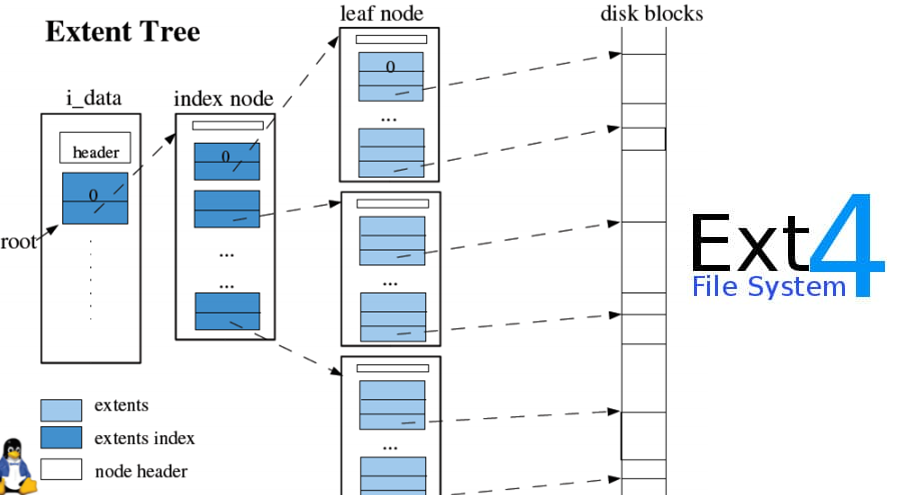
|
||||
|
||||
**特点**
|
||||
|
||||
- **最大文件大小**:1EB(Exabyte)
|
||||
- **最大文件系统大小**:16TB(Terabyte)
|
||||
- **文件碎片整理**:引入了延迟分配(Delayed Allocation)技术,这一特性通过推迟分配数据块的位置来减少文件碎片,提高了文件系统性能。
|
||||
- **多块分配**:多块分配(Multiblock Allocation)允许一次性分配多个块,减少文件碎片,提高写入效率。
|
||||
- **日志模式**:支持多种日志模式(Journal Mode),包括数据模式、元数据模式和延迟模式,以平衡性能和数据安全。
|
||||
- **文件系统检查**:引入了快速文件系统检查功能(Fast Fsck),通过存储已校验的文件系统部分,减少了文件系统检查时间。
|
||||
- **无日志模式**:支持无日志模式(No Journaling Mode),适用于对性能要求极高而对数据安全要求不高的场景。
|
||||
- **在线碎片整理**:支持在线碎片整理功能,允许在不卸载文件系统的情况下进行碎片整理,提高了系统的可用性。
|
||||
|
||||
#### Btrfs
|
||||
|
||||
Btrfs(B-Tree 文件系统)由 Oracle 公司于 2007 年首次发布,旨在提供高级管理功能和高可靠性。Btrfs 的设计目标是应对大规模存储系统的需求,并提供丰富的数据管理功能。Btrfs 在开发初期得到了广泛关注,被认为是未来 Linux 文件系统的发展方向之一。它的许多特性,如快照、压缩和自我修复,使其在数据密集型和高可靠性要求的应用场景中具有显著优势。
|
||||
|
||||
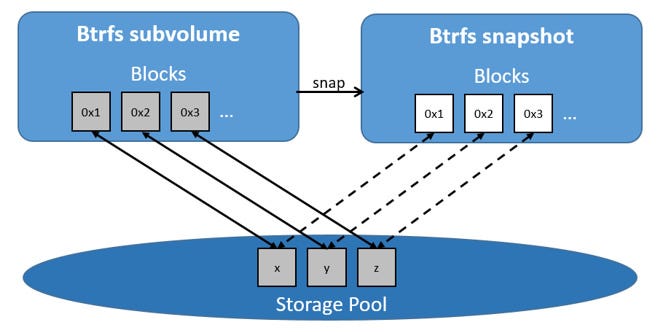
|
||||
|
||||
**特点**
|
||||
|
||||
- **最大文件大小**:16EB(Exabyte)
|
||||
- **最大文件系统大小**:16EB
|
||||
- **快照**:支持快照(Snapshot)功能,可以快速创建文件系统的时间点副本,用于数据备份和恢复。
|
||||
- **内联数据压缩**:支持内联数据压缩(Inline Compression),有效减少存储空间需求。
|
||||
- **子卷管理**:支持子卷(Subvolume)管理,允许在同一文件系统中创建多个逻辑卷,提供更灵活的存储管理。
|
||||
- **在线文件系统检查**:支持在线文件系统检查和修复(Online Scrubbing and Repair),可以在系统运行时检测和修复数据损坏。
|
||||
- **自我修复**:内置数据校验和自我修复功能,自动检测并修复数据损坏,确保数据完整性。
|
||||
- **可扩展性**:高可扩展性,支持大规模存储需求,并允许在不中断服务的情况下进行文件系统扩展和缩减。
|
||||
|
||||
#### XFS
|
||||
|
||||
XFS 文件系统由 Silicon Graphics(SGI)于 1994 年开发,最初用于其高性能计算和图形工作站的 IRIX 操作系统。XFS 以其高性能和可扩展性著称,特别适合处理大文件和高并发 I/O 操作。随着时间的推移,XFS 被移植到 Linux 平台,并在数据密集型应用和科学计算领域得到了广泛应用。
|
||||
|
||||
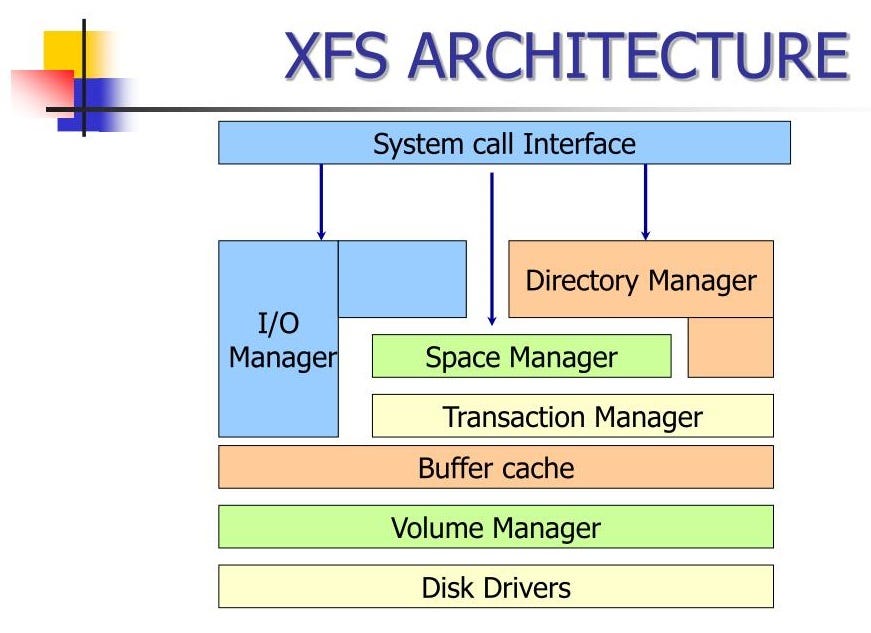
|
||||
|
||||
**特点**
|
||||
|
||||
- **最大文件大小**:18EB(Exabyte)
|
||||
- **最大文件系统大小**:18EB
|
||||
- **日志记录机制**:高效的日志记录机制(Efficient Logging),减少了系统崩溃后的恢复时间,提高了数据可靠性。
|
||||
- **直接 I/O**:支持直接 I/O(Direct I/O),允许应用程序直接访问磁盘,绕过文件系统缓存,提高了 I/O 性能。
|
||||
- **可扩展性**:极高的可扩展性,能够处理极大规模的存储需求,适用于高性能计算和数据中心。
|
||||
- **动态扩展**:支持文件系统的动态扩展(Dynamic Allocation),在不卸载文件系统的情况下进行扩展。
|
||||
- **并发支持**:优秀的并发支持,适用于高并发的 I/O 操作场景,如数据库和大规模数据处理。
|
||||
|
||||
#### ZFS
|
||||
|
||||
ZFS(Zettabyte File System)由 Sun Microsystems 开发,最初用于 Solaris 操作系统,现已移植到多个平台。ZFS 于 2004 年首次发布,旨在提供极高的数据完整性和灵活性。ZFS 的设计理念是将文件系统和逻辑卷管理融合在一起,简化存储管理,同时提供强大的数据保护和管理功能。其创新的设计和丰富的特性使其在企业存储解决方案和云存储环境中得到了广泛应用。
|
||||
|
||||
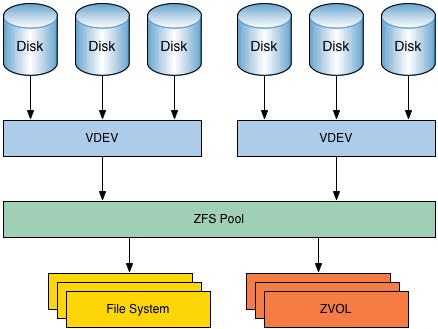
|
||||
|
||||
**特点**
|
||||
|
||||
- **最大文件大小**:256 兆亿亿字节
|
||||
- **最大文件系统大小**:256 兆亿亿字节
|
||||
- **集成文件系统和逻辑卷管理**:ZFS 将文件系统和逻辑卷管理融合在一起,提供统一的存储管理界面,简化了管理操作。
|
||||
- **数据完整性校验**:内置数据校验(Data Integrity Verification)和自我修复功能,确保数据在传输和存储过程中的完整性。
|
||||
- **快照和克隆**:支持快照(Snapshot)和克隆(Clone)功能,可以快速创建数据副本,用于备份和测试。
|
||||
- **自动修复**:当检测到数据损坏时,ZFS 能自动从冗余数据中恢复,确保数据的高可靠性。
|
||||
- **高级存储管理**:支持数据压缩、去重(Deduplication)和动态磁盘池(Dynamic Storage Pooling),提高存储效率和灵活性。
|
||||
- **可扩展性**:高可扩展性,支持大规模存储环境,适用于企业级和云计算场景。
|
||||
|
||||
#### 对比表
|
||||
|
||||
| 文件系统 | 最大文件大小 | 最大文件系统大小 | 日志功能 | 快照 | 压缩 | 数据校验 | 自我修复 | 应用场景 |
|
||||
| -------- | ------------- | ---------------- | -------- | ---- | ---- | -------- | -------- | ---------------------------------------------------------- |
|
||||
| EXT4 | 1EB | 16TB | 有 | 无 | 无 | 无 | 无 | 现代 Linux 系统,广泛应用于个人电脑和服务器 |
|
||||
| Btrfs | 16EB | 16EB | 有 | 有 | 有 | 有 | 有 | 高级存储管理和数据保护,适用于服务器和企业级应用 |
|
||||
| XFS | 18EB | 18EB | 有 | 无 | 无 | 无 | 无 | 高并发 I/O 和大文件处理,适用于高性能计算和数据密集型应用 |
|
||||
| ZFS | 256 兆亿亿字节 | 256 兆亿亿字节 | 有 | 有 | 有 | 有 | 有 | 企业存储解决方案和云存储环境,提供极高的数据完整性和灵活性 |
|
||||
|
||||
### Windows 文件系统
|
||||
|
||||
1980 年代中期,微软推出了最初的文件系统——**FAT 文件系统(File Allocation Table)**,用于 MS-DOS 操作系统。FAT 文件系统简单且高效,适用于当时的硬盘存储需求。它最初有 FAT12 和 FAT16 两个版本,分别用于小型和中型存储设备。FAT16 支持的最大分区大小为 2GB,文件名长度为 8.3 格式(即最多 8 个字符的文件名加上 3 个字符的扩展名)。
|
||||
|
||||
1993 年,随着 Windows NT 3.1 的发布,微软引入了**NTFS 文件系统(New Technology File System)**。NTFS 提供了许多先进的功能,如文件和文件系统的权限管理、日志记录、文件压缩和加密等。NTFS 支持的最大文件和文件系统大小大幅提升,文件名长度扩展到 255 字符。
|
||||
|
||||
1996 年,FAT32 文件系统随着 Windows 95 OSR2 的发布而推出,旨在克服 FAT16 的限制。FAT32 支持的最大分区大小为 2TB,文件名长度仍为 8.3 格式,但增加了长文件名支持,允许最多 255 个字符。FAT32 广泛用于 U 盘和小型存储设备,因其跨平台兼容性而受到欢迎。
|
||||
|
||||
2001 年,随着 Windows XP 的发布,NTFS 文件系统成为默认文件系统。NTFS 的优势包括支持大文件和大分区、更好的数据安全性和可靠性,以及改进的磁盘空间利用率。Windows XP 还继续支持 FAT32 文件系统,以保持对旧系统和设备的兼容性。
|
||||
|
||||
2006 年,Windows Vista 发布,引入了 NTFS 3.1 版本,增加了对事务性 NTFS(TxF)的支持,以提高文件操作的可靠性和一致性。虽然 TxF 在后来版本中被弃用,但它显示了 NTFS 在功能和性能上的不断改进。
|
||||
|
||||
2012 年,随着 Windows 8 的发布,微软推出了**ReFS 文件系统(Resilient File System)**,旨在提供更高的数据完整性和可扩展性。ReFS 具有自动修复、数据校验、数据损坏隔离等特性,特别适用于大规模数据存储和虚拟化环境。ReFS 支持的最大文件大小和文件系统大小为 1YB(1 百万 TB)。
|
||||
|
||||
2017 年,随着 Windows 10 的更新,**微软引入了对 Linux 文件系统(如 Ext4 和 Btrfs)的支持**,通过 Windows Subsystem for Linux(WSL),使用户能够在 Windows 上使用 Linux 文件系统和工具。这标志着 Windows 文件系统生态的进一步扩展和兼容性提升。
|
||||
|
||||
Windows 文件系统的发展历程从早期的 FAT 和 FAT16,逐步发展到功能强大的 NTFS,再到专为大规模数据存储设计的 ReFS,每一次升级都带来了更高的性能、可靠性和功能。现代 Windows 操作系统还通过 WSL 支持 Linux 文件系统,展示了其在兼容性和多样性上的持续改进。
|
||||
|
||||
#### NTFS
|
||||
|
||||
NTFS(New Technology File System)由 Microsoft 于 1993 年随 Windows NT 3.1 发布,作为 FAT 文件系统的继任者。NTFS 设计初衷是提供更高的安全性、可靠性和可扩展性,适应企业级应用的需求。它的发展伴随着 Windows NT 系列操作系统的进化,从最初的 NT 3.1 到后来的 Windows 2000、XP、Vista、7、8 和 10。NTFS 的引入标志着文件系统安全性和性能的显著提升,使其成为 Windows 系统的标准文件系统。
|
||||
|
||||
**特点**
|
||||
|
||||
- **文件和卷加密**:支持 EFS(Encrypting File System)加密技术,提供文件和文件夹级别的加密保护。
|
||||
- **磁盘配额**:允许管理员设置磁盘配额,限制用户或组的磁盘使用量。
|
||||
- **压缩**:支持文件和文件夹的压缩功能,节省存储空间。
|
||||
- **日志功能**:具有日志功能,记录文件系统元数据的变更,确保数据完整性和快速恢复。
|
||||
- **单个文件和卷大小**:支持高达 256TB 的单个文件和卷大小,满足大规模存储需求。
|
||||
- **权限管理**:提供细粒度的文件和文件夹权限设置,增强了数据安全性。
|
||||
- **索引服务**:支持文件内容索引,加快文件搜索速度。
|
||||
|
||||
#### FAT32
|
||||
|
||||
FAT32(File Allocation Table 32)是 FAT 文件系统的改进版,于 1996 年随 Windows 95 OSR2 发布。FAT32 旨在解决 FAT16 的容量限制问题,提供更大的卷和文件支持。由于其良好的兼容性,FAT32 在便携设备和多平台数据交换中得到广泛应用。
|
||||
|
||||
**特点**
|
||||
|
||||
- **兼容性**:FAT32 可以在多种操作系统(如 Windows、MacOS、Linux)之间无缝使用,广泛用于便携式存储设备。
|
||||
- **卷和文件大小**:支持最高 4GB 的单个文件和 2TB 的卷大小。
|
||||
- **效率**:较小的簇大小提高了磁盘空间的利用率。
|
||||
- **简单性**:文件系统结构简单,易于实现和维护。
|
||||
- **局限性**:不支持文件加密、磁盘配额和文件压缩等高级功能。
|
||||
|
||||
#### exFAT
|
||||
|
||||
exFAT(Extended File Allocation Table)于 2006 年由 Microsoft 发布,旨在替代 FAT32,专为闪存存储设备(如 SD 卡和 USB 闪存驱动器)优化。exFAT 解决了 FAT32 在文件大小和卷大小上的限制,同时保持了跨平台兼容性。
|
||||
|
||||
**特点**
|
||||
|
||||
- **文件和卷大小**:支持高达 128PB 的卷大小和无实际限制的文件大小,适用于大容量存储需求。
|
||||
- **优化性能**:针对闪存存储器优化,提供更高的读写性能。
|
||||
- **跨平台兼容性**:广泛支持多种操作系统,适合便携式存储设备。
|
||||
- **簇大小**:支持更大的簇大小,适合处理大文件。
|
||||
- **简单性**:比 NTFS 结构简单,适合嵌入式系统和便携设备。
|
||||
|
||||
#### ReFS
|
||||
|
||||
ReFS(Resilient File System)于 2012 年由 Microsoft 发布,作为 NTFS 的继任者,主要用于 Windows Server 环境。ReFS 设计初衷是提高数据可用性和弹性,特别适用于大规模数据存储和虚拟化环境。
|
||||
|
||||
**特点**
|
||||
|
||||
- **数据完整性**:采用校验和算法,检测和修复数据损坏,提高数据可靠性。
|
||||
- **自动修复**:支持自动修复功能,通过冗余数据副本自动修复损坏的数据。
|
||||
- **弹性**:设计用于处理极大规模的数据卷和文件,支持高达数百 PB 的存储容量。
|
||||
- **性能优化**:针对虚拟化和大规模存储场景进行了优化,提高了性能和效率。
|
||||
- **兼容性**:虽然 ReFS 不完全兼容所有 NTFS 功能,但它与 Windows Server 和存储空间(Storage Spaces)高度集成。
|
||||
|
||||
#### 对比表
|
||||
|
||||
| 文件系统 | 最大文件大小 | 最大卷大小 | 日志功能 | 文件和卷加密 | 磁盘配额 | 压缩 | 跨平台兼容性 | 应用场景 |
|
||||
| -------- | ------------ | ---------- | -------- | ------------ | -------- | ---- | ------------ | ------------------------------------------ |
|
||||
| NTFS | 256TB | 256TB | 有 | 有 | 有 | 有 | 部分兼容 | Windows 桌面和服务器,企业级应用 |
|
||||
| FAT32 | 4GB | 2TB | 无 | 无 | 无 | 无 | 广泛兼容 | 便携式存储设备,多平台数据交换 |
|
||||
| exFAT | 无实际限制 | 128PB | 无 | 无 | 无 | 无 | 广泛兼容 | 闪存存储设备,便携式大容量存储 |
|
||||
| ReFS | 35PB | 35PB | 有 | 无 | 有 | 无 | 部分兼容 | 大规模数据存储,虚拟化环境,Windows Server |
|
||||
|
||||
### MacOS 主流文件系统
|
||||
|
||||
1984 年,Apple 推出了用于 Macintosh 计算机的初代文件系统——**MFS(Macintosh File System)**。MFS 是一个简单的文件系统,支持单级目录结构和 128KB 的块大小。虽然对于早期的 Macintosh 计算机来说足够,但随着存储需求的增加,MFS 的局限性逐渐显现。
|
||||
|
||||
1985 年,Apple 发布了**HFS(Hierarchical File System)**以替代 MFS。HFS 引入了分层目录结构,支持更大容量的硬盘和文件系统,最大支持 2GB 的卷和 2GB 的文件大小。HFS 采用 512 字节的块大小,并增加了多级目录支持,极大地改善了文件管理。
|
||||
|
||||
1998 年,随着 Mac OS 8.1 的发布,Apple 推出了**HFS+(也称为 Mac OS Extended)**,这是对 HFS 的重大改进。HFS+ 引入了更小的块大小(4KB),大幅提高了磁盘空间利用率,支持的最大卷和文件大小分别扩展到 8EB(exabytes)。HFS+ 还引入了 Unicode 支持,使文件名能够包含更多的字符。
|
||||
|
||||
2002 年,Mac OS X 10.2 Jaguar 发布,HFS+ 成为默认文件系统。随着系统的不断更新,HFS+ 增加了许多新功能,包括文件压缩、稀疏文件支持和更高效的文件存储。
|
||||
|
||||
2014 年,Apple 在 OS X Yosemite 中引入了 Core Storage,这是一个逻辑卷管理器,允许用户创建加密卷和使用 Fusion Drive 技术,将 SSD 和 HDD 组合成一个卷以提高性能和存储效率。
|
||||
|
||||
2016 年,Apple 发布了 macOS Sierra,并引入了**APFS(Apple File System)**。APFS 是对 HFS+ 的彻底重构,设计目标是提高性能、安全性和可靠性。APFS 支持 64 位文件 ID,最大支持的文件和卷大小为 8EB,具有更快的目录操作、更高效的空间管理和更强的数据完整性保障。APFS 还支持快照、克隆、加密和原子操作,极大地提升了文件系统的功能性和用户体验。
|
||||
|
||||
2017 年,macOS High Sierra 发布,APFS 成为默认文件系统。APFS 特别针对 SSD 优化,但也兼容 HDD 和外部存储设备。APFS 的推出标志着 macOS 文件系统迈向现代化和高效管理的新阶段。
|
||||
|
||||
macOS 文件系统从最初的 MFS 到 HFS,再到 HFS+ 和现代的 APFS,每一次升级都带来了显著的改进和新功能。随着存储需求和技术的发展,Apple 不断提升文件系统的性能、可靠性和功能,确保 macOS 能够满足现代用户的需求。
|
||||
|
||||
#### HFS+
|
||||
|
||||
HFS+(Hierarchical File System Plus),也称为 Mac OS Extended,是 Apple 于 1998 年推出的文件系统,用于替代早期的 HFS 文件系统。HFS+ 是为适应更大的存储需求和提高文件管理效率而设计的。它首次随 Mac OS 8.1 引入,并在之后的多个 Mac OS 版本中成为标准文件系统。HFS+ 通过增加文件大小和卷大小的支持,改进文件命名和目录结构,满足了当时不断增长的存储需求。
|
||||
|
||||
**特点**
|
||||
|
||||
- **最大文件大小**:8EB(Exabyte)
|
||||
- **最大卷大小**:8EB
|
||||
- **硬链接和软链接**:支持硬链接和软链接,提供更灵活的文件管理方式。
|
||||
- **文件压缩**:支持文件压缩,减少存储空间的占用。
|
||||
- **分层目录结构**:改进的分层目录结构,支持更大的文件和目录。
|
||||
- **Unicode 支持**:改进的文件名编码,支持 Unicode 字符集,增强了跨平台兼容性。
|
||||
- **数据完整性**:支持日志功能,记录文件系统的元数据更改,提高数据完整性和恢复速度。
|
||||
|
||||
#### APFS
|
||||
|
||||
**文化和发展历史**
|
||||
|
||||
APFS(Apple File System)是 Apple 于 2017 年发布的新一代文件系统,设计初衷是替代 HFS+,以满足现代存储需求。APFS 针对 SSD 和闪存存储器进行了优化,显著提升了性能和数据安全性。APFS 随着 macOS High Sierra 的发布而引入,并逐渐成为 macOS、iOS、watchOS 和 tvOS 的标准文件系统。其设计注重高性能、高安全性和高效的存储管理,适应了当前和未来的数据存储需求。
|
||||
|
||||
**特点**
|
||||
|
||||
- **最大文件大小**:8EB(Exabyte)
|
||||
- **最大卷大小**:8EB
|
||||
- **快照**:支持快照功能,可以在不同时间点创建文件系统的副本,方便数据恢复和备份。
|
||||
- **克隆**:支持克隆功能,在不占用额外存储空间的情况下创建文件或目录的副本。
|
||||
- **加密**:内置强大的加密功能,支持单文件和整个卷的加密,增强了数据安全性。
|
||||
- **空间共享**:支持空间共享(Space Sharing),多个卷可以共享同一存储池,有效利用存储空间。
|
||||
- **文件和目录压缩**:支持高效的文件和目录压缩,节省存储空间。
|
||||
- **高效存储**:优化的元数据管理和文件系统布局,提供更高的存储效率和性能。
|
||||
- **崩溃保护**:具备崩溃保护机制,通过快速重启和数据恢复,确保数据的高可用性。
|
||||
|
||||
#### 对比表
|
||||
|
||||
| 文件系统 | 发布年份 | 最大文件大小 | 最大卷大小 | 日志功能 | 硬链接 | 软链接 | 文件压缩 | 快照 | 克隆 | 加密 | 空间共享 | 应用场景 |
|
||||
| -------- | -------- | ------------ | ---------- | -------- | ------ | ------ | -------- | ---- | ---- | ---- | -------- | ------------------------------------------------------------ |
|
||||
| HFS+ | 1998 年 | 8EB | 8EB | 有 | 有 | 有 | 有 | 无 | 无 | 无 | 无 | 早期 Mac OS 系统,个人计算和多媒体处理 |
|
||||
| APFS | 2017 年 | 8EB | 8EB | 有 | 无 | 有 | 有 | 有 | 有 | 有 | 有 | 现代 macOS、iOS、watchOS 和 tvOS 设备,提供高性能和数据安全性 |
|
||||
|
||||
## 文件系统结构与管理
|
||||
|
||||
### 文件系统结构
|
||||
|
||||
#### 层次
|
||||
|
||||
文件系统层次结构指的是文件和目录的组织方式。大多数现代文件系统采用层次结构,即目录和子目录构成树状结构。根目录(Root Directory)是树的起点,其他所有文件和目录都可以从根目录访问。
|
||||
|
||||
- **根目录**:文件系统的顶层目录,通常表示为 `/`(在 Unix 和 Linux 系统中)或 `C:\`(在 Windows 系统中)。
|
||||
- **目录和子目录**:目录是包含其他文件和目录的容器。子目录是父目录的一部分,形成树状层次结构。
|
||||
- **文件**:存储数据的基本单位,可以是文本文档、图像、可执行程序等。
|
||||
|
||||
#### 结构图
|
||||
|
||||
|
||||
|
||||
```mermaid
|
||||
graph TD
|
||||
Superblock
|
||||
Inode1
|
||||
DataBlock1
|
||||
DataBlock2
|
||||
DataBlock3
|
||||
IndirectBlock1
|
||||
|
||||
Superblock -->|Contains| FS_Size[File System Size]
|
||||
Superblock -->|Contains| Block_Size[Block Size]
|
||||
Superblock -->|Contains| Free_Block_Count[Free Block Count]
|
||||
Superblock -->|Contains| Free_Inode_Count[Free Inode Count]
|
||||
Superblock -->|Contains| FS_State[File System State]
|
||||
Superblock -->|Contains| FS_ID[File System ID]
|
||||
Superblock -->|Contains| Root_Inode[Root Inode]
|
||||
|
||||
Inode1 -->|Points to| DirectBlock1[Direct Block 1]
|
||||
Inode1 -->|Points to| DirectBlock2[Direct Block 2]
|
||||
Inode1 -->|Points to| IndirectBlock1
|
||||
IndirectBlock1 -->|Points to| DataBlock1
|
||||
IndirectBlock1 -->|Points to| DataBlock2
|
||||
IndirectBlock1 -->|Points to| DataBlock3
|
||||
```
|
||||
|
||||
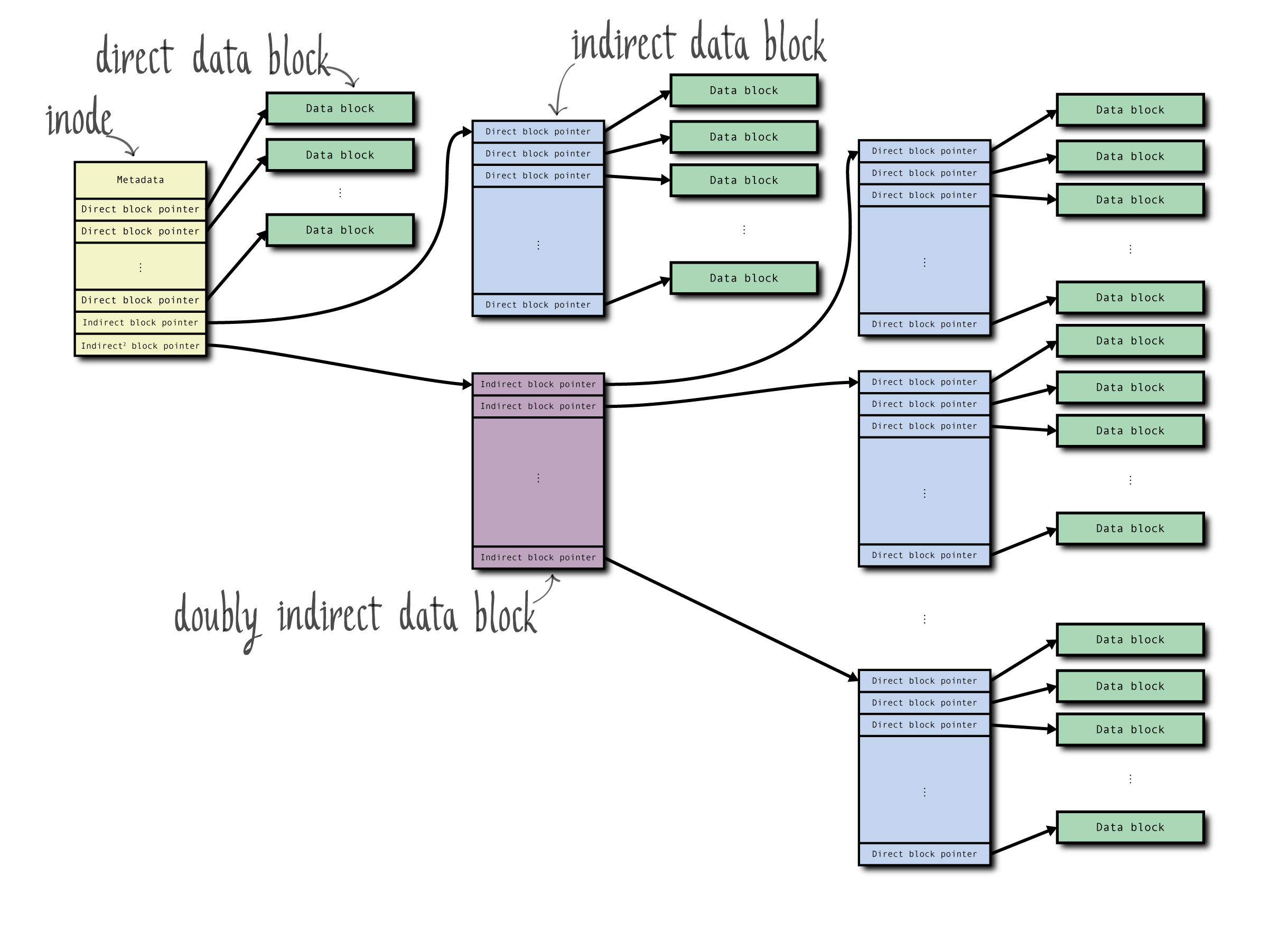
- **超级块(Superblock)**:包含文件系统的元数据,例如文件系统大小、块大小、空闲块数量、空闲 Inode 数量、文件系统状态、文件系统 ID、根 Inode 等。
|
||||
- **索引节点(Inode)**:包含文件的元数据,并指向文件的数据块。
|
||||
- **直接指针(Direct Pointers)**:直接指向数据块。
|
||||
- **一次间接指针(Indirect Pointers)**:指向一个包含数据块指针的块,每个指针指向一个数据块。
|
||||
- **数据块(Data Block)**:实际存储文件数据的基本单元。
|
||||
|
||||
#### 超级块(Superblock)
|
||||
|
||||
超级块是文件系统的核心元数据结构,存储文件系统的整体信息。每个文件系统都有一个超级块,用于描述文件系统的特性和状态。
|
||||
|
||||
> 超级块就像是图书馆的管理员记录的总册,它包含了图书馆的总体信息,比如图书馆有多大,每个书架的大小,图书馆的状态(是否开放,有没有损坏等),以及图书馆的标识符和根目录的位置。
|
||||
|
||||
| 项目 | 描述 |
|
||||
| -------------------- | ------------------------------------------------------------ |
|
||||
| 文件系统大小 | 文件系统的总大小,包括所有的数据块。 |
|
||||
| 块大小 | 文件系统中每个数据块的大小,通常为 1KB、2KB、4KB 或 8KB。 |
|
||||
| 空闲块数量 | 当前可用的数据块数量,表示文件系统中剩余的可用空间。 |
|
||||
| 空闲 Inode 数量 | 当前可用的索引节点数量,表示文件系统中可用的文件/目录数。 |
|
||||
| 文件系统挂载状态 | 文件系统是否已挂载,以及以何种模式挂载(只读或读写)。 |
|
||||
| 文件系统标识符 | 唯一标识文件系统的 ID,用于区分不同的文件系统实例。 |
|
||||
| 文件系统版本 | 文件系统的版本号,表示文件系统的格式版本。 |
|
||||
| 根目录 Inode | 指向根目录的索引节点号,根目录是文件系统的入口。 |
|
||||
| 块组描述符位置 | 存储块组描述符(Block Group Descriptor)的位置,用于描述块组的结构。 |
|
||||
| 超级块备份位置 | 存储超级块备份的位置,通常在文件系统的多个位置保存超级块备份。 |
|
||||
| 文件系统状态 | 文件系统当前的状态,如是否干净卸载、是否需要检查等。 |
|
||||
| 文件系统创建时间 | 文件系统创建的时间戳。 |
|
||||
| 文件系统修改时间 | 最后一次修改文件系统元数据的时间戳。 |
|
||||
| 上次挂载时间 | 文件系统上次被挂载的时间戳。 |
|
||||
| 上次卸载时间 | 文件系统上次被卸载的时间戳。 |
|
||||
| 最大挂载次数 | 在需要进行文件系统检查之前,文件系统可以挂载的最大次数。 |
|
||||
| 文件系统检查间隔时间 | 在需要进行文件系统检查之前,文件系统可以运行的最长时间间隔。 |
|
||||
| 文件系统标志 | 指示文件系统特性的标志,如只读、已被卸载等。 |
|
||||
| 文件系统日志位置 | 存储文件系统日志的起始位置,用于恢复文件系统的一致性。 |
|
||||
| 默认权限掩码 | 创建文件时使用的默认权限掩码。 |
|
||||
| 文件系统特性 | 文件系统支持的特性标志,如是否支持大文件、是否启用日志等。 |
|
||||
|
||||
超级块是文件系统管理的核心,一旦损坏,整个文件系统将无法使用。超级块的损坏可能导致文件系统无法挂载或文件数据丢失。因此,文件系统通常会在多个位置保存超级块的副本,以提高容错性。
|
||||
|
||||
- **主超级块**:文件系统中的主要超级块,通常位于文件系统的第一个块。
|
||||
- **备份超级块**:为了防止单点故障,文件系统会在多个位置保存超级块的副本。不同文件系统的备份策略不同,例如,EXT2/3/4 文件系统在每组块(Block Group)中保存备份超级块。
|
||||
|
||||
#### 索引节点(Inode)
|
||||
|
||||
Inode 是文件系统中的核心数据结构,用于存储文件元数据。每个文件和目录都有一个唯一的 Inode,负责记录文件的相关信息。
|
||||
|
||||
> Inode 就像每本书的标签,它记录了每本书的详细信息,比如书名、作者、出版日期、类别以及书在书架上的位置。
|
||||
|
||||
| 项目 | 描述 |
|
||||
| ---------------- | ------------------------------------------------------------ |
|
||||
| 文件类型 | 指示文件的类型,如普通文件、目录、符号链接等。 |
|
||||
| 文件大小 | 文件的总字节数。 |
|
||||
| 文件权限 | 文件的访问权限,包括读(r)、写(w)和执行(x)权限。 |
|
||||
| 所有者信息 | 文件的所有者用户 ID(UID)和所属组 ID(GID)。 |
|
||||
| 创建时间 | 文件创建的时间戳。 |
|
||||
| 修改时间 | 文件内容最后修改的时间戳。 |
|
||||
| 访问时间 | 文件最后访问的时间戳。 |
|
||||
| 链接计数 | 指向此 Inode 的硬链接数量。 |
|
||||
| 数据块指针 | 指向存储文件内容的数据块的指针,包括直接指针、一次间接指针、二次间接指针和三次间接指针。 |
|
||||
| 文件系统标志 | 用于指示文件系统特性和状态的标志。 |
|
||||
| 文件生成号 | 文件的唯一标识符,通常用于网络文件系统(NFS)。 |
|
||||
| 文件大小(高位) | 文件大小的高位部分,用于支持大文件。 |
|
||||
| 数据块数量 | 文件使用的数据块总数。 |
|
||||
| 文件系统标识符 | 标识文件系统类型或版本的标识符。 |
|
||||
| 数据块指针数量 | 数据块指针的总数,包括直接和间接指针。 |
|
||||
| 直接指针 | 直接指向数据块的指针,通常有 12 个直接指针。 |
|
||||
| 一次间接指针 | 指向一个包含数据块指针的块,每个指针指向一个数据块。 |
|
||||
| 二次间接指针 | 指向一个包含一次间接指针块的块,每个一次间接指针指向一个包含数据块指针的块。 |
|
||||
| 三次间接指针 | 指向一个包含二次间接指针块的块,每个二次间接指针指向一个包含一次间接指针块的块。 |
|
||||
|
||||
Inode 负责管理文件的存储位置,通过数据块指针指向文件的实际数据块。Inode 不存储文件名,文件名和 Inode 的关联关系存储在目录项中。
|
||||
|
||||
1. **直接指针**:直接指向数据块的指针,通常一个 Inode 有 12 个直接指针。
|
||||
2. **一次间接指针**:指向一个包含数据块指针的块,每个指针指向一个数据块。
|
||||
3. **二次间接指针**:指向一个包含一次间接指针块的块,每个一次间接指针指向一个包含数据块指针的块。
|
||||
4. **三次间接指针**:指向一个包含二次间接指针块的块,每个二次间接指针指向一个包含一次间接指针块的块。
|
||||
|
||||
这种指针结构使得 Inode 能够高效地管理小文件和大文件,同时提供良好的性能。
|
||||
|
||||
#### 数据块(Data Block)
|
||||
|
||||
数据块是文件系统中存储文件实际内容的基本单元。文件的所有数据都存储在数据块中,由 Inode 通过指针进行管理。数据块的大小通常为 4KB,但可以根据文件系统的配置有所不同。常见的块大小有 1KB、2KB、4KB 和 8KB 等。
|
||||
|
||||
> 数据块是文件系统中存储文件实际内容的基本单元,就像图书馆的书架上的每一层存放书的地方。
|
||||
|
||||
数据块用于存储文件的实际数据内容。Inode 通过直接和间接指针指向相应的数据块,以组织和管理文件数据。
|
||||
|
||||
- **小文件存储**:对于小文件,数据可以存储在少量数据块中,甚至可能只使用一个数据块。Inode 的直接指针能够高效地管理这些数据块。
|
||||
- **大文件存储**:对于大文件,可能需要多个直接指针、间接指针和多级间接指针来管理数据块。通过这种层次化指针结构,文件系统能够有效地管理大文件,同时保持性能。
|
||||
- **数据块分配**:文件系统在创建和扩展文件时,会动态分配数据块。为了减少碎片化和提高性能,文件系统通常会尽量连续分配数据块。
|
||||
- **数据块缓存**:为了提高文件读写性能,操作系统会使用内存缓存(如页缓存)来缓存数据块的内容,减少磁盘 I/O 操作。
|
||||
|
||||
### 文件系统管理
|
||||
|
||||
#### 文件系统的创建与挂载
|
||||
|
||||
- **创建文件系统**:
|
||||
|
||||
在 Unix/Linux 系统中,可以使用 `mkfs` 命令创建文件系统。例如:
|
||||
|
||||
```sh
|
||||
# 创建一个 EXT4 文件系统。
|
||||
mkfs.ext4 /dev/sda1
|
||||
```
|
||||
|
||||
**步骤**:
|
||||
|
||||
1. 选择并准备存储设备(如磁盘分区)。
|
||||
2. 选择适当的文件系统类型。
|
||||
3. 使用 `mkfs` 命令创建文件系统。
|
||||
|
||||
- **挂载文件系统**:
|
||||
|
||||
使用 `mount` 命令将文件系统挂载到目录。例如:
|
||||
|
||||
```shell
|
||||
# 将设备 `/dev/sda1` 挂载到 `/mnt` 目录。
|
||||
mount /dev/sda1 /mnt
|
||||
```
|
||||
|
||||
**步骤**:
|
||||
|
||||
1. 创建挂载点目录(如 `/mnt`)。
|
||||
2. 使用 `mount` 命令挂载文件系统。
|
||||
3. 查看挂载状态,可以使用 `df -h` 或 `mount` 命令。
|
||||
|
||||
#### 文件系统的格式化和修复
|
||||
|
||||
- **格式化文件系统**:
|
||||
|
||||
格式化文件系统可以使用 `mkfs` 命令。例如:
|
||||
|
||||
```sh
|
||||
# 格式化设备 `/dev/sda1` 为 EXT4 文件系统
|
||||
mkfs.ext4 /dev/sda1
|
||||
```
|
||||
|
||||
**步骤:**
|
||||
|
||||
1. 确保设备未挂载。
|
||||
2. 使用 `mkfs` 命令进行格式化。
|
||||
|
||||
- **修复文件系统**:
|
||||
|
||||
在 Unix/Linux 系统中,可以使用 `fsck` 命令检查和修复文件系统。例如:
|
||||
|
||||
```sh
|
||||
# 检查并修复设备 `/dev/sda1` 上的文件系统
|
||||
fsck /dev/sda1
|
||||
```
|
||||
|
||||
**步骤**:
|
||||
|
||||
1. 确保文件系统未挂载(对于根文件系统,可以在单用户模式下进行)。
|
||||
2. 使用 `fsck` 命令检查文件系统的完整性。
|
||||
3. 根据检查结果进行修复。
|
||||
|
||||
#### 文件权限与用户管理
|
||||
|
||||
- **文件权限**:
|
||||
|
||||
文件权限分为读(r)、写(w)和执行(x)三种。权限应用于文件所有者(User)、文件所属组(Group)和其他用户(Others)。
|
||||
|
||||
| 组别 | 读(r) | 写(w) | 执行(x) |
|
||||
| ------ | ------- | ------- | --------- |
|
||||
| User | 4 | 2 | 1 |
|
||||
| Group | 4 | 2 | 1 |
|
||||
| Others | 4 | 2 | 1 |
|
||||
|
||||
使用 `chmod` 命令修改文件权限。例如:
|
||||
|
||||
```sh
|
||||
# 将文件 `filename` 的权限设置为 `rwxr-xr-x`
|
||||
chmod 755 filename
|
||||
```
|
||||
|
||||
- **用户和组管理**:
|
||||
|
||||
用户管理:使用 `useradd` 命令添加用户,`usermod` 命令修改用户,`userdel` 命令删除用户。例如:
|
||||
|
||||
```shell
|
||||
# 添加新用户 `username`
|
||||
useradd username
|
||||
```
|
||||
|
||||
组管理:使用 `groupadd` 命令添加组,`groupmod` 命令修改组,`groupdel` 命令删除组。例如:
|
||||
|
||||
```shell
|
||||
# 添加新组 `groupname`
|
||||
groupadd groupname
|
||||
```
|
||||
|
||||
## 分布式文件系统
|
||||
|
||||
分布式文件系统(Distributed File System,DFS)是一种通过网络将文件存储在多个节点上的系统。它允许文件和数据跨越多台计算机进行存储和访问,从而实现高可用性、高性能和高扩展性。以下内容将详细介绍几种常见的分布式文件系统,包括 Hadoop Distributed File System (HDFS)、Google File System (GFS)、GlusterFS 和 CephFS。
|
||||
|
||||
### Hadoop Distributed File System (HDFS)
|
||||
|
||||
#### 概述
|
||||
|
||||
[Hadoop Distributed File System](https://hadoop.apache.org/) (HDFS) 是 Apache Hadoop 项目的一部分,专为大数据处理设计。HDFS 能够处理大规模数据集,支持高吞吐量的数据访问,并具备良好的容错性。HDFS 最早由 Doug Cutting 和 Mike Cafarella 在 2005 年开发,灵感来源于 Google File System (GFS)。它主要用于存储和管理海量的数据,支持并行处理和分布式计算。
|
||||
|
||||
#### 历史发展
|
||||
|
||||
HDFS 的历史发展与 Hadoop 项目的演进密切相关。2005 年,Doug Cutting 和 Mike Cafarella 开始开发 Hadoop,最初作为 Nutch 搜索引擎项目的一部分。2006 年,Hadoop 被 Yahoo!采用,并迅速成长为大数据处理的核心技术之一。2008 年,Hadoop 成为 Apache 的顶级项目,HDFS 作为其关键组件,随着大数据生态系统的扩展和完善,逐渐发展成现今广泛应用的分布式文件系统。
|
||||
|
||||
#### 架构与组件
|
||||
|
||||
```mermaid
|
||||
graph TD;
|
||||
Client[Client] -->|Metadata Request| NN[NameNode];
|
||||
Client -->|Read/Write Data| DN1[DataNode 1];
|
||||
Client -->|Read/Write Data| DN2[DataNode 2];
|
||||
Client -->|Read/Write Data| DN3[DataNode 3];
|
||||
|
||||
subgraph Metadata
|
||||
NN[NameNode] -->|Stores| BMR1[Block Metadata 1];
|
||||
NN -->|Stores| BMR2[Block Metadata 2];
|
||||
NN -->|Stores| BMR3[Block Metadata 3];
|
||||
end
|
||||
|
||||
subgraph Storage
|
||||
DN1[DataNode 1] -->|Contains| B1[Block 1];
|
||||
DN1 -->|Contains| B2[Block 2];
|
||||
DN2[DataNode 2] -->|Contains| B3[Block 3];
|
||||
DN2 -->|Contains| B4[Block 4];
|
||||
DN3[DataNode 3] -->|Contains| B5[Block 5];
|
||||
DN3 -->|Contains| B6[Block 6];
|
||||
end
|
||||
|
||||
B1 -.->|Metadata| BMR1;
|
||||
B2 -.->|Metadata| BMR2;
|
||||
B3 -.->|Metadata| BMR3;
|
||||
B4 -.->|Metadata| BMR1;
|
||||
B5 -.->|Metadata| BMR2;
|
||||
B6 -.->|Metadata| BMR3;
|
||||
|
||||
classDef clientStyle fill:#f9f,stroke:#333,stroke-width:2px;
|
||||
classDef nnStyle fill:#9f9,stroke:#333,stroke-width:2px;
|
||||
classDef dnStyle fill:#99f,stroke:#333,stroke-width:2px;
|
||||
classDef blockStyle fill:#ff9,stroke:#333,stroke-width:2px;
|
||||
classDef metadataStyle fill:#f99,stroke:#333,stroke-width:2px;
|
||||
|
||||
class Client clientStyle;
|
||||
class NN nnStyle;
|
||||
class DN1,DN2,DN3 dnStyle;
|
||||
class B1,B2,B3,B4,B5,B6 blockStyle;
|
||||
class BMR1,BMR2,BMR3 metadataStyle;
|
||||
```
|
||||
|
||||
HDFS 采用主从架构,由 NameNode 和多个 DataNode 组成:
|
||||
|
||||
- **NameNode**:负责管理文件系统的命名空间和元数据。它记录文件和目录的树形结构,并维护每个文件块的位置。NameNode 是 HDFS 的核心,所有的文件操作请求都需要通过 NameNode 来完成。
|
||||
- **DataNode**:负责存储实际的数据块,并执行块的读写操作。每个 DataNode 定期向 NameNode 汇报其状态(心跳信号和块报告),以便 NameNode 能追踪数据块的分布和健康状态。
|
||||
|
||||
此外,还有一些辅助组件:
|
||||
|
||||
- **Secondary NameNode**:负责定期获取 NameNode 的元数据快照,辅助 NameNode 进行崩溃恢复,但不替代 NameNode 的功能。
|
||||
- **JournalNode**:在高可用 HDFS 配置中,用于保存 NameNode 的元数据日志,确保在主 NameNode 失败时可以无缝切换到备 NameNode。
|
||||
|
||||
#### 数据存储和复制机制
|
||||
|
||||
HDFS 将文件划分为固定大小的数据块(默认 64MB 或 128MB),并将每个数据块复制到多个 DataNode 上(默认 3 个副本),以提高数据的可靠性和容错性。数据块的多副本机制确保即使某个 DataNode 发生故障,数据仍然可以从其他副本中恢复。
|
||||
|
||||
```mermaid
|
||||
sequenceDiagram
|
||||
participant Client as Client
|
||||
participant NameNode as NameNode
|
||||
participant DataNode1 as DataNode 1
|
||||
participant DataNode2 as DataNode 2
|
||||
participant DataNode3 as DataNode 3
|
||||
|
||||
Client->>NameNode: Request to Write File
|
||||
NameNode-->>Client: Respond with DataNodes and Block IDs
|
||||
note right of NameNode: NameNode allocates blocks and selects DataNodes for storage.
|
||||
|
||||
Client->>DataNode1: Write Block 1 (part 1)
|
||||
DataNode1-->>Client: ACK Block 1 (part 1) Received
|
||||
Client->>DataNode2: Write Block 1 (part 2)
|
||||
DataNode2-->>Client: ACK Block 1 (part 2) Received
|
||||
Client->>DataNode3: Write Block 1 (part 3)
|
||||
DataNode3-->>Client: ACK Block 1 (part 3) Received
|
||||
|
||||
Client->>NameNode: Notify Block 1 Written
|
||||
note right of NameNode: NameNode updates block metadata with DataNode locations.
|
||||
|
||||
Client->>DataNode1: Write Block 2 (part 1)
|
||||
DataNode1-->>Client: ACK Block 2 (part 1) Received
|
||||
Client->>DataNode2: Write Block 2 (part 2)
|
||||
DataNode2-->>Client: ACK Block 2 (part 2) Received
|
||||
Client->>DataNode3: Write Block 2 (part 3)
|
||||
DataNode3-->>Client: ACK Block 2 (part 3) Received
|
||||
|
||||
Client->>NameNode: Notify Block 2 Written
|
||||
note right of NameNode: NameNode updates block metadata with DataNode locations.
|
||||
|
||||
Client->>DataNode1: Write Block 3 (part 1)
|
||||
DataNode1-->>Client: ACK Block 3 (part 1) Received
|
||||
Client->>DataNode2: Write Block 3 (part 2)
|
||||
DataNode2-->>Client: ACK Block 3 (part 2) Received
|
||||
Client->>DataNode3: Write Block 3 (part 3)
|
||||
DataNode3-->>Client: ACK Block 3 (part 3) Received
|
||||
|
||||
Client->>NameNode: Notify Block 3 Written
|
||||
note right of NameNode: NameNode updates block metadata with DataNode locations.
|
||||
|
||||
Client->>NameNode: Request to Read File
|
||||
NameNode-->>Client: Respond with DataNodes and Block IDs
|
||||
note right of NameNode: NameNode provides block locations for requested file.
|
||||
|
||||
Client->>DataNode1: Read Block 1
|
||||
DataNode1-->>Client: Send Block 1 Data
|
||||
Client->>DataNode2: Read Block 2
|
||||
DataNode2-->>Client: Send Block 2 Data
|
||||
Client->>DataNode3: Read Block 3
|
||||
DataNode3-->>Client: Send Block 3 Data
|
||||
```
|
||||
|
||||
- **数据块划分**:大文件被拆分成多个数据块存储在不同的 DataNode 上,以实现并行处理。
|
||||
- **副本管理**:NameNode 决定每个数据块的副本数量和存放位置,确保副本均匀分布,以提高系统的可靠性和读取效率。
|
||||
- **副本放置策略**:为了提高数据的可靠性和可用性,HDFS 通常将一个副本放在本地机架,第二个副本放在同一机架的不同节点上,第三个副本放在不同机架的节点上。
|
||||
|
||||
#### HDFS 的优缺点及应用场景
|
||||
|
||||
**优点**:
|
||||
|
||||
- **高容错性**:通过数据块的多副本机制保障数据安全。当一个或多个 DataNode 发生故障时,数据仍然可以从其他副本中恢复。
|
||||
- **高吞吐量**:适合大规模数据的批处理。HDFS 优化了数据的流式传输,支持大文件的高吞吐量数据访问。
|
||||
- **可扩展性**:易于扩展集群规模。通过添加新的 DataNode,HDFS 可以方便地扩展存储容量和处理能力。
|
||||
|
||||
**缺点**:
|
||||
|
||||
- **不适合低延迟的数据访问**:HDFS 设计初衷是为批处理优化,而不是低延迟的随机读写操作。
|
||||
- **小文件存储效率低**:HDFS 更适合大文件存储,小文件会带来元数据管理的负担和存储效率问题。
|
||||
|
||||
**应用场景**:
|
||||
|
||||
- **大数据分析与处理**:如 MapReduce 任务。HDFS 被广泛应用于大数据分析平台,支持海量数据的并行处理。
|
||||
- **数据仓库和日志处理**:HDFS 常用于数据仓库的底层存储,以及日志数据的存储和处理。
|
||||
|
||||
### Google File System (GFS)
|
||||
|
||||
#### 设计目标
|
||||
|
||||
Google File System (GFS) 是 Google 设计的一种可扩展的分布式文件系统,旨在支持大规模数据处理应用。GFS 的设计目标包括高容错性、高性能和高扩展性。GFS 的诞生背景是为了应对 Google 在互联网搜索和数据分析中面临的大量数据存储和处理需求。GFS 被设计为能够处理海量数据集,并且能够在廉价硬件上运行,同时具备良好的容错性和高性能。
|
||||
|
||||
#### 历史发展
|
||||
|
||||
GFS 的开发始于 2000 年,最初由 Sanjay Ghemawat、Howard Gobioff 和 Shun-Tak Leung 领导的团队设计。GFS 在 2003 年正式发布,并在 Google 内部得到广泛应用,支持 Google 搜索、广告和其他大规模数据处理任务。GFS 的设计和实现奠定了现代分布式文件系统的基础,影响了后来的许多文件系统,如 HDFS。
|
||||
|
||||
#### 架构与组件
|
||||
|
||||

|
||||
|
||||
GFS 采用主从架构,由一个 Master 和多个 ChunkServer 组成:
|
||||
|
||||
- **Master**:管理文件系统元数据,如命名空间、访问控制信息和文件块(chunk)的位置信息。Master 还负责协调系统中的各种操作,如数据块的分配、复制和负载均衡。
|
||||
- **ChunkServer**:存储实际的文件块,并执行读写请求。每个 ChunkServer 都存储多个文件块,并通过心跳机制向 Master 汇报其状态和所持有的数据块信息。
|
||||
|
||||
GFS 的架构还包括一个客户端库,提供给应用程序使用,使其能够与 GFS 进行交互。客户端直接与 ChunkServer 通信进行数据读写操作,从而减轻 Master 的负担。
|
||||
|
||||
#### 数据分片与复制策略
|
||||
|
||||
GFS 将文件划分为固定大小的块(64MB),每个块有一个唯一的全局 ID,并被复制到多个 ChunkServer 上(默认 3 个副本),以提高数据的可靠性。
|
||||
|
||||
- **数据块划分**:每个文件被拆分成固定大小的数据块,这些数据块被分布存储在不同的 ChunkServer 上。
|
||||
- **副本管理**:每个数据块默认有三个副本,分布在不同的 ChunkServer 上,以确保高可用性和容错性。
|
||||
- **副本放置策略**:GFS 通过副本放置策略确保数据在不同物理位置和机架之间分布,以提高系统的容错性和数据可用性。
|
||||
|
||||
Master 负责监控数据块的副本情况,并在副本丢失或损坏时自动创建新的副本。
|
||||
|
||||
#### GFS 的优缺点及应用场景
|
||||
|
||||
**优点**:
|
||||
|
||||
- **高容错性**:通过多副本和定期的完整性检查保障数据安全。GFS 能够在硬件故障频繁发生的环境中保持高可用性。
|
||||
- **高性能**:适合大文件的高吞吐量数据访问。GFS 优化了数据的流式传输,支持大规模数据处理任务。
|
||||
- **可扩展性**:通过增加 ChunkServer 节点,GFS 可以轻松扩展存储容量和计算能力。
|
||||
|
||||
**缺点**:
|
||||
|
||||
- **主节点是单点故障**:尽管 GFS 设计了多种机制来提高 Master 的可靠性,但它仍然是单点故障。如果 Master 失败,系统的可用性会受到影响。
|
||||
- **不适合小文件和低延迟数据访问**:GFS 更适合大文件存储和批处理任务,对小文件和低延迟访问的支持较差。
|
||||
|
||||
**应用场景**:
|
||||
|
||||
- **大规模数据处理应用**:如 Google 的搜索和数据分析任务。GFS 能够处理 PB 级数据,并支持高效的数据读写和分析。
|
||||
- **存储和处理大量日志数据**:GFS 非常适合存储和处理来自多个数据源的大量日志文件,支持大规模日志分析和数据挖掘。
|
||||
|
||||
### GlusterFS
|
||||
|
||||
#### 概述与历史
|
||||
|
||||
GlusterFS 是一个开源的分布式文件系统,旨在处理海量数据存储。它最初由 Gluster 公司开发,并已被 Red Hat 收购。GlusterFS 以其高扩展性和灵活性而著称,能够在无需改变应用程序代码的情况下,通过聚合多台存储服务器,实现高性能和高可用性的数据存储解决方案。
|
||||
|
||||
GlusterFS 的设计理念是通过对等架构(peer-to-peer architecture)消除单点故障,增强系统的容错性和扩展性。自 2005 年首次发布以来,GlusterFS 已经经历了多次重大更新和改进,成为企业级存储解决方案的首选之一。
|
||||
|
||||
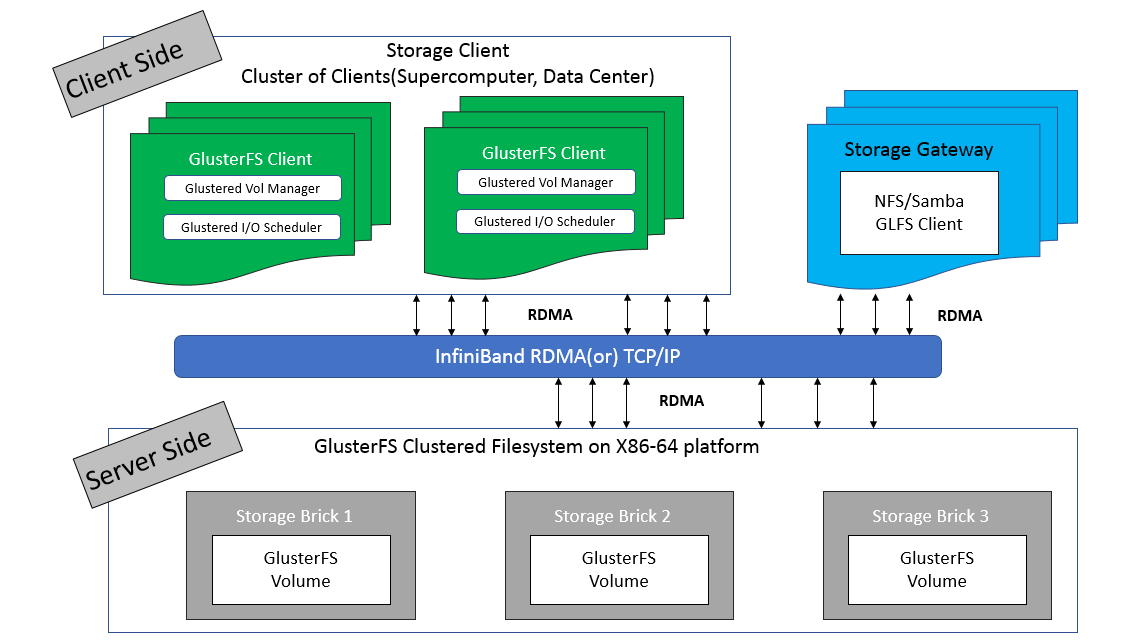
#### 架构与工作原理
|
||||
|
||||
|
||||
|
||||
GlusterFS 采用无中心节点的对等架构,每个节点同时充当客户端和服务器。它通过将多个存储服务器聚合成一个大的并行文件系统来实现扩展。GlusterFS 的主要组件包括:
|
||||
|
||||
- **Gluster 节点(Gluster Node)**:每个节点既是客户端又是服务器,负责存储和提供文件数据。
|
||||
- **砖(Brick)**:每个节点上的存储单元,通常是一个挂载点或目录。多个砖组成一个卷(volume)。
|
||||
- **卷(Volume)**:由多个砖组成,是 GlusterFS 的基本存储单元。卷通过聚合不同的砖提供存储服务。
|
||||
|
||||
GlusterFS 的工作原理包括:
|
||||
|
||||
- **卷管理**:通过卷管理器(Volume Manager)来创建和配置卷。卷可以是分布式卷、复制卷或条带化卷,根据应用需求选择合适的卷类型。
|
||||
- **分布式哈希表(DHT)**:用于分布式卷的文件分配。DHT 根据文件名计算哈希值,并将文件分配到合适的砖上。
|
||||
- **自我修复**:GlusterFS 具有内置的自我修复机制,当检测到数据不一致时,会自动进行数据同步和修复。
|
||||
|
||||
#### 存储卷的管理与配置
|
||||
|
||||
GlusterFS 通过卷(Volume)管理存储。卷由一个或多个砖(Brick)组成,每个砖对应一个存储服务器上的目录。常见的卷类型包括:
|
||||
|
||||
- **分布式卷(Distributed Volume)**:将文件分布在所有砖上,适合需要高吞吐量和大容量的应用场景。
|
||||
- **复制卷(Replicated Volume)**:在多个砖之间复制文件,提高数据的冗余性和可用性,适合高可用性需求的应用。
|
||||
- **条带化卷(Striped Volume)**:将文件分块存储在多个砖上,适合大文件的高性能读写需求。
|
||||
- **分布式复制卷(Distributed Replicated Volume)**:结合分布和复制特性,既保证数据的高可用性,又能扩展存储容量。
|
||||
|
||||
配置卷的步骤包括:
|
||||
|
||||
1. **创建卷**:使用 `gluster volume create` 命令创建所需类型的卷。
|
||||
2. **启动卷**:使用 `gluster volume start` 命令启动创建的卷。
|
||||
3. **挂载卷**:使用客户端将卷挂载到本地文件系统,通常使用 FUSE(Filesystem in Userspace)挂载。
|
||||
|
||||
#### GlusterFS 的优缺点及应用场景
|
||||
|
||||
**优点**:
|
||||
|
||||
- **高可扩展性**:可以通过添加节点无缝扩展存储容量,适应数据增长需求。
|
||||
- **高可用性**:通过数据复制和分布式架构实现数据的高可用性,避免单点故障。
|
||||
- **灵活性**:支持多种卷类型,能够根据不同应用需求进行灵活配置。
|
||||
|
||||
**缺点**:
|
||||
|
||||
- **性能在高负载下可能下降**:在高负载情况下,性能可能会受到影响,需要优化配置。
|
||||
- **配置和管理相对复杂**:需要一定的专业知识和经验进行配置和管理,特别是在大规模部署时。
|
||||
|
||||
**应用场景**:
|
||||
|
||||
- **大规模数据存储和备份**:适合企业级大规模数据存储和备份解决方案,能够提供高可用性和数据安全性。
|
||||
- **多媒体内容存储和分发**:适用于多媒体文件的存储和分发,如视频、音频和图像文件,能够支持高吞吐量和大文件存储需求。
|
||||
- **虚拟化环境和云计算**:支持虚拟机和容器存储,适用于云计算和虚拟化环境中的数据存储解决方案。
|
||||
|
||||
### CephFS
|
||||
|
||||
#### 概述
|
||||
|
||||
CephFS 是 Ceph 分布式存储系统的一部分,提供 POSIX 兼容的文件系统接口。CephFS 利用 Ceph 强大的分布式存储架构,实现高性能和高可靠性的文件存储服务。Ceph 的设计目标是创建一个统一的、可扩展的存储平台,支持对象存储、块存储和文件系统。CephFS 通过元数据服务器(MDS)和对象存储设备(OSD)协同工作,实现了文件系统的高效管理和数据存储。
|
||||
|
||||
|
||||
|
||||
#### 历史发展
|
||||
|
||||
Ceph 的开发始于 2004 年,由 Sage Weil 在加州大学圣克鲁兹分校作为博士研究项目启动。2010 年,Ceph 项目被 Inktank 公司商业化,随后于 2014 年被 Red Hat 收购。Ceph 的设计灵感来源于需要高扩展性和高性能的分布式存储解决方案,其独特的 CRUSH 算法和无中心架构使其在众多分布式存储系统中脱颖而出。
|
||||
|
||||
#### Ceph 集群的架构与组件
|
||||
|
||||
Ceph 集群由以下几部分组成:
|
||||
|
||||
- **Monitor (MON)**:负责维护集群状态、管理元数据和认证服务。Monitor 节点保持集群的一致性和健康状态,管理集群成员和元数据信息。
|
||||
- **Object Storage Device (OSD)**:负责存储数据并处理数据的读写请求。每个 OSD 节点负责管理一部分数据存储,执行数据复制、恢复和再平衡等操作。
|
||||
- **Metadata Server (MDS)**:管理文件系统的元数据,支持快速文件系统操作。MDS 维护文件系统的目录结构和文件元数据,处理客户端的文件操作请求。
|
||||
|
||||
#### 元数据服务器(MDS)和对象存储设备(OSD)
|
||||
|
||||
CephFS 通过 MDS 管理文件系统元数据,OSD 存储实际的数据。MDS 和 OSD 协同工作,实现高效的数据存取和元数据管理。
|
||||
|
||||
- **Metadata Server (MDS)**:MDS 负责处理文件系统的元数据操作,如目录查询、文件创建和删除。MDS 分担了文件系统操作的负载,提高了整体系统的性能和响应速度。CephFS 支持多个 MDS 节点,以实现负载均衡和高可用性。
|
||||
- **Object Storage Device (OSD)**:OSD 节点负责存储数据块,并执行数据读写操作。每个文件被分解为多个数据块,并通过 Ceph 的 CRUSH 算法分布在多个 OSD 节点上。OSD 节点之间通过网络进行数据同步和恢复,确保数据的一致性和可靠性。
|
||||
|
||||
#### CephFS 的优缺点及应用场景
|
||||
|
||||
**优点**:
|
||||
|
||||
- **高性能**:支持高吞吐量和低延迟的数据访问。CephFS 利用高效的元数据管理和数据分布策略,实现快速的数据读写操作。
|
||||
- **高可扩展性**:通过添加更多的 OSD 和 MDS 节点实现水平扩展。CephFS 可以根据存储需求的增长灵活扩展,无需中断服务。
|
||||
- **高可靠性**:通过多副本和纠删码保障数据安全。CephFS 具备强大的数据保护机制,确保数据在硬件故障或网络故障时的安全性。
|
||||
|
||||
**缺点**:
|
||||
|
||||
- **部署和配置相对复杂**:CephFS 的部署和配置需要较高的技术知识和经验,特别是在大规模集群环境中。
|
||||
- **需要较高的硬件资源支持**:CephFS 的性能和可靠性依赖于高质量的硬件资源,包括高速网络、SSD 存储和充足的内存。
|
||||
|
||||
**应用场景**:
|
||||
|
||||
- **高性能计算(HPC)和科学研究数据存储**:CephFS 适用于需要高吞吐量和大规模数据存储的高性能计算和科学研究领域。
|
||||
- **企业级数据存储和备份解决方案**:CephFS 提供可靠的企业级存储解决方案,适用于存储和备份大量企业数据,确保数据的高可用性和安全性。
|
||||
- **云计算和虚拟化环境**:CephFS 支持云计算和虚拟化环境中的数据存储需求,提供灵活的存储扩展能力和高效的数据访问性能。
|
||||
@ -1,571 +0,0 @@
|
||||
---
|
||||
title: Linux 用户和权限
|
||||
description: Linux 用户和权限
|
||||
keywords:
|
||||
- Linux
|
||||
- 用户
|
||||
- 权限
|
||||
tags:
|
||||
- Linux/基础
|
||||
- 技术/操作系统
|
||||
author: 7Wate
|
||||
date: 2023-03-30
|
||||
---
|
||||
|
||||
## 概述
|
||||
|
||||
Linux 多用户系统的历史可以追溯到 1960 年代的 Unix 系统,Unix 是一种多用户、多任务的操作系统,被广泛应用于大型计算机和服务器上。随着 Linux 的发展,它也成为了一种强大的多用户操作系统,并被广泛应用于服务器、个人电脑和移动设备等领域。
|
||||
|
||||
Linux 多用户系统的设计基于以下原则:
|
||||
|
||||
- 每个用户都有一个唯一的标识符(UID),用于标识其身份。
|
||||
- 每个用户可以分配到一个或多个用户组(Group),用户组也有一个唯一的标识符(GID)。
|
||||
- 每个文件和目录都有一个所有者(Owner)和一个所属用户组(Group),用于控制访问权限。
|
||||
- 每个用户都有一个主目录(Home Directory),用于存储其个人文件和设置。
|
||||
- 系统管理员可以创建、删除和管理用户和用户组,以及控制用户的权限和访问权限。
|
||||
|
||||
Linux 多用户系统的实现基于以下机制:
|
||||
|
||||
- 用户和用户组的信息存储在特定的配置文件中,如 /etc/passwd、/etc/shadow、/etc/group 和 /etc/gshadow。
|
||||
- 用户登录时需要进行身份验证,通常使用用户名和密码进行认证。
|
||||
- 系统管理员可以使用命令行工具或图形界面来创建、删除和管理用户和用户组,以及配置用户的权限和访问权限。
|
||||
- Linux 系统提供了许多安全机制,如访问控制列表(ACL)、文件系统权限和 SELinux 等,用于保护系统和用户的数据安全。
|
||||
|
||||
目前随着云计算、容器化和虚拟化技术的发展,Linux 多用户系统的方向也在不断发展。未来的趋势包括:
|
||||
|
||||
- 更加丰富和灵活的权限管理机制,如更细粒度的 ACL 和更灵活的访问控制策略。
|
||||
- 更加集成和自动化的用户和权限管理工具,如自动化用户创建和删除、自动化权限管理和集成用户和权限管理工具等。
|
||||
- 更加安全和可靠的身份验证机制,如双因素身份验证和基于生物识别的身份验证等。
|
||||
- 更加简单和易用的图形界面和命令行工具,以方便用户进行用户和权限管理操作。
|
||||
|
||||
Linux 多用户系统具有强大的用户和权限管理功能,可以帮助管理员有效地管理系统和保护用户数据的安全。管理员可以使用命令行工具或图形界面来创建、删除和管理用户和用户组,以及配置用户的权限和访问权限。
|
||||
|
||||
在使用 root 用户时,应注意系统的安全性,并使用 `sudo` 或 `su` 命令以普通用户身份执行命令。文件和目录的权限由三个组件组成,每个组件可以设置为读取、写入和执行权限,这些权限用数字表示。
|
||||
|
||||
在 Linux 系统中,有多个配置文件存储用户和权限信息,包括 `/etc/passwd`、`/etc/shadow`、`/etc/group`、`/etc/gshadow`、`/etc/login.defs` 和 `/etc/adduser.conf` 等文件。
|
||||
|
||||
## 用户
|
||||
|
||||
### 创建
|
||||
|
||||
#### Useradd
|
||||
|
||||
`useradd` 命令是 Linux 系统中的一个命令行工具,用于创建新用户帐户。通过 `useradd` 命令,可以指定新用户的用户名、用户 ID(UID)、主目录、默认 shell 和密码等信息。
|
||||
|
||||
在大多数 Linux 系统中,只有管理员用户(如 root 用户)可以创建新用户。通常情况下,管理员用户需要使用 `sudo` 命令或以 root 用户身份登录系统,才能使用 `useradd` 命令创建新用户。
|
||||
|
||||
```shell
|
||||
# 创建一个新用户
|
||||
sudo useradd john
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ------------------------------ | --------------------------------------------------- | -------------------------------------- |
|
||||
| `-c, --comment COMMENT` | 指定用户的注释字段。 | `sudo useradd -c "John Smith" john` |
|
||||
| `-d, --home-dir HOME_DIR` | 指定用户的家目录。 | `sudo useradd -d /home/john john` |
|
||||
| `-e, --expiredate EXPIRE_DATE` | 指定用户的账户过期日期。 | `sudo useradd -e 2023-06-30 john` |
|
||||
| `-f, --inactive INACTIVE` | 设置密码过期后的不活动期限为 INACTIVE,以禁用账户。 | `sudo useradd -f 30 john` |
|
||||
| `-g, --gid GROUP` | 指定用户的主用户组。 | `sudo useradd -g staff john` |
|
||||
| `-G, --groups GROUPS` | 指定用户所属的其他用户组。 | `sudo useradd -G staff,developer john` |
|
||||
| `-m, --create-home` | 创建用户的家目录。 | `sudo useradd -m john` |
|
||||
| `-p, --password PASSWORD` | 指定用户的加密密码。 | `sudo useradd -p password_hash john` |
|
||||
| `-s, --shell SHELL` | 指定用户的默认 shell。 | `sudo useradd -s /bin/bash john` |
|
||||
| `-u, --uid UID` | 指定用户的 UID。 | `sudo useradd -u 1001 john` |
|
||||
|
||||
### 管理
|
||||
|
||||
#### Chfn
|
||||
|
||||
`chfn`(Change Finger)命令用于修改用户信息。该命令可以用来更改用户的全名、办公室电话、家庭电话、其他说明等信息。
|
||||
|
||||
```shell
|
||||
# 更改当前用户信息
|
||||
debian@SevenWate-PC:$ chfn
|
||||
Password:
|
||||
Changing the user information for debian
|
||||
Enter the new value, or press ENTER for the default
|
||||
Full Name:
|
||||
Room Number []:
|
||||
Work Phone []:
|
||||
Home Phone []:
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ------------------- | -------------------------- | ---------------------------------------------- |
|
||||
| `-f, --full-name` | 更改用户的全名。 | `chfn --full-name "John Doe" [username]` |
|
||||
| `-h, --home-phone` | 更改用户的家庭电话号码。 | `chfn --home-phone "123-456-7890" [username]` |
|
||||
| `-o, --other` | 更改用户的其他说明。 | `chfn --other "这是一个测试用户" [username]` |
|
||||
| `-r, --room-number` | 更改用户的办公室电话号码。 | `chfn --room-number "555-1234" [username]` |
|
||||
| `-u, --uid` | 更改用户的 UID。 | `chfn --uid 1001 [username]` |
|
||||
| `-c, --comment` | 更改用户的注释字段。 | `chfn --comment "这是一个测试用户" [username]` |
|
||||
|
||||
#### Chsh
|
||||
|
||||
`chsh` (Change Shell)命令是 Linux 系统中的一个命令行工具,用于更改用户的默认 shell。默认情况下,用户登录后会进入一个特定的 shell 环境,该环境定义了用户与系统交互的方式。`chsh` 命令可用于更改用户的默认 shell,从而改变用户与系统交互的方式。
|
||||
|
||||
```shell
|
||||
# 查看当前系统 shell
|
||||
cat /etc/shells
|
||||
|
||||
# 更改当前用户的默认 shell
|
||||
chsh -s /bin/bash
|
||||
|
||||
# 更改其他用户的默认 shell
|
||||
chsh -s /bin/bash john
|
||||
```
|
||||
|
||||
#### Passwd
|
||||
|
||||
`passwd` (Password)命令是 Linux 系统中的一个命令行工具,用于更改用户的密码或口令。默认情况下,每个 Linux 用户都有一个口令或密码来保护其账户的安全性。`passwd` 命令可用于更改密码或口令。
|
||||
|
||||
```shell
|
||||
# 更改当前用户的
|
||||
passwd
|
||||
|
||||
# 更改其他用户的密码
|
||||
passwd john
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| -------------- | -------------------------------------- | --------------------------- |
|
||||
| `-l, --lock` | 锁定用户的账户,禁止用户登录。 | `sudo passwd --lock john` |
|
||||
| `-u, --unlock` | 解锁用户的账户,允许用户登录。 | `sudo passwd --unlock john` |
|
||||
| `-d, --delete` | 删除用户的密码或口令,允许无密码登录。 | `sudo passwd --delete john` |
|
||||
| `-e, --expire` | 强制用户在下一次登录时更改密码或口令。 | `sudo passwd --expire john` |
|
||||
| `-S, --status` | 显示用户密码或口令的状态。 | `passwd --status john` |
|
||||
|
||||
#### Usermod
|
||||
|
||||
`usermod`(User Modify)命令是 Linux 系统中的一个命令行工具,用于修改用户的属性或配置。`usermod` 命令允许您更改现有用户的用户名、UID、主目录、默认 shell 等信息,还可以将用户添加到其他用户组中。
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ------------------------------ | --------------------------------------------------- | ------------------------------------ |
|
||||
| `-c, --comment COMMENT` | 指定用户的注释字段。 | `sudo usermod -c "John Smith" john` |
|
||||
| `-d, --home HOME_DIR` | 指定用户的家目录。 | `sudo usermod -d /home/newhome john` |
|
||||
| `-e, --expiredate EXPIRE_DATE` | 指定用户的账户过期日期。 | `sudo usermod -e 2023-06-30 john` |
|
||||
| `-f, --inactive INACTIVE` | 设置密码过期后的不活动期限为 INACTIVE,以禁用账户。 | `sudo usermod -f 30 john` |
|
||||
| `-g, --gid GROUP` | 指定用户的主用户组。 | `sudo usermod -g staff john` |
|
||||
| `-aG, --add-subgroups` | 将用户添加到附加组 | `sudo usermod -aG audio john` |
|
||||
| `-l, --login NEW_LOGIN` | 更改用户的登录名。 | `sudo usermod -l newname john` |
|
||||
| `-p, --password PASSWORD` | 指定用户的加密密码。 | `sudo usermod -p password_hash john` |
|
||||
| `-s, --shell SHELL` | 指定用户的默认 shell。 | `sudo usermod -s /bin/bash john` |
|
||||
| `-u, --uid UID` | 指定用户的 UID。 | `sudo usermod -u 1001 john` |
|
||||
|
||||
### 删除
|
||||
|
||||
#### Userdel
|
||||
|
||||
`userdel`(User Delete)命令是 Linux 系统中的一个命令行工具,用于删除现有用户帐户。默认情况下,`userdel` 命令仅删除用户的帐户,而不删除用户的主目录和邮件箱。如果需要删除用户的主目录和邮件箱,可以使用 `-r` 选项。
|
||||
|
||||
```shell
|
||||
# 删除一个用户
|
||||
sudo userdel john
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| -------------- | -------------------------------------------------- | ---------------------- |
|
||||
| `-f, --force` | 强制删除用户,即使用户当前已登录或有未完成的进程。 | `sudo userdel -f john` |
|
||||
| `-r, --remove` | 删除用户及其主目录。 | `sudo userdel -r john` |
|
||||
|
||||
## 用户组
|
||||
|
||||
### 创建
|
||||
|
||||
#### Groupadd
|
||||
|
||||
`groupadd` 命令是 Linux 系统中的一个命令行工具,用于创建新的用户组。管理员用户(如 root 用户)可以使用 `groupadd` 命令创建新组。
|
||||
|
||||
```shell
|
||||
# 创建一个新组
|
||||
sudo groupadd newgroup
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| --------------------- | ------------------------------------------------------------ | ------------------------------------------ |
|
||||
| `-g, --gid GID` | 指定新组的 GID。如果未指定,系统会自动分配一个未使用的 GID。 | `sudo groupadd -g 1001 newgroup` |
|
||||
| `-K, --key KEY=VALUE` | 指定要应用于新组的 SELinux 标签。 | `sudo groupadd -K "type=staff_u" newgroup` |
|
||||
| `-r, --system` | 创建一个系统组,该组的 GID 小于 1000,且不会在登录屏幕上显示。 | `sudo groupadd -r newgroup` |
|
||||
|
||||
### 管理
|
||||
|
||||
#### Groups
|
||||
|
||||
`groups` 命令是 Linux 系统中的一个命令行工具,用于显示当前用户所属的用户组。如果没有指定用户名,则 `groups` 命令将显示当前用户所属的用户组。
|
||||
|
||||
```shell
|
||||
# 显示当前用户所属的用户组
|
||||
groups
|
||||
|
||||
# 显示指定用户所属的用户组
|
||||
groups john
|
||||
```
|
||||
|
||||
#### Gpasswd
|
||||
|
||||
`gpasswd` (Group Password)命令是 Linux 系统中的一个命令行工具,用于管理用户组的密码和成员列表。管理员用户(如 root 用户)可以使用 `gpasswd` 命令来添加或删除用户组的成员,或者设置或删除用户组的密码。
|
||||
|
||||
```shell
|
||||
# 设置组密码
|
||||
sudo gpasswd newgroup
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ------------------------------- | ------------------------------------------------------------ | ------------------------------------ |
|
||||
| `-a, --add USER` | 将指定的用户添加到指定的用户组中。 | `sudo gpasswd -a john newgroup` |
|
||||
| `-d, --delete USER` | 从指定的用户组中删除指定的用户。 | `sudo gpasswd -d john newgroup` |
|
||||
| `-M, --members USER1,USER2,...` | 将指定的用户列表设置为指定组的成员。 | `sudo gpasswd -M john,jane newgroup` |
|
||||
| `-r, --remove-password` | 从指定的用户组中删除密码。 | `sudo gpasswd -r newgroup` |
|
||||
| `-R, --restrict` | 启用限制模式。在此模式下,只有组的所有者和管理员才能更改组成员身份。 | `sudo gpasswd -R newgroup` |
|
||||
|
||||
#### Groupmod
|
||||
|
||||
`groupmod` (Group Modify)命令是 Linux 系统中的一个命令行工具,用于修改已有用户组的属性,例如组 ID、组名称和组密码等。管理员用户(如 root 用户)可以使用 `groupmod` 命令来更改用户组的属性。
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| -------------------------- | ---------------------------- | -------------------------------------- |
|
||||
| `-g, --gid GID` | 将组的 GID 设置为指定的值。 | `sudo groupmod -g 1001 newgroup` |
|
||||
| `-n, --new-name NEW_GROUP` | 将组的名称更改为指定的名称。 | `sudo groupmod -n newgroup2 newgroup` |
|
||||
| `-o, --non-unique` | 允许使用非唯一 GID 创建组。 | `sudo groupmod -o newgroup` |
|
||||
| `-p, --password PASSWORD` | 将组密码设置为指定的密码。 | `sudo groupmod -p mypassword newgroup` |
|
||||
|
||||
### 删除
|
||||
|
||||
#### Groupdel
|
||||
|
||||
`groupdel` (Group Delete)是 Linux 系统中的一个命令行工具,用于删除一个用户组。删除用户组时,系统会自动将该组的所有成员从该组中删除,并将文件和目录中的组 ID 更改为其他组。
|
||||
|
||||
```shell
|
||||
# 删除一个用户组
|
||||
sudo groupdel newgroup
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ----------------------- | ---------------------------------- | -------------------------------------------- |
|
||||
| `-f, --force` | 强制删除用户组,即使该组仍有成员。 | `sudo groupdel -f newgroup` |
|
||||
| `-h, --help` | 显示命令帮助信息。 | `groupdel -h` |
|
||||
| `-R, --root CHROOT_DIR` | 在指定的 chroot 环境中运行命令。 | `sudo groupdel --root /mnt/newroot newgroup` |
|
||||
| `-v, --verbose` | 显示命令详细输出。 | `sudo groupdel -v newgroup` |
|
||||
|
||||
## Root 超级用户
|
||||
|
||||
在 Linux 系统中,root 是超级用户,具有完全的系统管理权限。root 用户可以执行任何命令,并访问系统中的所有文件和资源。在默认情况下,root 用户的密码是空的,因此在安全性方面需要额外注意。
|
||||
|
||||
### Su
|
||||
|
||||
`su`(Switch User)命令是 Linux 系统中的一个命令行工具,它允许您在不注销当前用户的情况下切换到其他用户帐户。默认情况下,`su` 命令切换到超级用户帐户(root)。
|
||||
|
||||
```shell
|
||||
# 默认切换 root
|
||||
su
|
||||
|
||||
# 切换到 debian
|
||||
su debian
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ----------------------- | ------------------------------------------------------------ | ----------------------- |
|
||||
| `-c, --command COMMAND` | 在切换到另一个用户后执行指定的命令或脚本。 | `su -c "ls -l" user1` |
|
||||
| `-s, --shell SHELL` | 指定要使用的 shell,而不是默认 shell。 | `su -s /bin/bash user1` |
|
||||
| `-l, --login` | 在切换用户时模拟完整的登录过程,包括加载环境变量、切换工作目录等。 | `su -l user` |
|
||||
|
||||
### Sudo
|
||||
|
||||
在 Unix 和类 Unix 系统中,`sudo` 是一个强大的工具,允许普通用户以超级用户(root)的权限来执行特定的命令或访问受限资源。`sudo` 命令的行为是由一个配置文件来定义的,这个文件通常称为 `sudoers` 文件。
|
||||
|
||||
`sudoers` 文件位于 `/etc/sudoers` 或 `/etc/sudoers.d` 目录中,并且只有超级用户(root)有权限进行编辑。下面是一个 `sudoers` 文件的示例内容:
|
||||
|
||||
```shell
|
||||
# 允许 `sudo` 组的成员以任何用户身份(ALL:ALL)执行任何命令(ALL)。
|
||||
%sudo ALL=(ALL:ALL) ALL
|
||||
|
||||
# 允许 `admin` 组的成员以任何用户身份(ALL:ALL)执行任何命令(ALL)。
|
||||
%admin ALL=(ALL:ALL) ALL
|
||||
|
||||
# 允许 `root` 用户以任何用户身份(ALL:ALL)执行任何命令(ALL)。
|
||||
root ALL=(ALL:ALL) ALL
|
||||
|
||||
# 允许 `sudo` 组的成员以任何用户身份(ALL:ALL)执行任何命令(ALL),并且无需输入密码(NOPASSWD)。
|
||||
%sudo ALL=(ALL:ALL) NOPASSWD: ALL
|
||||
```
|
||||
|
||||
在 `sudoers` 文件中,每个规则的一般格式如下:
|
||||
|
||||
```shell
|
||||
user/group hosts=(users:groups) commands
|
||||
```
|
||||
|
||||
- `user/group`:指定用户或用户组,可以使用用户名或组名。
|
||||
- `hosts`:指定可以使用 `sudo` 命令的主机列表,可以是主机名、IP 地址或特殊的通配符。
|
||||
- `users:groups`:指定要执行命令的用户和组,以冒号分隔。
|
||||
- `commands`:指定允许执行的命令。
|
||||
|
||||
`sudoers` 文件中的规则可以使用特殊符号和关键字来增加灵活性。例如:
|
||||
|
||||
- `ALL`:表示匹配所有主机、用户或命令。
|
||||
- `ALL=(ALL:ALL)`:表示以任何用户身份在任何主机上执行任何命令。
|
||||
- `NOPASSWD`:表示无需输入密码。
|
||||
|
||||
**需要注意的是,对 `sudoers` 文件的修改应当谨慎进行,并且建议使用 `visudo` 命令来编辑 `sudoers` 文件,以确保语法正确并避免意外的访问限制。**`visudo` 会对文件进行验证并在保存前进行检查,以防止可能导致系统故障的错误配置。
|
||||
|
||||
以下是创建 `sudo` 用户的步骤:
|
||||
|
||||
```shell
|
||||
1.创建用户
|
||||
sudo adduser username
|
||||
|
||||
2.将用户添加到 sudo 组
|
||||
sudo usermod -aG sudo username
|
||||
|
||||
3.检查用户是否已成功添加到 sudo 组
|
||||
groups username
|
||||
|
||||
4.确认用户可以使用 sudo 命令
|
||||
sudo -l -U username
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ----------------------- | ------------------------------------------------------------ | --------------------------------------- |
|
||||
| `-u, --user USER` | 指定要切换到的用户。 | `sudo -u user1 ls -l` |
|
||||
| `-g, --group GROUP` | 指定要切换到的组。 | `sudo -g group1 ls -l` |
|
||||
| `-k, --reset-timestamp` | 重置 `sudo` 命令的时间戳。 | `sudo -k` |
|
||||
| `-v, --validate` | 验证 `sudo` 命令的权限,但不执行任何命令。 | `sudo -v` |
|
||||
| `-l, --list [COMMAND]` | 显示 `sudo` 命令当前用户的授权信息,或显示指定命令的授权信息。 | `sudo -l` 或 `sudo -l /usr/bin/apt-get` |
|
||||
| `-h, --help` | 显示 `sudo` 命令的帮助信息。 | `sudo -h` |
|
||||
| `-V, --version` | 显示 `sudo` 命令的版本信息。 | `sudo -V` |
|
||||
|
||||
### Newusers
|
||||
|
||||
`newusers` 是一个 Linux 系统命令,用于批量创建新的用户账号。
|
||||
|
||||
该命令可以从指定的文件中读取一组用户信息,每行包括用户名、密码、用户 ID、主组 ID、全名、主目录、默认 shell 等字段。`newusers` 会自动创建这些用户账号,并设置相应的密码、主目录和 shell。
|
||||
|
||||
```shell
|
||||
-------------------- user.txt --------------------
|
||||
user1:x:1001:1001:User One:/home/user1:/bin/bash
|
||||
user2:x:1002:1002:User Two:/home/user2:/bin/bash
|
||||
user3:x:1003:1003:User Three:/home/user3:/bin/bash
|
||||
--------------------------------------------------
|
||||
|
||||
# 读取 user.txt 批量创建用户
|
||||
newusers user.txt
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ---------------------- | -------------------------- | ------------------------------------------------------------ |
|
||||
| `-u, --uid` | 指定起始用户 ID | `newusers -u 1000 users.txt` |
|
||||
| `-g, --gid` | 指定起始组 ID | `newusers -g 1000 users.txt` |
|
||||
| `-c, --comment` | 指定用户的注释信息 | `newusers -c "User One" users.txt`, `newusers --comment "User One" users.txt` |
|
||||
| `-s, --shell` | 指定新用户的默认 shell | `newusers -s /bin/bash users.txt`, `newusers --shell /bin/bash users.txt` |
|
||||
| `-H, --no-create-home` | 禁止创建用户主目录 | `newusers -H users.txt`, `newusers --no-create-home users.txt` |
|
||||
| `-N, --no-user-group` | 禁止创建与用户名同名的主组 | `newusers -N users.txt`, `newusers --no-user-group users.txt` |
|
||||
|
||||
### Chpasswd
|
||||
|
||||
`chpasswd` 命令用于批量修改用户的密码,可以一次性修改多个用户的密码,而不需要逐个输入密码。它可以从标准输入、文件或命令行参数中读取用户密码信息,并将其应用于指定的用户账户。
|
||||
|
||||
```shell
|
||||
-------------------- users.txt --------------------
|
||||
user1:password1
|
||||
user2:password2
|
||||
--------------------------------------------------
|
||||
|
||||
# 将 user1 的密码修改为 password1
|
||||
echo 'user1:password1' | chpasswd
|
||||
|
||||
# 批量更新,使用 md5 加密方式
|
||||
sudo chpasswd -m < users.txt
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| -------------------- | -------------------------- | -------------------------------------------- |
|
||||
| `-e, --encrypted` | 指定密码已加密 | `chpasswd -e < users.txt` |
|
||||
| `-h, --help` | 显示帮助信息并退出 | `chpasswd --help` |
|
||||
| `-m, --md5` | 指定密码以 MD5 格式加密 | `chpasswd -m < users.txt` |
|
||||
| `-c, --crypt-method` | 指定密码加密方法 | `chpasswd --crypt-method SHA512 < users.txt` |
|
||||
| `-R, --root` | 以 root 权限运行命令 | `sudo chpasswd --root` |
|
||||
| `-u, --update` | 仅更新现有用户的密码 | `chpasswd -u < users.txt` |
|
||||
| `-I, --inactive` | 指定密码失效时间,单位为天 | `chpasswd --inactive 7 < users.txt` |
|
||||
|
||||
### pwck、grpck
|
||||
|
||||
`pwck` (Password Check)和 `grpck` (Group Check)命令是 Linux 系统中用于检查 `/etc/passwd`、`/etc/shadow` 和 `/etc/group` 等文件的格式和完整性的工具。这些命令可以帮助系统管理员查找和修复这些文件中的错误,以确保系统的安全性和稳定性。
|
||||
|
||||
- 用户配置文件:`/etc/passwd` 文件是 Linux 系统中存储用户信息的文件之一。该文件包含每个用户的用户名、用户 ID、主目录、登录 shell 等信息。
|
||||
|
||||
- 用户密码配置文件:`/etc/shadow` 文件是 Linux 系统中存储用户密码信息的文件之一。该文件包含每个用户的密码哈希值、最后一次更改密码的日期等信息。
|
||||
|
||||
- 用户组配置文件:`/etc/group` 文件是 Linux 系统中存储用户组信息的文件之一。该文件包含每个用户组的名称、组 ID 和组成员列表等信息。
|
||||
|
||||
- 用户组密码配置文件:`/etc/gshadow` 文件是 Linux 系统中存储用户组密码信息的文件之一。该文件包含每个用户组的密码哈希值、管理员列表和成员列表等信息。
|
||||
|
||||
- 默认配置文件:`/etc/login.defs` 文件是 Linux 系统中存储默认登录选项的文件之一。该文件包含默认的密码长度、最大尝试登录次数等信息。
|
||||
|
||||
- 配置文件:`/etc/adduser.conf` 文件是 Linux 系统中存储新用户默认配置选项的文件之一。该文件包含新用户的默认主目录、默认 shell 等信息。
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ---------------- | ------------------------ | --------------------------------------- |
|
||||
| `-r, --root DIR` | 指定要检查的根目录 | `pwck/grpck -r /mnt` |
|
||||
| `-s, --silent` | 安静模式,只输出错误信息 | `pwck/grpck -s /etc/passwd /etc/shadow` |
|
||||
| `-q, --quiet` | 安静模式,不输出信息 | `pwck/grpck -q /etc/passwd /etc/group` |
|
||||
| `-n, --nocheck` | 不检查用户主目录和组文件 | `pwck/grpck -n /etc/passwd /etc/shadow` |
|
||||
|
||||
### pwconv、pwunconv、grpconv、grpunconv
|
||||
|
||||
`pwconv`(Password Conversion)、`pwunconv`(Password unConversion)、`grpconv` (Group Conversion)和 `grpunconv`(Group unConversion) 命令是 Linux 系统中的用于转换密码文件和组文件格式的工具。这些工具可以帮助系统管理员将 `/etc/passwd`、`/etc/shadow` 和 `/etc/group` 等文件的格式转换为其他格式或者将已转换的文件恢复为原始格式。
|
||||
|
||||
这些工具的作用如下:
|
||||
|
||||
- `pwconv` 命令:将 `/etc/passwd` 和 `/etc/shadow` 文件的格式从标准格式(包括用户名、密码和 UID 等信息)转换为 shadow 格式(将密码单独存储在 `/etc/shadow` 文件中)。
|
||||
- `pwunconv` 命令:将 `/etc/passwd` 和 `/etc/shadow` 文件的格式从 shadow 格式转换为标准格式。
|
||||
- `grpconv` 命令:将 `/etc/group` 文件的格式从标准格式(包括组名、组密码和 GID 等信息)转换为 Gshadow 格式(将组密码单独存储在 `/etc/gshadow` 文件中)。
|
||||
- `grpunconv` 命令:将 `/etc/group` 文件的格式从 Gshadow 格式转换为标准格式。
|
||||
|
||||
这些工具的用途包括但不限于:
|
||||
|
||||
- 提高系统的安全性:使用 shadow 格式将用户密码单独存储在 `/etc/shadow` 文件中,可以防止未经授权的用户访问密码信息,提高系统的安全性。
|
||||
- 管理用户和组的身份验证:通过转换和恢复密码和组文件格式,可以更轻松地管理用户和组的身份验证信息,例如更改密码、添加或删除用户和组等操作。
|
||||
|
||||
## 其他
|
||||
|
||||
### W
|
||||
|
||||
`w` 命令在 Unix 和 Unix 类操作系统中用于显示有关系统活动的信息。这个命令可以显示当前系统中登录的用户、他们所做的事情、从哪里登录、他们登录的时间以及系统负载等。
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# w
|
||||
14:16:51 up 22:16, 2 users, load average: 0.00, 0.00, 0.00
|
||||
USER TTY 来自 LOGIN@ IDLE JCPU PCPU WHAT
|
||||
sevenwat tty1 - 二16 22:15m 0.16s 0.05s -bash
|
||||
sevenwat pts/0 172.17.0.100 13:55 0.00s 0.51s 0.13s sshd: sevenwate [priv]
|
||||
```
|
||||
|
||||
### Id
|
||||
|
||||
`id` 命令用于显示用户和用户组的标识信息。它可以用于查看当前用户或指定用户的 UID(用户标识符)、GID(组标识符)和所属用户组的名称。
|
||||
|
||||
```shell
|
||||
sevenwate@LinuxTest:~$ id
|
||||
用户id=1000(sevenwate) 组id=1000(sevenwate) 组=1000(sevenwate),24(cdrom),25(floppy),27(sudo),29(audio),30(dip),44(video),46(plugdev),108(netdev),1001(grpdemo)
|
||||
```
|
||||
|
||||
### Whoami
|
||||
|
||||
`whoami` 命令用于显示当前登录用户的用户名。它是一个非常简单的命令,通常用于 shell 脚本和命令行中,以便在需要当前用户的用户名时快速获取它。
|
||||
|
||||
```shell
|
||||
sevenwate@LinuxTest:~$ whoami
|
||||
sevenwate
|
||||
```
|
||||
|
||||
### Last
|
||||
|
||||
`last` 命令在 Linux 中用于显示系统的登录记录。这个命令列出了系统登录和启动的详细信息,如登录用户、登录的 IP 地址、登录时间以及登录持续的时间。
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# last
|
||||
sevenwat pts/0 172.17.0.100 Wed May 31 13:55 still logged in
|
||||
sevenwat pts/1 172.17.0.100 Wed May 31 11:07 - 11:21 (00:14)
|
||||
sevenwat pts/0 172.17.0.100 Wed May 31 11:07 - 13:00 (01:53)
|
||||
sevenwat pts/0 172.17.0.100 Wed May 31 10:55 - 11:04 (00:09)
|
||||
sevenwat pts/0 172.17.0.100 Wed May 31 10:49 - 10:51 (00:02)
|
||||
sevenwat pts/0 172.17.0.100 Tue May 30 17:03 - 17:35 (00:32)
|
||||
sevenwat pts/0 172.17.0.100 Tue May 30 16:03 - 16:53 (00:50)
|
||||
sevenwat pts/2 172.17.0.100 Tue May 30 16:02 - 16:02 (00:00)
|
||||
sevenwat pts/1 172.17.0.100 Tue May 30 16:02 - 16:02 (00:00)
|
||||
sevenwat pts/0 172.17.0.100 Tue May 30 16:02 - 16:02 (00:00)
|
||||
sevenwat tty1 Tue May 30 16:01 still logged in
|
||||
reboot system boot 5.10.0-23-amd64 Tue May 30 16:00 still running
|
||||
|
||||
wtmp begins Tue May 30 16:00:47 2023
|
||||
```
|
||||
|
||||
### Lastlog
|
||||
|
||||
`lastlog` 命令用于查看所有用户最后一次登录的时间和登录的终端。这个命令检查 `/var/log/lastlog` 文件以确定每个用户的最后一次登录信息。此命令的输出包含用户名、最后登录的端口和最后登录的时间。
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# lastlog
|
||||
用户名 端口 来自 最后登录时间
|
||||
root **从未登录过**
|
||||
……
|
||||
sevenwate pts/0 172.17.0.100 三 5月 31 13:55:15 +0800 2023
|
||||
newuser **从未登录过**
|
||||
```
|
||||
|
||||
## 实例
|
||||
|
||||
```mermaid
|
||||
graph LR
|
||||
SwitchToRoot[切换到 root 用户]
|
||||
SwitchToRoot --> CreateUser[创建新用户]
|
||||
CreateUser --> SetPassword[设置新用户的密码]
|
||||
SetPassword --> ChangeUserInfo{更新新用户信息?}
|
||||
ChangeUserInfo -- Yes --> RunChfn[chfn]
|
||||
ChangeUserInfo -- No --> AssignHomeDir{指定用户目录?}
|
||||
RunChfn --> AssignHomeDir
|
||||
AssignHomeDir -- Yes --> RunUseraddWithD[useradd -d]
|
||||
AssignHomeDir -- No --> SetLoginShell{指定登录 shell?}
|
||||
RunUseraddWithD --> SetLoginShell
|
||||
SetLoginShell -- Yes --> RunUseraddWithS[useradd -s]
|
||||
SetLoginShell -- No --> AddToExtraGroups{添加到额外的组?}
|
||||
RunUseraddWithS --> AddToExtraGroups
|
||||
AddToExtraGroups -- Yes --> RunUsermod[usermod -aG]
|
||||
AddToExtraGroups -- No --> End(结束)
|
||||
RunUsermod --> End
|
||||
```
|
||||
|
||||
1. **打开终端**:快捷键 Ctrl+Alt+T 打开终端。
|
||||
2. **切换到 root 用户**:使用 `su -` 命令切换到 root 用户。
|
||||
3. **使用 useradd 命令创建新用户**:使用 `useradd` 命令和新用户的用户名来创建新用户。例如创建一个名为 `newuser` 的新用户:
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# useradd newuser
|
||||
```
|
||||
|
||||
1. **设置新用户的密码**:使用 `passwd` 命令和新用户的用户名来设置密码。
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# passwd newuser
|
||||
新的 密码:
|
||||
重新输入新的 密码:
|
||||
passwd:已成功更新密码
|
||||
```
|
||||
|
||||
1. **更改新用户的信息**(可选):可以使用 `chfn` 命令更改新用户的全名、房间号、工作电话和家庭电话。
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# chfn newuser
|
||||
正在改变 newuser 的用户信息
|
||||
请输入新值,或直接敲回车键以使用默认值
|
||||
全名 []: newuser
|
||||
房间号码 []: 888
|
||||
工作电话 []: 18688888888
|
||||
家庭电话 []: 0371
|
||||
其它 []:
|
||||
```
|
||||
|
||||
1. **给新用户分配家目录**(可选):默认情况下 `useradd` 命令会为新用户创建一个在 `/home` 下的家目录。`usermod` 可以使用 `-d` 选项为新用户指定一个不同的家目录。例如,指定 `newuser` 的家目录是 `/opt/newuser`:
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# usermod -d /opt/newuser -m newuser
|
||||
```
|
||||
|
||||
1. **指定不同的登录 shell**(可选):`usermod` 可以使用 `-s` 选项指定一个不同的登录 shell。例如为 `newuser` 指定 `/bin/sbin/noligin` 作为登录 shell,你可以运行:
|
||||
|
||||
```shell
|
||||
# 使用 usermod 命令
|
||||
root@LinuxTest:~# usermod -s /usr/bin/nologin newuser
|
||||
# 使用 chsh 命令
|
||||
root@LinuxTest:~# chsh -s /bin/bash newuser
|
||||
```
|
||||
|
||||
1. **将新用户添加到一个或多个额外的组**(可选):可以使用 `usermod` 命令的 `-G` 选项将新用户添加到一个或多个额外的组。例如将 `newuser` 添加到 `sudo` 和 `users` 组,你可以运行:
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# usermod -aG sudo,users newuser
|
||||
root@LinuxTest:~# id newuser
|
||||
用户id=1003(newuser) 组id=1003(newuser) 组=1003(newuser),27(sudo),100(users)
|
||||
# 用户最终信息
|
||||
root@LinuxTest:~# cat /etc/passwd | grep newuser
|
||||
newuser:x:1003:1003:newuser,888-1,18688888888,0371-88888888:/opt/newuser2:/usr/bin/nologin
|
||||
```
|
||||
@ -1,6 +1,6 @@
|
||||
---
|
||||
title: Linux 下源代码编译与安装实战指南
|
||||
description: Linux 下源代码编译与安装实战指南
|
||||
title: Linux 下源代码编译与安装实战
|
||||
description: Linux 下源代码编译与安装实战
|
||||
keywords:
|
||||
- Linux
|
||||
- 源代码编译
|
||||
727
Tech/operating-system/Linux/3.基础操作/Linux 用户和权限.md
Normal file
727
Tech/operating-system/Linux/3.基础操作/Linux 用户和权限.md
Normal file
@ -0,0 +1,727 @@
|
||||
---
|
||||
title: Linux 用户和权限
|
||||
description: Linux 用户和权限
|
||||
keywords:
|
||||
- Linux
|
||||
- 用户
|
||||
- 权限
|
||||
tags:
|
||||
- Linux/基础
|
||||
- 技术/操作系统
|
||||
author: 7Wate
|
||||
date: 2023-03-30
|
||||
---
|
||||
|
||||
## 概述
|
||||
|
||||
Linux 多用户系统的历史可以追溯到 1960 年代的 Unix 系统,Unix 是一种多用户、多任务的操作系统,被广泛应用于大型计算机和服务器上。随着 Linux 的发展,它也成为了一种强大的多用户操作系统,并被广泛应用于服务器、个人电脑和移动设备等领域。
|
||||
|
||||
### 设计原则
|
||||
|
||||
Linux 多用户系统的设计基于以下原则:
|
||||
|
||||
- **唯一用户标识符(UID)**:每个用户都有一个唯一的标识符,用于标识其身份。
|
||||
- **用户组标识符(GID)**:每个用户可以分配到一个或多个用户组,用户组也有一个唯一的标识符。
|
||||
- **所有者和用户组**:每个文件和目录都有一个所有者和一个所属用户组,用于控制访问权限。
|
||||
- **主目录(Home Directory)**:每个用户都有一个主目录,用于存储其个人文件和设置。
|
||||
- **系统管理员权限**:系统管理员可以创建、删除和管理用户和用户组,以及控制用户的权限和访问权限。
|
||||
|
||||
### 实现机制
|
||||
|
||||
Linux 多用户系统的实现基于以下机制:
|
||||
|
||||
- **配置文件**:用户和用户组的信息存储在特定的配置文件中,如 `/etc/passwd`、`/etc/shadow`、`/etc/group` 和 `/etc/gshadow`。
|
||||
- **身份验证**:用户登录时需要进行身份验证,通常使用用户名和密码进行认证。
|
||||
- **管理工具**:系统管理员可以使用命令行工具或图形界面来创建、删除和管理用户和用户组,以及配置用户的权限和访问权限。
|
||||
- **安全机制**:Linux 系统提供了许多安全机制,如访问控制列表(ACL)、文件系统权限和 SELinux,用于保护系统和用户的数据安全。
|
||||
|
||||
### 权限管理
|
||||
|
||||
在 Linux 系统中,文件和目录的权限由三个组件组成:所有者权限、所属组权限和其他用户权限。每个组件可以设置为读取(r)、写入(w)和执行(x)权限,这些权限可以用数字表示(r=4, w=2, x=1)。
|
||||
|
||||
### 用户和权限的配置文件
|
||||
|
||||
以下是存储用户和权限信息的主要配置文件:
|
||||
|
||||
- **/etc/passwd**:存储用户账户信息。
|
||||
- **/etc/shadow**:存储用户密码信息,包含加密的密码和其他安全信息。
|
||||
- **/etc/group**:存储用户组信息。
|
||||
- **/etc/gshadow**:存储用户组密码信息。
|
||||
- **/etc/login.defs**:定义系统登录的默认配置。
|
||||
- **/etc/adduser.conf**:定义添加用户时的默认配置。
|
||||
|
||||
### 安全性建议
|
||||
|
||||
在使用 root 用户时,应注意系统的安全性,**尽量使用 `sudo` 或 `su` 命令以普通用户身份执行命令,以减少误操作对系统的影响。**
|
||||
|
||||
## 用户
|
||||
|
||||
### 创建
|
||||
|
||||
#### Useradd
|
||||
|
||||
`useradd` 命令是 Linux 系统中的一个命令行工具,用于创建新用户帐户。通过 `useradd` 命令,可以指定新用户的用户名、用户 ID(UID)、主目录、默认 shell 和密码等信息。
|
||||
|
||||
在大多数 Linux 系统中,只有管理员用户(如 root 用户)可以创建新用户。通常情况下,管理员用户需要使用 `sudo` 命令或以 root 用户身份登录系统,才能使用 `useradd` 命令创建新用户。
|
||||
|
||||
```shell
|
||||
# 创建一个新用户
|
||||
sudo useradd john
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ------------------------------ | --------------------------------------------------- | -------------------------------------- |
|
||||
| `-c, --comment COMMENT` | 指定用户的注释字段。 | `sudo useradd -c "John Smith" john` |
|
||||
| `-d, --home-dir HOME_DIR` | 指定用户的家目录。 | `sudo useradd -d /home/john john` |
|
||||
| `-e, --expiredate EXPIRE_DATE` | 指定用户的账户过期日期。 | `sudo useradd -e 2023-06-30 john` |
|
||||
| `-f, --inactive INACTIVE` | 设置密码过期后的不活动期限为 INACTIVE,以禁用账户。 | `sudo useradd -f 30 john` |
|
||||
| `-g, --gid GROUP` | 指定用户的主用户组。 | `sudo useradd -g staff john` |
|
||||
| `-G, --groups GROUPS` | 指定用户所属的其他用户组。 | `sudo useradd -G staff,developer john` |
|
||||
| `-m, --create-home` | 创建用户的家目录。 | `sudo useradd -m john` |
|
||||
| `-p, --password PASSWORD` | 指定用户的加密密码。 | `sudo useradd -p password_hash john` |
|
||||
| `-s, --shell SHELL` | 指定用户的默认 shell。 | `sudo useradd -s /bin/bash john` |
|
||||
| `-u, --uid UID` | 指定用户的 UID。 | `sudo useradd -u 1001 john` |
|
||||
|
||||
#### Adduser
|
||||
|
||||
**`adduser` 命令是 Linux 系统中的一个高层次的用户添加工具,它提供了比 `useradd` 更加用户友好的界面和交互过程。**`adduser` 通常作为一个 Perl 脚本,封装了 `useradd` 命令,并在用户创建过程中进行一些附加的配置工作,如创建主目录、复制模板文件、设置密码等。
|
||||
|
||||
- **配置文件**:`adduser` 命令的默认配置文件为 `/etc/adduser.conf`,可以在此文件中修改默认设置,如主目录、用户组等。
|
||||
- **密码设置**:`adduser` 默认会在用户创建过程中提示输入密码。如果使用 `--disabled-password` 选项,则不会设置密码,需要在用户创建后使用 `passwd` 命令单独设置。
|
||||
- **与 `useradd` 的兼容性**:虽然 `adduser` 提供了更友好的用户创建界面,但它并不是所有发行版都默认包含的命令。某些轻量级发行版可能只提供 `useradd`。
|
||||
|
||||
```shell
|
||||
# 创建一个新用户
|
||||
sudo adduser john
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ----------------------- | ---------------------------- | -------------------------------------------------- |
|
||||
| `--home HOME_DIR` | 指定用户的家目录。 | `sudo adduser --home /home/john john` |
|
||||
| `--shell SHELL` | 指定用户的默认 shell。 | `sudo adduser --shell /bin/bash john` |
|
||||
| `--uid UID` | 指定用户的 UID。 | `sudo adduser --uid 1001 john` |
|
||||
| `--gid GID` | 指定用户的 GID。 | `sudo adduser --gid 100 john` |
|
||||
| `--disabled-password` | 创建用户但不设置密码。 | `sudo adduser --disabled-password john` |
|
||||
| `--disabled-login` | 创建用户但禁止登录。 | `sudo adduser --disabled-login john` |
|
||||
| `--gecos GECOS` | 提供用户的 GECOS 信息。 | `sudo adduser --gecos "John Smith,,," john` |
|
||||
| `--no-create-home` | 不创建用户的家目录。 | `sudo adduser --no-create-home john` |
|
||||
| `--ingroup GROUP` | 将用户添加到指定的主用户组。 | `sudo adduser --ingroup staff john` |
|
||||
| `--extra-groups GROUPS` | 将用户添加到附加用户组。 | `sudo adduser --extra-groups staff,developer john` |
|
||||
|
||||
**`adduser` 与 `useradd` 的区别:**
|
||||
|
||||
- **交互式**:`adduser` 提供了交互式的用户创建过程,向导会提示输入用户名、密码、GECOS 信息(如全名、电话等)。
|
||||
- **默认设置**:`adduser` 使用系统默认配置文件(如 `/etc/adduser.conf`)来设定新用户的默认值,例如主目录位置、用户组等。
|
||||
- **附加任务**:`adduser` 会自动完成一些附加任务,如创建用户主目录、复制 `/etc/skel` 目录中的模板文件到新用户主目录等。
|
||||
|
||||
### 管理
|
||||
|
||||
#### Chfn
|
||||
|
||||
`chfn` (change finger information)命令用于更改用户的 GECOS 信息。GECOS 字段包含用户的全名、办公地址、办公电话和家庭电话等信息。通常,这些信息存储在 `/etc/passwd` 文件中
|
||||
|
||||
```shell
|
||||
# 更改当前用户信息
|
||||
debian@SevenWate-PC:$ chfn
|
||||
Password:
|
||||
Changing the user information for debian
|
||||
Enter the new value, or press ENTER for the default
|
||||
Full Name:
|
||||
Room Number []:
|
||||
Work Phone []:
|
||||
Home Phone []:
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ------------------------ | ------------------------------------------------------------ | -------------------------------- |
|
||||
| `-f, --full-name NAME` | 更改用户的全名。 | `chfn -f "John Smith"` |
|
||||
| `-r, --room ROOM` | 更改用户的办公地址。 | `chfn -r "Room 123"` |
|
||||
| `-w, --work-phone PHONE` | 更改用户的办公电话。 | `chfn -w "555-1234"` |
|
||||
| `-h, --home-phone PHONE` | 更改用户的家庭电话。 | `chfn -h "555-5678"` |
|
||||
| `-o, --other OTHER` | 更改用户的其他信息。 | `chfn -o "Other Info"` |
|
||||
| `-u, --username USER` | 指定要更改 GECOS 信息的用户名(仅 root 用户可以使用该选项)。 | `sudo chfn -f "John Smith" john` |
|
||||
| `-q, --quiet` | 安静模式,不输出任何信息。 | `chfn -q` |
|
||||
| `-v, --verbose` | 显示详细信息。 | `chfn -v` |
|
||||
|
||||
#### Chsh
|
||||
|
||||
`chsh` (change shell)命令用于更改用户的默认登录 shell。通过 `chsh` 命令,用户可以选择不同的 shell 来作为他们的登录环境。在 Linux 系统中,常见的 shell 有 `bash`、`zsh`、`ksh`、`csh` 等。
|
||||
|
||||
```shell
|
||||
# 查看当前系统 shell
|
||||
cat /etc/shells
|
||||
|
||||
# 更改当前用户的默认 shell
|
||||
chsh -s /bin/bash
|
||||
|
||||
# 更改其他用户的默认 shell
|
||||
chsh -s /bin/bash john
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| --------------------- | ----------------------------------------------------- | ---------------------------- |
|
||||
| `-s, --shell SHELL` | 指定新的登录 shell。 | `chsh -s /bin/zsh` |
|
||||
| `-l, --list-shells` | 列出系统中可用的 shell。 | `chsh -l` |
|
||||
| `-u, --username USER` | 指定要更改 shell 的用户。仅 root 用户可以使用该选项。 | `sudo chsh -s /bin/zsh john` |
|
||||
| `-h, --help` | 显示帮助信息。 | `chsh -h` |
|
||||
|
||||
| Shell | 描述 | 主要特性 | 适用场景 |
|
||||
| ----------- | ------------------------------------------------------ | ------------------------------------------------ | -------------------------------------------- |
|
||||
| `sh` | Bourne Shell,最早的 UNIX Shell。 | 基本命令解释器,轻量,标准 UNIX Shell | 传统 UNIX 系统,基础脚本编写 |
|
||||
| `bash` | Bourne Again Shell,最常用的 Shell,向后兼容 `sh`。 | 强大的脚本功能,命令行编辑,历史记录,命令补全 | 日常使用,脚本编写,系统管理员使用 |
|
||||
| `csh` | C Shell,语法类似 C 语言。 | C 语言风格语法,别名,历史记录 | 喜欢 C 语言语法的用户,脚本编写 |
|
||||
| `tcsh` | `csh` 的改进版本,增加了一些用户友好功能。 | 增强的命令行编辑,命令补全,语法高亮 | 改进的 C Shell 用户,交互式使用 |
|
||||
| `ksh` | Korn Shell,结合了 `sh` 和 `csh` 的优点。 | 丰富的编程特性,数组处理,命令行编辑 | 高级脚本编写,系统管理员使用 |
|
||||
| `zsh` | Z Shell,功能强大且灵活,支持许多高级特性。 | 强大的命令补全,插件系统,主题支持,多行命令编辑 | 高级用户,脚本编写,开发人员 |
|
||||
| `fish` | Friendly Interactive Shell,用户友好的 Shell。 | 人性化提示,智能命令补全,颜色高亮,简易配置 | 新手用户,日常使用,用户友好环境 |
|
||||
| `dash` | Debian Almquist Shell,轻量级的 `sh` 实现。 | 轻量快速,标准兼容,资源占用低 | 系统启动脚本,嵌入式系统,资源受限环境 |
|
||||
| `ash` | Almquist Shell,另一个轻量级的 `sh` 实现。 | 轻量快速,标准兼容,资源占用低 | 嵌入式系统,资源受限环境,轻量级需求 |
|
||||
| `rbash` | Restricted Bash,限制版的 `bash`。 | 限制用户执行某些命令,增强安全性 | 受限用户环境,安全要求高的场景 |
|
||||
| `scponly` | 限制用户只能使用 `scp` 命令。 | 限制用户只进行 SCP 操作,增强安全性 | 安全文件传输环境,受限用户访问 |
|
||||
| `nologin` | 禁止用户登录 Shell,但允许 FTP 等非交互式服务。 | 禁止交互登录,显示消息,安全性控制 | 禁止交互登录的用户,提供非交互服务 |
|
||||
| `git-shell` | 专为 Git 用户设计的 Shell,限制用户只能执行 Git 命令。 | 限制用户只能使用 Git 命令,增强代码管理安全性 | Git 服务器环境,限制用户操作,代码管理服务器 |
|
||||
|
||||
#### Chage
|
||||
|
||||
`chage` (change age)命令用于更改用户密码的有效期和过期信息。系统管理员可以通过 `chage` 命令来设置用户密码的到期时间、警告时间和账户失效时间等,从而增强系统的安全性。
|
||||
|
||||
```shell
|
||||
# 查看用户密码信息
|
||||
sudo chage -l john
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ------------------------------ | ------------------------------------------------------------ | ------------------------------- |
|
||||
| `-d, --lastday LAST_DAY` | 设置用户密码最后一次更改的日期。日期格式为 YYYY-MM-DD。 | `sudo chage -d 2024-08-05 john` |
|
||||
| `-E, --expiredate EXPIRE_DATE` | 设置账户过期日期。日期格式为 YYYY-MM-DD。 | `sudo chage -E 2024-12-31 john` |
|
||||
| `-I, --inactive INACTIVE` | 设置密码过期后多少天账户变为不活跃状态。 | `sudo chage -I 30 john` |
|
||||
| `-m, --mindays MIN_DAYS` | 设置密码的最短使用期限(两次修改密码之间最少要间隔的天数)。 | `sudo chage -m 7 john` |
|
||||
| `-M, --maxdays MAX_DAYS` | 设置密码的最长使用期限(密码过期前的最大天数)。 | `sudo chage -M 90 john` |
|
||||
| `-W, --warndays WARN_DAYS` | 设置密码过期前警告用户的天数。 | `sudo chage -W 7 john` |
|
||||
| `-l, --list` | 显示用户密码和账户的过期信息。 | `sudo chage -l john` |
|
||||
| `-h, --help` | 显示帮助信息。 | `chage -h` |
|
||||
|
||||
*日期格式应为 YYYY-MM-DD,如果不指定具体日期,可以使用 `-1` 表示永不过期。*
|
||||
|
||||
#### Passwd
|
||||
|
||||
`passwd` (password)命令是 Linux 系统中的一个命令行工具,用于更改用户的密码或口令。默认情况下,每个 Linux 用户都有一个口令或密码来保护其账户的安全性。`passwd` 命令可用于更改密码或口令。
|
||||
|
||||
```shell
|
||||
# 更改当前用户的
|
||||
passwd
|
||||
|
||||
# 更改其他用户的密码
|
||||
passwd john
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| -------------------------- | -------------------------------------------------- | ------------------------ |
|
||||
| `-d, --delete` | 删除用户的密码,使账户不需要密码即可登录。 | `sudo passwd -d john` |
|
||||
| `-e, --expire` | 使用户密码立即过期,强制用户在下次登录时更改密码。 | `sudo passwd -e john` |
|
||||
| `-i, --inactive INACTIVE` | 设置密码过期后账户被禁用前的天数。 | `sudo passwd -i 30 john` |
|
||||
| `-k, --keep-tokens` | 仅更新有效期信息而不更改密码。 | `sudo passwd -k john` |
|
||||
| `-l, --lock` | 锁定用户密码,禁用账户。 | `sudo passwd -l john` |
|
||||
| `-S, --status` | 显示账户的密码状态信息。 | `sudo passwd -S john` |
|
||||
| `-u, --unlock` | 解锁用户密码,启用账户。 | `sudo passwd -u john` |
|
||||
| `-x, --maxdays MAX_DAYS` | 设置密码的最大使用期限(天)。 | `sudo passwd -x 90 john` |
|
||||
| `-n, --mindays MIN_DAYS` | 设置密码的最小使用期限(天)。 | `sudo passwd -n 7 john` |
|
||||
| `-w, --warndays WARN_DAYS` | 设置密码过期前的警告天数。 | `sudo passwd -w 7 john` |
|
||||
| `-q, --quiet` | 安静模式,不输出任何信息。 | `passwd -q` |
|
||||
|
||||
#### Usermod
|
||||
|
||||
`usermod`(user modify)命令是 Linux 系统中的一个命令行工具,用于修改用户的属性或配置。`usermod` 命令允许您更改现有用户的用户名、UID、主目录、默认 shell 等信息,还可以将用户添加到其他用户组中。
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ------------------------------ | ------------------------------------------------------------ | --------------------------------------- |
|
||||
| `-c, --comment COMMENT` | 修改用户的注释字段。 | `sudo usermod -c "John Smith" john` |
|
||||
| `-d, --home HOME_DIR` | 修改用户的主目录,并将目录内容移至新位置(使用 `-m` 选项)。 | `sudo usermod -d /home/newjohn -m john` |
|
||||
| `-e, --expiredate EXPIRE_DATE` | 设置用户帐户的过期日期。 | `sudo usermod -e 2024-12-31 john` |
|
||||
| `-f, --inactive INACTIVE` | 设置密码过期后多少天账户变为不活跃状态。 | `sudo usermod -f 30 john` |
|
||||
| `-g, --gid GROUP` | 修改用户的主用户组。 | `sudo usermod -g staff john` |
|
||||
| `-G, --groups GROUPS` | 修改用户所属的附加组。 | `sudo usermod -G staff,developer john` |
|
||||
| `-a, --append` | 将用户添加到附加组(与 `-G` 选项一起使用)。 | `sudo usermod -a -G sudo john` |
|
||||
| `-l, --login NEW_LOGIN` | 修改用户的登录名。 | `sudo usermod -l newjohn john` |
|
||||
| `-L, --lock` | 锁定用户密码,禁用账户。 | `sudo usermod -L john` |
|
||||
| `-U, --unlock` | 解锁用户密码,启用账户。 | `sudo usermod -U john` |
|
||||
| `-s, --shell SHELL` | 修改用户的登录 shell。 | `sudo usermod -s /bin/zsh john` |
|
||||
| `-u, --uid UID` | 修改用户的用户 ID(UID)。 | `sudo usermod -u 1001 john` |
|
||||
| `-p, --password PASSWORD` | 修改用户的加密密码。 | `sudo usermod -p password_hash john` |
|
||||
| `-m, --move-home` | 将用户的主目录内容移动到新位置(与 `-d` 选项一起使用)。 | `sudo usermod -d /home/newjohn -m john` |
|
||||
| `-o, --non-unique` | 允许分配重复的 UID(与 `-u` 选项一起使用)。 | `sudo usermod -o -u 1001 john` |
|
||||
|
||||
### 删除
|
||||
|
||||
#### Userdel
|
||||
|
||||
`userdel`(User Delete)命令是 Linux 系统中的一个命令行工具,用于删除现有用户帐户。默认情况下,`userdel` 命令仅删除用户的帐户,而不删除用户的主目录和邮件箱。如果需要删除用户的主目录和邮件箱,可以使用 `-r` 选项。
|
||||
|
||||
- **删除用户前的检查**:在删除用户之前,应检查用户是否拥有任何正在运行的进程,并终止这些进程。可以使用 `ps -u username` 命令查看用户的进程。
|
||||
- **备份重要数据**:在删除用户及其主目录之前,建议备份用户的重要数据,以防止数据丢失。
|
||||
- **SELinux 用户映射**:如果系统启用了 SELinux,并且为用户分配了 SELinux 用户映射,可以使用 `-Z` 选项删除该映射。
|
||||
- **删除用户后**:删除用户后,应检查并清理与该用户相关的任何残留文件或配置,以确保系统的一致性和安全性。
|
||||
|
||||
```shell
|
||||
# 删除一个用户
|
||||
sudo userdel john
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| -------------------- | ---------------------------------------- | ---------------------- |
|
||||
| `-f, --force` | 强制删除用户账户,即使用户当前正在登录。 | `sudo userdel -f john` |
|
||||
| `-r, --remove` | 删除用户的主目录及其邮件池。 | `sudo userdel -r john` |
|
||||
| `-Z, --selinux-user` | 删除用户的 SELinux 用户映射。 | `sudo userdel -Z john` |
|
||||
|
||||
## 用户组
|
||||
|
||||
### 创建
|
||||
|
||||
#### Groupadd
|
||||
|
||||
`groupadd` 命令是 Linux 系统中的一个命令行工具,用于创建新的用户组。管理员用户(如 root 用户)可以使用 `groupadd` 命令创建新组。
|
||||
|
||||
```shell
|
||||
# 创建一个新组
|
||||
sudo groupadd newgroup
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| --------------------- | -------------------------------------------------------- | ------------------------------------------ |
|
||||
| `-f, --force` | 强制操作,如果组已存在则不报错。如果组不存在则创建新组。 | `sudo groupadd -f developers` |
|
||||
| `-g, --gid GID` | 指定新组的组 ID。 | `sudo groupadd -g 1001 developers` |
|
||||
| `-K, --key KEY=VALUE` | 覆盖 `/etc/login.defs` 文件中的设置。 | `sudo groupadd -K GID_MIN=1000 developers` |
|
||||
| `-o, --non-unique` | 允许创建具有重复 GID 的组。 | `sudo groupadd -o -g 1001 developers` |
|
||||
| `-r, --system` | 创建一个系统组。 | `sudo groupadd -r sysgroup` |
|
||||
|
||||
### 管理
|
||||
|
||||
#### Groups
|
||||
|
||||
`groups` 命令是 Linux 系统中的一个命令行工具,用于显示当前用户所属的用户组。如果没有指定用户名,则 `groups` 命令将显示当前用户所属的用户组。
|
||||
|
||||
```shell
|
||||
# 显示当前用户所属的用户组
|
||||
groups
|
||||
|
||||
# 显示指定用户所属的用户组
|
||||
groups john
|
||||
```
|
||||
|
||||
#### Gpasswd
|
||||
|
||||
`gpasswd` (group password)命令是 Linux 系统中的一个命令行工具,用于管理用户组的密码和成员列表。管理员用户(如 root 用户)可以使用 `gpasswd` 命令来添加或删除用户组的成员,或者设置或删除用户组的密码。
|
||||
|
||||
```shell
|
||||
# 设置组密码
|
||||
sudo gpasswd newgroup
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ------------------------------- | ------------------------------------------------ | ------------------------------------------ |
|
||||
| `-a, --add user` | 将用户添加到组中。 | `sudo gpasswd -a john developers` |
|
||||
| `-d, --delete user` | 从组中删除用户。 | `sudo gpasswd -d john developers` |
|
||||
| `-r, --remove` | 删除组密码。 | `sudo gpasswd -r developers` |
|
||||
| `-R, --restrict` | 禁用组密码,只有组管理员可以使用 `newgrp` 命令。 | `sudo gpasswd -R developers` |
|
||||
| `-A, --administrators user,...` | 设置组管理员。 | `sudo gpasswd -A admin1,admin2 developers` |
|
||||
| `-M, --members user,...` | 设置组成员,覆盖现有成员。 | `sudo gpasswd -M john,doe developers` |
|
||||
|
||||
#### Groupmod
|
||||
|
||||
`groupmod` (group modify)命令是 Linux 系统中的一个命令行工具,用于修改已有用户组的属性,例如组 ID、组名称和组密码等。管理员用户(如 root 用户)可以使用 `groupmod` 命令来更改用户组的属性。
|
||||
|
||||
```shell
|
||||
# 修改组名
|
||||
sudo groupmod -n newname oldname
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| -------------------------- | ---------------------------- | -------------------------------------- |
|
||||
| `-g, --gid GID` | 将组的 GID 设置为指定的值。 | `sudo groupmod -g 1001 newgroup` |
|
||||
| `-n, --new-name NEW_GROUP` | 将组的名称更改为指定的名称。 | `sudo groupmod -n newgroup2 newgroup` |
|
||||
| `-o, --non-unique` | 允许使用非唯一 GID 创建组。 | `sudo groupmod -o newgroup` |
|
||||
| `-p, --password PASSWORD` | 将组密码设置为指定的密码。 | `sudo groupmod -p mypassword newgroup` |
|
||||
|
||||
### 删除
|
||||
|
||||
#### Groupdel
|
||||
|
||||
`groupdel` (group delete)是 Linux 系统中的一个命令行工具,用于删除一个用户组。删除用户组时,系统会自动将该组的所有成员从该组中删除,并将文件和目录中的组 ID 更改为其他组。
|
||||
|
||||
```shell
|
||||
# 删除一个用户组
|
||||
sudo groupdel newgroup
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ----------------------- | ---------------------------------- | -------------------------------------------- |
|
||||
| `-f, --force` | 强制删除用户组,即使该组仍有成员。 | `sudo groupdel -f newgroup` |
|
||||
| `-h, --help` | 显示命令帮助信息。 | `groupdel -h` |
|
||||
| `-R, --root CHROOT_DIR` | 在指定的 chroot 环境中运行命令。 | `sudo groupdel --root /mnt/newroot newgroup` |
|
||||
| `-v, --verbose` | 显示命令详细输出。 | `sudo groupdel -v newgroup` |
|
||||
|
||||
## Root 超级用户
|
||||
|
||||
在 Linux 系统中,root 是超级用户,具有完全的系统管理权限。root 用户可以执行任何命令,并访问系统中的所有文件和资源。在默认情况下,root 用户的密码是空的,因此在安全性方面需要额外注意。
|
||||
|
||||
### Su
|
||||
|
||||
`su`(switch user)命令是 Linux 系统中的一个命令行工具,它允许您在不注销当前用户的情况下切换到其他用户帐户。默认情况下,`su` 命令切换到超级用户帐户(root)。
|
||||
|
||||
- **使用 `sudo` 代替 `su`**:在许多现代系统中,推荐使用 `sudo` 命令来代替 `su`,以提供更细粒度的权限控制和审计功能。
|
||||
- **登录环境**:使用 `-l` 或 `-` 选项时,`su` 命令会模拟用户完整的登录过程,包括加载用户的 shell 配置文件(如 `.bash_profile`、`.profile` 等)。
|
||||
- **环境变量**:默认情况下,`su` 命令会重置环境变量,以匹配目标用户的环境。使用 `-m` 或 `-p` 选项可以保留当前的环境变量。
|
||||
- **权限要求**:切换到其他用户身份通常需要输入目标用户的密码。切换到 root 用户身份需要输入 root 用户的密码。
|
||||
- **安全性**:尽量使用 `su` 命令时指定 `-` 选项,以确保切换到目标用户的完整环境,减少潜在的权限问题。
|
||||
|
||||
```shell
|
||||
# 默认切换 root
|
||||
su
|
||||
|
||||
# 切换到 debian
|
||||
su debian
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ---------------------------- | --------------------------------------------- | ---------------------- |
|
||||
| `-` | 切换到目标用户的登录环境,相当于 `-l` 选项。 | `su -` |
|
||||
| `-l, --login` | 切换到目标用户的登录环境。 | `su -l john` |
|
||||
| `-c, --command COMMAND` | 执行指定的命令,然后退出。 | `su -c 'ls /root'` |
|
||||
| `-s, --shell SHELL` | 使用指定的 shell 而不是目标用户的默认 shell。 | `su -s /bin/bash john` |
|
||||
| `-m, --preserve-environment` | 保留当前环境变量而不是重置它们。 | `su -m john` |
|
||||
| `-p` | 保留当前环境变量(等同于 `-m` 选项)。 | `su -p john` |
|
||||
| `-h, --help` | 显示帮助信息。 | `su -h` |
|
||||
| `-v, --version` | 显示版本信息。 | `su -v` |
|
||||
|
||||
### Sudo
|
||||
|
||||
在 Unix 和类 Unix 系统中,`sudo` 是一个强大的工具,允许普通用户以超级用户(root)的权限来执行特定的命令或访问受限资源。`sudo` 命令的行为由一个配置文件定义,这个文件通常称为 `sudoers` 文件。
|
||||
|
||||
`sudoers` 文件位于 `/etc/sudoers` 或 `/etc/sudoers.d` 目录中,只有超级用户(root)有权限进行编辑。
|
||||
|
||||
- **谨慎编辑 `sudoers` 文件**:对 `sudoers` 文件的修改应当谨慎进行,并且建议使用 `visudo` 命令来编辑,以确保语法正确并避免意外的访问限制。
|
||||
- **安全性**:在使用 `sudo` 命令时,应确保只有可信任的用户和命令被授权,以防止潜在的安全漏洞。
|
||||
- **审计和记录**:`sudo` 命令的使用会被记录在 `/var/log/auth.log` 文件中,管理员可以通过该日志进行审计和监控。
|
||||
|
||||
```shell
|
||||
# Sudoers 文件示例
|
||||
|
||||
# 允许 `sudo` 组的成员以任何用户身份(ALL:ALL)执行任何命令(ALL)。
|
||||
%sudo ALL=(ALL:ALL) ALL
|
||||
|
||||
# 允许 `admin` 组的成员以任何用户身份(ALL:ALL)执行任何命令(ALL)。
|
||||
%admin ALL=(ALL:ALL) ALL
|
||||
|
||||
# 允许 `root` 用户以任何用户身份(ALL:ALL)执行任何命令(ALL)。
|
||||
root ALL=(ALL:ALL) ALL
|
||||
|
||||
# 允许 `sudo` 组的成员以任何用户身份(ALL:ALL)执行任何命令(ALL),并且无需输入密码(NOPASSWD)。
|
||||
%sudo ALL=(ALL:ALL) NOPASSWD: ALL
|
||||
```
|
||||
|
||||
#### 语法格式
|
||||
|
||||
```shell
|
||||
user/group hosts=(users:groups) commands
|
||||
```
|
||||
|
||||
| 项目 | 描述 |
|
||||
| -------------- | ------------------------------------------------------------ |
|
||||
| `user/group` | 指定用户或用户组,可以使用用户名或组名。 |
|
||||
| `hosts` | 指定可以使用 `sudo` 命令的主机列表,可以是主机名、IP 地址或特殊的通配符。 |
|
||||
| `users:groups` | 指定要执行命令的用户和组,以冒号分隔。 |
|
||||
| `commands` | 指定允许执行的命令。 |
|
||||
| `ALL` | 表示匹配所有主机、用户或命令。 |
|
||||
| `NOPASSWD` | 表示无需输入密码。 |
|
||||
|
||||
#### 使用 `sudo` 命令创建 `sudo` 用户
|
||||
|
||||
```shell
|
||||
# 1. 创建用户
|
||||
sudo adduser username
|
||||
|
||||
# 2. 将用户添加到 sudo 组
|
||||
sudo usermod -aG sudo username
|
||||
|
||||
# 3. 检查用户是否已成功添加到 sudo 组
|
||||
groups username
|
||||
|
||||
# 4. 确认用户可以使用 sudo 命令
|
||||
sudo -l -U username
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ----------------------- | ------------------------------------------------------------ | --------------------------------------- |
|
||||
| `-u, --user USER` | 指定要切换到的用户。 | `sudo -u user1 ls -l` |
|
||||
| `-g, --group GROUP` | 指定要切换到的组。 | `sudo -g group1 ls -l` |
|
||||
| `-k, --reset-timestamp` | 重置 `sudo` 命令的时间戳。 | `sudo -k` |
|
||||
| `-v, --validate` | 验证 `sudo` 命令的权限,但不执行任何命令。 | `sudo -v` |
|
||||
| `-l, --list [COMMAND]` | 显示 `sudo` 命令当前用户的授权信息,或显示指定命令的授权信息。 | `sudo -l` 或 `sudo -l /usr/bin/apt-get` |
|
||||
| `-h, --help` | 显示 `sudo` 命令的帮助信息。 | `sudo -h` |
|
||||
| `-V, --version` | 显示 `sudo` 命令的版本信息。 | `sudo -V` |
|
||||
|
||||
### Newusers
|
||||
|
||||
`newusers` 是一个 Linux 系统命令,用于批量创建新的用户账号。该命令可以从指定的文件中读取一组用户信息,并自动创建这些用户账号,设置相应的密码、主目录和 shell。
|
||||
|
||||
#### 语法格式
|
||||
|
||||
`newusers` 命令从指定的文件中读取用户信息,每行包括以下字段,字段间用冒号分隔:
|
||||
|
||||
```text
|
||||
用户名:密码:用户ID:主组ID:注释字段:主目录:默认shell
|
||||
```
|
||||
|
||||
- 用户名:新用户的登录名。
|
||||
- 密码:用户的密码,通常以加密格式存储。
|
||||
- 用户 ID(UID):新用户的用户标识符。
|
||||
- 主组 ID(GID):新用户的主组标识符。
|
||||
- 注释字段:用户的全名或其他描述信息。
|
||||
- 主目录:用户的主目录路径。
|
||||
- 默认 shell:用户登录时的默认 shell。
|
||||
|
||||
#### 使用 Newusers 批量创建
|
||||
|
||||
```shell
|
||||
-------------------- user.txt --------------------
|
||||
user1:x:1001:1001:User One:/home/user1:/bin/bash
|
||||
user2:x:1002:1002:User Two:/home/user2:/bin/bash
|
||||
user3:x:1003:1003:User Three:/home/user3:/bin/bash
|
||||
--------------------------------------------------
|
||||
|
||||
# 读取 user.txt 批量创建用户
|
||||
newusers user.txt
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ---------------------- | -------------------------- | ------------------------------------------------------------ |
|
||||
| `-u, --uid` | 指定起始用户 ID | `newusers -u 1000 users.txt` |
|
||||
| `-g, --gid` | 指定起始组 ID | `newusers -g 1000 users.txt` |
|
||||
| `-c, --comment` | 指定用户的注释信息 | `newusers -c "User One" users.txt`, `newusers --comment "User One" users.txt` |
|
||||
| `-s, --shell` | 指定新用户的默认 shell | `newusers -s /bin/bash users.txt`, `newusers --shell /bin/bash users.txt` |
|
||||
| `-H, --no-create-home` | 禁止创建用户主目录 | `newusers -H users.txt`, `newusers --no-create-home users.txt` |
|
||||
| `-N, --no-user-group` | 禁止创建与用户名同名的主组 | `newusers -N users.txt`, `newusers --no-user-group users.txt` |
|
||||
|
||||
### Chpasswd
|
||||
|
||||
`chpasswd` 命令用于批量修改用户的密码,可以一次性修改多个用户的密码,而不需要逐个输入密码。它可以从标准输入、文件或命令行参数中读取用户密码信息,并将其应用于指定的用户账户。
|
||||
|
||||
- **文件安全**:文件中包含敏感信息(用户密码),应妥善保管并确保其权限设置正确,以防止未经授权的访问。
|
||||
- **加密格式**:如果密码已加密,确保使用 `-e` 选项。否则,密码将被视为明文并重新加密。
|
||||
- **权限要求**:`chpasswd` 命令需要管理员权限,通常通过 `sudo` 命令运行。
|
||||
- **密码复杂性**:在更新密码时,建议使用复杂密码,包括大小写字母、数字和特殊字符,以提高账户的安全性。
|
||||
|
||||
#### 语法格式
|
||||
|
||||
```text
|
||||
user1:password1
|
||||
user2:password2
|
||||
```
|
||||
|
||||
#### 使用 Chpasswd 批量更改
|
||||
|
||||
```shell
|
||||
-------------------- users.txt --------------------
|
||||
user1:password1
|
||||
user2:password2
|
||||
--------------------------------------------------
|
||||
|
||||
# 将 user1 的密码修改为 password1
|
||||
echo 'user1:password1' | chpasswd
|
||||
|
||||
# 批量更新,使用 md5 加密方式
|
||||
sudo chpasswd -m < users.txt
|
||||
```
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| -------------------- | -------------------------- | -------------------------------------------- |
|
||||
| `-e, --encrypted` | 指定密码已加密 | `chpasswd -e < users.txt` |
|
||||
| `-h, --help` | 显示帮助信息并退出 | `chpasswd --help` |
|
||||
| `-m, --md5` | 指定密码以 MD5 格式加密 | `chpasswd -m < users.txt` |
|
||||
| `-c, --crypt-method` | 指定密码加密方法 | `chpasswd --crypt-method SHA512 < users.txt` |
|
||||
| `-R, --root` | 以 root 权限运行命令 | `sudo chpasswd --root` |
|
||||
| `-u, --update` | 仅更新现有用户的密码 | `chpasswd -u < users.txt` |
|
||||
| `-I, --inactive` | 指定密码失效时间,单位为天 | `chpasswd --inactive 7 < users.txt` |
|
||||
|
||||
### pwck、grpck
|
||||
|
||||
`pwck`(Password Check)和 `grpck`(Group Check)命令是 Linux 系统中用于检查 `/etc/passwd`、`/etc/shadow` 和 `/etc/group` 等文件的格式和完整性的工具。这些命令可以帮助系统管理员查找和修复这些文件中的错误,以确保系统的安全性和稳定性。
|
||||
|
||||
在执行 `pwck` 或 `grpck` 之前,建议备份 `/etc/passwd`、`/etc/shadow`、`/etc/group` 和 `/etc/gshadow` 文件,以防止误操作导致数据丢失。
|
||||
|
||||
**用户配置文件:**
|
||||
|
||||
- **用户配置文件**:`/etc/passwd` 文件是 Linux 系统中存储用户信息的文件之一,包含每个用户的用户名、用户 ID、主目录、登录 shell 等信息。
|
||||
- **用户密码配置文件**:`/etc/shadow` 文件是 Linux 系统中存储用户密码信息的文件之一,包含每个用户的密码哈希值、最后一次更改密码的日期等信息。
|
||||
- **用户组配置文件**:`/etc/group` 文件是 Linux 系统中存储用户组信息的文件之一,包含每个用户组的名称、组 ID 和组成员列表等信息。
|
||||
- **用户组密码配置文件**:`/etc/gshadow` 文件是 Linux 系统中存储用户组密码信息的文件之一,包含每个用户组的密码哈希值、管理员列表和成员列表等信息。
|
||||
- **默认配置文件**:`/etc/login.defs` 文件是 Linux 系统中存储默认登录选项的文件之一,包含默认的密码长度、最大尝试登录次数等信息。
|
||||
- **配置文件**:`/etc/adduser.conf` 文件是 Linux 系统中存储新用户默认配置选项的文件之一,包含新用户的默认主目录、默认 shell 等信息。
|
||||
|
||||
| 选项 | 描述 | 示例 |
|
||||
| ---------------- | ------------------------ | --------------------------------------- |
|
||||
| `-r, --root DIR` | 指定要检查的根目录 | `pwck/grpck -r /mnt` |
|
||||
| `-s, --silent` | 安静模式,只输出错误信息 | `pwck/grpck -s /etc/passwd /etc/shadow` |
|
||||
| `-q, --quiet` | 安静模式,不输出信息 | `pwck/grpck -q /etc/passwd /etc/group` |
|
||||
| `-n, --nocheck` | 不检查用户主目录和组文件 | `pwck/grpck -n /etc/passwd /etc/shadow` |
|
||||
|
||||
### pwconv、pwunconv、grpconv、grpunconv
|
||||
|
||||
`pwconv`(Password Conversion)、`pwunconv`(Password unConversion)、`grpconv`(Group Conversion)和 `grpunconv`(Group unConversion) 命令是 Linux 系统中的工具,用于转换密码文件和组文件的格式。它们帮助系统管理员将 `/etc/passwd`、`/etc/shadow` 和 `/etc/group` 等文件的格式进行转换或恢复,从而提高系统的安全性和管理效率。
|
||||
|
||||
**作用和用途:**
|
||||
|
||||
- **`pwconv` 命令**:将 `/etc/passwd` 和 `/etc/shadow` 文件的格式从标准格式(包括用户名、密码和 UID 等信息)转换为 shadow 格式(将密码单独存储在 `/etc/shadow` 文件中)。
|
||||
- **`pwunconv` 命令**:将 `/etc/passwd` 和 `/etc/shadow` 文件的格式从 shadow 格式转换为标准格式。
|
||||
- **`grpconv` 命令**:将 `/etc/group` 文件的格式从标准格式(包括组名、组密码和 GID 等信息)转换为 gshadow 格式(将组密码单独存储在 `/etc/gshadow` 文件中)。
|
||||
- **`grpunconv` 命令**:将 `/etc/group` 文件的格式从 gshadow 格式转换为标准格式。
|
||||
|
||||
这些工具的用途包括但不限于:
|
||||
|
||||
- **提高系统安全性**:使用 shadow 格式将用户密码单独存储在 `/etc/shadow` 文件中,可以防止未经授权的用户访问密码信息,提高系统安全性。
|
||||
- **管理用户和组的身份验证**:通过转换和恢复密码和组文件格式,可以更轻松地管理用户和组的身份验证信息,例如更改密码、添加或删除用户和组等操作。
|
||||
|
||||
## 其他
|
||||
|
||||
### W
|
||||
|
||||
`w` 命令在 Unix 和 Unix 类操作系统中用于显示有关系统活动的信息。这个命令可以显示当前系统中登录的用户、他们所做的事情、从哪里登录、他们登录的时间以及系统负载等。
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# w
|
||||
14:16:51 up 22:16, 2 users, load average: 0.00, 0.00, 0.00
|
||||
USER TTY 来自 LOGIN@ IDLE JCPU PCPU WHAT
|
||||
sevenwat tty1 - 二16 22:15m 0.16s 0.05s -bash
|
||||
sevenwat pts/0 172.17.0.100 13:55 0.00s 0.51s 0.13s sshd: sevenwate [priv]
|
||||
```
|
||||
|
||||
### Id
|
||||
|
||||
`id` 命令用于显示用户和用户组的标识信息。它可以用于查看当前用户或指定用户的 UID(用户标识符)、GID(组标识符)和所属用户组的名称。
|
||||
|
||||
```shell
|
||||
sevenwate@LinuxTest:~$ id
|
||||
用户id=1000(sevenwate) 组id=1000(sevenwate) 组=1000(sevenwate),24(cdrom),25(floppy),27(sudo),29(audio),30(dip),44(video),46(plugdev),108(netdev),1001(grpdemo)
|
||||
```
|
||||
|
||||
### Whoami
|
||||
|
||||
`whoami` 命令用于显示当前登录用户的用户名。它是一个非常简单的命令,通常用于 shell 脚本和命令行中,以便在需要当前用户的用户名时快速获取它。
|
||||
|
||||
```shell
|
||||
sevenwate@LinuxTest:~$ whoami
|
||||
sevenwate
|
||||
```
|
||||
|
||||
### Last
|
||||
|
||||
`last` 命令在 Linux 中用于显示系统的登录记录。这个命令列出了系统登录和启动的详细信息,如登录用户、登录的 IP 地址、登录时间以及登录持续的时间。
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# last
|
||||
sevenwat pts/0 172.17.0.100 Wed May 31 13:55 still logged in
|
||||
sevenwat pts/1 172.17.0.100 Wed May 31 11:07 - 11:21 (00:14)
|
||||
sevenwat pts/0 172.17.0.100 Wed May 31 11:07 - 13:00 (01:53)
|
||||
sevenwat pts/0 172.17.0.100 Wed May 31 10:55 - 11:04 (00:09)
|
||||
sevenwat pts/0 172.17.0.100 Wed May 31 10:49 - 10:51 (00:02)
|
||||
sevenwat pts/0 172.17.0.100 Tue May 30 17:03 - 17:35 (00:32)
|
||||
sevenwat pts/0 172.17.0.100 Tue May 30 16:03 - 16:53 (00:50)
|
||||
sevenwat pts/2 172.17.0.100 Tue May 30 16:02 - 16:02 (00:00)
|
||||
sevenwat pts/1 172.17.0.100 Tue May 30 16:02 - 16:02 (00:00)
|
||||
sevenwat pts/0 172.17.0.100 Tue May 30 16:02 - 16:02 (00:00)
|
||||
sevenwat tty1 Tue May 30 16:01 still logged in
|
||||
reboot system boot 5.10.0-23-amd64 Tue May 30 16:00 still running
|
||||
|
||||
wtmp begins Tue May 30 16:00:47 2023
|
||||
```
|
||||
|
||||
### Lastlog
|
||||
|
||||
`lastlog` 命令用于查看所有用户最后一次登录的时间和登录的终端。这个命令检查 `/var/log/lastlog` 文件以确定每个用户的最后一次登录信息。此命令的输出包含用户名、最后登录的端口和最后登录的时间。
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# lastlog
|
||||
用户名 端口 来自 最后登录时间
|
||||
root **从未登录过**
|
||||
……
|
||||
sevenwate pts/0 172.17.0.100 三 5月 31 13:55:15 +0800 2023
|
||||
newuser **从未登录过**
|
||||
```
|
||||
|
||||
## 创建用户示例
|
||||
|
||||
```mermaid
|
||||
graph LR
|
||||
SwitchToRoot[切换到 root 用户]
|
||||
SwitchToRoot --> CreateUser[创建新用户]
|
||||
CreateUser --> SetPassword[设置新用户的密码]
|
||||
SetPassword --> ChangeUserInfo{更新新用户信息?}
|
||||
ChangeUserInfo -- Yes --> RunChfn[chfn]
|
||||
ChangeUserInfo -- No --> AssignHomeDir{指定用户目录?}
|
||||
RunChfn --> AssignHomeDir
|
||||
AssignHomeDir -- Yes --> RunUseraddWithD[useradd -d]
|
||||
AssignHomeDir -- No --> SetLoginShell{指定登录 shell?}
|
||||
RunUseraddWithD --> SetLoginShell
|
||||
SetLoginShell -- Yes --> RunUseraddWithS[useradd -s]
|
||||
SetLoginShell -- No --> AddToExtraGroups{添加到额外的组?}
|
||||
RunUseraddWithS --> AddToExtraGroups
|
||||
AddToExtraGroups -- Yes --> RunUsermod[usermod -aG]
|
||||
AddToExtraGroups -- No --> End(结束)
|
||||
RunUsermod --> End
|
||||
```
|
||||
|
||||
1. **打开终端**:快捷键 Ctrl+Alt+T 打开终端。
|
||||
2. **切换到 root 用户**:使用 `su -` 命令切换到 root 用户。
|
||||
3. **使用 useradd 命令创建新用户**:使用 `useradd` 命令和新用户的用户名来创建新用户。例如创建一个名为 `newuser` 的新用户:
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# useradd newuser
|
||||
```
|
||||
|
||||
4. **设置新用户的密码**:使用 `passwd` 命令和新用户的用户名来设置密码。
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# passwd newuser
|
||||
新的 密码:
|
||||
重新输入新的 密码:
|
||||
passwd:已成功更新密码
|
||||
```
|
||||
|
||||
5. **更改新用户的信息**(可选):可以使用 `chfn` 命令更改新用户的全名、房间号、工作电话和家庭电话。
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# chfn newuser
|
||||
正在改变 newuser 的用户信息
|
||||
请输入新值,或直接敲回车键以使用默认值
|
||||
全名 []: newuser
|
||||
房间号码 []: 888
|
||||
工作电话 []: 18688888888
|
||||
家庭电话 []: 0371
|
||||
其它 []:
|
||||
```
|
||||
|
||||
6. **给新用户分配家目录**(可选):默认情况下 `useradd` 命令会为新用户创建一个在 `/home` 下的家目录。`usermod` 可以使用 `-d` 选项为新用户指定一个不同的家目录。例如,指定 `newuser` 的家目录是 `/opt/newuser`:
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# usermod -d /opt/newuser -m newuser
|
||||
```
|
||||
|
||||
7. **指定不同的登录 shell**(可选):`usermod` 可以使用 `-s` 选项指定一个不同的登录 shell。例如为 `newuser` 指定 `/bin/sbin/noligin` 作为登录 shell,你可以运行:
|
||||
|
||||
```shell
|
||||
# 使用 usermod 命令
|
||||
root@LinuxTest:~# usermod -s /usr/bin/nologin newuser
|
||||
# 使用 chsh 命令
|
||||
root@LinuxTest:~# chsh -s /bin/bash newuser
|
||||
```
|
||||
|
||||
8. **将新用户添加到一个或多个额外的组**(可选):可以使用 `usermod` 命令的 `-G` 选项将新用户添加到一个或多个额外的组。例如将 `newuser` 添加到 `sudo` 和 `users` 组,你可以运行:
|
||||
|
||||
```shell
|
||||
root@LinuxTest:~# usermod -aG sudo,users newuser
|
||||
root@LinuxTest:~# id newuser
|
||||
用户id=1003(newuser) 组id=1003(newuser) 组=1003(newuser),27(sudo),100(users)
|
||||
# 用户最终信息
|
||||
root@LinuxTest:~# cat /etc/passwd | grep newuser
|
||||
newuser:x:1003:1003:newuser,888-1,18688888888,0371-88888888:/opt/newuser2:/usr/bin/nologin
|
||||
```
|
||||
@ -1,746 +0,0 @@
|
||||
---
|
||||
title: Linux 网络配置
|
||||
description: Linux 网络配置管理
|
||||
keywords:
|
||||
- Linux 网络
|
||||
- 配置
|
||||
- 管理
|
||||
tags:
|
||||
- Linux/进阶
|
||||
- 技术/操作系统
|
||||
author: 7Wate
|
||||
date: 2023-04-10
|
||||
---
|
||||
|
||||
## 网络配置
|
||||
|
||||
| 发行版 | 网络配置文件路径 | 常用网络管理工具 |
|
||||
| ----------- | -------------------------------------- | ------------------------------------------ |
|
||||
| Ubuntu | /etc/netplan/ | NetworkManager, systemd-networkd |
|
||||
| Debian | /etc/network/interfaces | NetworkManager, systemd-networkd, ifupdown |
|
||||
| CentOS/RHEL | /etc/sysconfig/network-scripts/ifcfg-* | NetworkManager, systemd-networkd, ifcfg |
|
||||
| Fedora | /etc/sysconfig/network-scripts/ifcfg-* | NetworkManager, systemd-networkd, ifcfg |
|
||||
| Arch Linux | /etc/netctl/ | netctl |
|
||||
| openSUSE | /etc/sysconfig/network/ifcfg-* | NetworkManager, ifup |
|
||||
|
||||
- 动态主机配置协议(DHCP):DHCP 用于自动分配 IP 地址、子网掩码、默认网关等网络参数。
|
||||
- 静态地址(Static IP):静态 IP 是预先分配给设备的固定 IP 地址。
|
||||
- 地址(IP):网络设备的唯一标识符。
|
||||
- 子网掩码(NetMask):用于划分 IP 地址的网络和主机部分。
|
||||
- 网关(GetWay):连接不同网络的设备,通常是路由器。
|
||||
- 域名系统(DNS ):将域名解析为 IP 地址的服务。
|
||||
|
||||
### Ip
|
||||
|
||||
ip 命令是 Linux 系统中用于管理网络设备、地址、路由等网络设置的一个强大工具。它是 iproute2 软件包的一部分,由 Alexey N. Kuznetsov 开发,首次发布于 1999 年。ip 命令的设计目的是替代原有的 ifconfig、route 等传统网络配置工具,提供更灵活、功能强大的解决方案。
|
||||
|
||||
ip 命令通过 Netlink 套接字与 Linux 内核通信,实现对网络设备、地址、路由等资源的管理。Netlink 是一种用于在内核和用户空间之间传递信息的通信机制。通过 Netlink,ip 命令能够执行各种复杂的网络配置任务。
|
||||
|
||||
#### 命令
|
||||
|
||||
| 命令 | 说明 |
|
||||
| ------------- | ---------------------- |
|
||||
| ip addr show | 显示网络接口的地址信息 |
|
||||
| ip addr add | 为网络接口添加 IP 地址 |
|
||||
| ip addr del | 删除网络接口的 IP 地址 |
|
||||
| ip link show | 显示网络接口状态 |
|
||||
| ip link set | 修改网络接口属性 |
|
||||
| ip route show | 显示路由表 |
|
||||
| ip route add | 添加路由 |
|
||||
| ip route del | 删除路由 |
|
||||
| ip neigh show | 显示邻居表(ARP 缓存) |
|
||||
| ip neigh add | 添加邻居条目 |
|
||||
| ip neigh del | 删除邻居条目 |
|
||||
|
||||
#### 选项
|
||||
|
||||
| 选项 | 说明 |
|
||||
| ---------- | ---------------------------------------------- |
|
||||
| show | 显示指定类型的网络对象(如地址、链接、路由等) |
|
||||
| add | 添加指定类型的网络对象 |
|
||||
| del | 删除指定类型的网络对象 |
|
||||
| set | 修改指定类型的网络对象的属性 |
|
||||
| list | 列出指定类型的网络对象 |
|
||||
| flush | 清除指定类型的网络对象 |
|
||||
| monitor | 监控网络事件 |
|
||||
| -4 | 仅处理 IPv4 地址和路由 |
|
||||
| -6 | 仅处理 IPv6 地址和路由 |
|
||||
| -s | 输出简化版信息 |
|
||||
| -brief | 以简洁的格式输出信息 |
|
||||
| -json | 以 JSON 格式输出信息 |
|
||||
| -details | 输出详细信息 |
|
||||
| -family | 指定地址族(如 inet、inet6、link 等) |
|
||||
| -dynamic | 设置动态属性(如动态路由等) |
|
||||
| -permanent | 设置永久属性(如永久地址等) |
|
||||
|
||||
#### 实例
|
||||
|
||||
##### 1. 查看当前网络接口信息
|
||||
|
||||
```shell
|
||||
debian@debian:~$ ip route show
|
||||
192.168.101.0/24 dev ens32 proto kernel scope link src 192.168.101.177
|
||||
debian@debian:~$ ip link show
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
|
||||
link/ether 00:0c:29:99:2f:75 brd ff:ff:ff:ff:ff:ff
|
||||
altname enp2s0
|
||||
debian@debian:~$ ip addr show
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
inet 127.0.0.1/8 scope host lo
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 ::1/128 scope host
|
||||
valid_lft forever preferred_lft forever
|
||||
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 00:0c:29:99:2f:75 brd ff:ff:ff:ff:ff:ff
|
||||
altname enp2s0
|
||||
inet 192.168.101.177/24 scope global ens32
|
||||
valid_lft forever preferred_lft forever
|
||||
```
|
||||
|
||||
##### 2. 关闭指定网络接口
|
||||
|
||||
```shell
|
||||
root@debian:~$ ip link set dev ens32 down
|
||||
```
|
||||
|
||||
*如果使用 ssh 注意会断开链接。*
|
||||
|
||||
##### 3. 配置静态 IP 地址
|
||||
|
||||
```shell
|
||||
root@debian:~$ ip addr add 192.168.101.222/24 dev ens32
|
||||
root@debian:~$ ip addr show
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
inet 127.0.0.1/8 scope host lo
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 ::1/128 scope host
|
||||
valid_lft forever preferred_lft forever
|
||||
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 00:0c:29:99:2f:75 brd ff:ff:ff:ff:ff:ff
|
||||
altname enp2s0
|
||||
inet 192.168.101.177/24 scope global ens32
|
||||
valid_lft forever preferred_lft forever
|
||||
inet 192.168.101.222/24 scope global secondary ens32
|
||||
valid_lft forever preferred_lft forever
|
||||
```
|
||||
|
||||
##### 4. 配置网关地址
|
||||
|
||||
```shell
|
||||
root@debian:~$ ip route add default via 192.168.101.1
|
||||
```
|
||||
|
||||
##### 5. 配置 DNS 服务器地址
|
||||
|
||||
```shell
|
||||
root@debian:~$ echo "nameserver 114.114.114.114" > /etc/resolv.conf
|
||||
```
|
||||
|
||||
##### 6. 启用网络接口
|
||||
|
||||
```shell
|
||||
root@debian:~$ ip link set dev ens32 up
|
||||
```
|
||||
|
||||
### NetworkManager
|
||||
|
||||
NetworkManager 是由 Red Hat 公司开发的一款用于管理 Linux 操作系统上网络连接的软件。自 2004 年首次发布以来,它迅速成为 Linux 操作系统中最流行的网络管理工具之一。在 NetworkManager 诞生之前,Linux 中的网络管理通常需要通过手动配置网络文件完成,这一过程不仅繁琐且易出错,但随着 NetworkManager 的出现,这一切都变得简单和直观。
|
||||
|
||||
#### 架构和工作原理
|
||||
|
||||
NetworkManager 展现了其在管理网络连接和网络接口方面的核心能力,提供了一整套综合工具,大大简化了网络设置的复杂性。用户得以轻松添加、修改、启用或禁用各类网络连接,包括有线和无线网络,乃至虚拟私人网络(VPN)。其核心由负责监控和管理网络的后台守护进程、提供直观操作的图形界面以及功能强大的命令行界面组成,还包括管理设备驱动和处理连接请求的高效后端服务。在用户进行网络设置调整时,NetworkManager 自动更新相关配置文件,确保网络设置的一致性和准确性得到坚实保障。借助灵活的插件体系和高效的 D-Bus 通信机制,NetworkManager 能够轻松处理多种类型的网络连接,将配置和管理过程自动化,从而提供了一个无缝、直观且高度可靠的网络管理解决方案。
|
||||
|
||||
#### Nmcli
|
||||
|
||||
`nmcli` 是 NetworkManager 的命令行界面,提供了全面的功能来管理网络。用户可以通过它快速创建、修改和监控网络连接。无论是列出网络设备状态,管理网络连接,设置静态 IP,还是管理 VPN 和其他特殊连接,`nmcli` 都能提供强大支持。
|
||||
|
||||
#### Nmtui
|
||||
|
||||
对于那些偏好图形界面或在终端中工作的用户,`nmtui` 提供了一个简单直观的解决方案。这个交互式的文本界面应用使得配置 NetworkManager 控制的网络设置变得轻松。它的直观操作和无需鼠标的特性,使得 `nmtui` 成为 SSH 会话和终端窗口中理想的网络管理工具。
|
||||
|
||||
#### 命令
|
||||
|
||||
| 命令 | 说明 |
|
||||
| ------------------------- | ------------------------------- |
|
||||
| nmcli dev show | 显示所有网络设备的信息 |
|
||||
| nmcli conn show | 显示所有网络连接的信息 |
|
||||
| nmcli conn up | 启用指定的网络连接 |
|
||||
| nmcli conn down | 禁用指定的网络连接 |
|
||||
| nmcli conn add | 添加一个新的网络连接 |
|
||||
| nmcli conn modify | 修改一个已有的网络连接 |
|
||||
| nmcli conn delete | 删除一个已有的网络连接 |
|
||||
| nmcli connection edit | 编辑一个已有的网络连接 |
|
||||
| nmcli device wifi | 显示所有 Wi-Fi 网络及其相关信息 |
|
||||
| nmcli device wifi rescan | 重新扫描 Wi-Fi 网络列表 |
|
||||
| nmcli device wifi connect | 连接指定的 Wi-Fi 网络 |
|
||||
|
||||
#### 选项
|
||||
|
||||
| 选项 | 说明 |
|
||||
| ------------------ | ------------------------------------------ |
|
||||
| -f,--format | 指定输出格式(例如 csv、json、tabular 等) |
|
||||
| -t,--terse | 指定分隔符 |
|
||||
| -m,--mode | 指定最大输出宽度(用于长文本的换行) |
|
||||
| -p,--set-property | 指定要修改的属性 |
|
||||
| -a,--add | 添加新的属性 |
|
||||
| -r,--remove | 删除一个属性 |
|
||||
| -e,--enable | 激活一个属性 |
|
||||
| -d,--disable | 禁用一个属性 |
|
||||
| -v,--verbose | 输出详细信息 |
|
||||
| -i,--ignore-case | 忽略大小写 |
|
||||
|
||||
#### 实例
|
||||
|
||||
##### 1. 查看当前网络接口信息
|
||||
|
||||
```shell
|
||||
[root@rhel ~]# nmcli device show
|
||||
GENERAL.DEVICE: ens160
|
||||
GENERAL.TYPE: ethernet
|
||||
GENERAL.HWADDR: 00:0C:29:14:E9:70
|
||||
GENERAL.MTU: 1500
|
||||
GENERAL.STATE: 100(已连接)
|
||||
GENERAL.CONNECTION: ens160
|
||||
GENERAL.CON-PATH: /org/freedesktop/NetworkManager/ActiveConnection/1
|
||||
WIRED-PROPERTIES.CARRIER: 开
|
||||
IP4.ADDRESS[1]: 192.168.101.109/24
|
||||
IP4.GATEWAY: 192.168.101.2
|
||||
IP4.ROUTE[1]: dst = 0.0.0.0/0, nh = 192.168.101.2, mt = 100
|
||||
IP4.ROUTE[2]: dst = 192.168.101.0/24, nh = 0.0.0.0, mt = 100
|
||||
IP4.DNS[1]: 192.168.101.2
|
||||
IP4.DOMAIN[1]: localdomain
|
||||
IP6.ADDRESS[1]: fe80::20c:29ff:fe14:e970/64
|
||||
IP6.GATEWAY: --
|
||||
IP6.ROUTE[1]: dst = fe80::/64, nh = ::, mt = 1024
|
||||
|
||||
GENERAL.DEVICE: lo
|
||||
GENERAL.TYPE: loopback
|
||||
GENERAL.HWADDR: 00:00:00:00:00:00
|
||||
GENERAL.MTU: 65536
|
||||
GENERAL.STATE: 10(未托管)
|
||||
GENERAL.CONNECTION: --
|
||||
GENERAL.CON-PATH: --
|
||||
IP4.ADDRESS[1]: 127.0.0.1/8
|
||||
IP4.GATEWAY: --
|
||||
IP6.ADDRESS[1]: ::1/128
|
||||
IP6.GATEWAY: --
|
||||
IP6.ROUTE[1]: dst = ::1/128, nh = ::, mt = 256
|
||||
```
|
||||
|
||||
##### 2. 配置静态 IP 地址
|
||||
|
||||
注意,如果当前已经有一个 DHCP 分配的 IP 地址,则需要首先释放该地址。可以使用以下命令释放 DHCP 分配的 IP 地址:
|
||||
|
||||
```shell
|
||||
nmcli connection modify <connection-name> ipv4.method auto
|
||||
```
|
||||
|
||||
```shell
|
||||
[root@rhel ~]# nmcli connection modify ens160 ipv4.method auto
|
||||
```
|
||||
|
||||
使用以下命令为指定网络接口配置静态 IP 地址:
|
||||
|
||||
```shell
|
||||
nmcli connection modify <connection-name> ipv4.addresses <ip-address>/<subnet-mask> ipv4.gateway <gateway-address> ipv4.dns <dns-address> ipv4.method manual
|
||||
```
|
||||
|
||||
```shell
|
||||
nmcli connection modify ens160 ipv4.addresses 192.168.101.123/24 ipv4.gateway 192.168.101.1 ipv4.dns 114.114.114.114 ipv4.method manual
|
||||
```
|
||||
|
||||
- `<connection-name>` 是要配置的网络连接的名称;
|
||||
- `<ip-address>` 是要设置的 IP 地址;
|
||||
- `<subnet-mask>` 是子网掩码;
|
||||
- `<gateway-address>` 是网关地址;
|
||||
- `<dns-address>` 是 DNS 服务器地址。
|
||||
|
||||
##### 3. 激活新的网络配置
|
||||
|
||||
```shell
|
||||
nmcli connection up <connection-name>
|
||||
```
|
||||
|
||||
```shell
|
||||
nmcli connection up ens160
|
||||
```
|
||||
|
||||
## 网络管理
|
||||
|
||||
### Iptables
|
||||
|
||||
iptables 是 Linux 系统中的一个命令行防火墙工具,它允许系统管理员配置内核防火墙(netfilter)规则。它主要用于数据包过滤、网络地址转换(NAT)和数据包改变,这是因为它在内核空间运行并能为内核提供强大的防火墙和网络处理功能。
|
||||
|
||||
iptables 由 Rusty Russell 在 1998 年创建,并最初作为 ipchains 的替代品发布。它是 netfilter 项目的一部分,该项目的目标是提供一套丰富且可靠的防火墙和路由工具。
|
||||
|
||||
在 iptables 的规则体系中,存在一个重要的概念叫做 " 四表五链 "。这些 " 表 " 和 " 链 " 提供了 iptables 进行包过滤和处理的基础架构。
|
||||
|
||||
**" 四表 " 是指 iptables 的四个预定义的表:filter、nat、mangle 和 raw。**每个表有特定的用途和与之关联的预定义链。
|
||||
|
||||
1. **filter 表:**这是 iptables 默认的表,用于过滤数据包。这个表关联的链有 INPUT、FORWARD 和 OUTPUT。
|
||||
2. **nat 表:**用于网络地址转换(NAT)。这个表关联的链有 PREROUTING、OUTPUT 和 POSTROUTING。
|
||||
3. **mangle 表:**用于特殊的包修改。这个表关联的链有 PREROUTING、INPUT、FORWARD、OUTPUT 和 POSTROUTING。
|
||||
4. **raw 表:**用于配置 exemptions from connection tracking。这个表关联的链有 PREROUTING 和 OUTPUT。
|
||||
|
||||
**" 五链 " 是指 iptables 的五个预定义的链:INPUT、OUTPUT、FORWARD、PREROUTING 和 POSTROUTING。**
|
||||
|
||||
1. **INPUT 链:**处理进入本机的数据包。
|
||||
2. **OUTPUT 链:**处理本机产生的数据包。
|
||||
3. **FORWARD 链:**处理经过本机转发的数据包。
|
||||
4. **PREROUTING 链:**处理所有进入系统的数据包,包括将要转发的数据包,是在路由决定之前处理。
|
||||
5. **POSTROUTING 链:**处理所有离开系统的数据包,是在路由决定之后处理。
|
||||
|
||||
这些表和链提供了 iptables 的强大功能和灵活性,使得系统管理员可以定义精细的包过滤和处理规则,从而实现强大的网络防火墙和路由功能。
|
||||
|
||||
iptables 的主要应用场景常用包括:
|
||||
|
||||
1. **网络防火墙:**iptables 可以定义包过滤规则,拦截或转发进入、离开或穿越防火墙的数据包。
|
||||
2. **网络地址转换(NAT):**iptables 支持源 NAT(SNAT)和目标 NAT(DNAT),使得源 IP 或目标 IP 地址可以被转换或隐藏,从而实现网络中的私有地址与公开地址之间的映射。
|
||||
3. **包改变和重定向:**iptables 可以修改数据包的 IP 头,例如更改源或目标 IP 地址,或重定向数据包到另一个端口或主机。
|
||||
|
||||
iptables 的发展方向主要集中在以下几个方面:
|
||||
|
||||
1. **提高易用性和灵活性:**为了使其更加易于使用和配置,iptables 将继续改进其用户界面和规则配置。
|
||||
2. **提升性能:**随着网络带宽的提升,iptables 将需要提高其处理性能,以满足更大的网络流量。
|
||||
3. **增加新功能:**iptables 将继续添加新的包处理和防火墙功能,以满足日益增长的网络安全需求。
|
||||
|
||||
虽然 iptables 具有强大的功能,但也存在一些缺点。例如,iptables 的**配置较为复杂**,需要花费较多的时间学习和理解。此外,iptables 的**性能与网络流量和规则数量成正比**,大量的规则和网络流量可能会导致性能下降。然而,通过对其功能的深入理解和恰当的配置,管理员可以充分利用 iptables 来建立强大且灵活的网络防火墙。
|
||||
|
||||
随着时间的推移,**iptables 已经不再是 Linux 系统中唯一的防火墙解决方案**。在最近的 Linux 发行版中,nftables 开始替代 iptables 成为默认的防火墙工具。nftables 提供了与 iptables 类似的功能,但具有更优的性能和更简洁的语法。尽管如此,iptables 仍然广泛用于很多系统中,并且由于其强大和灵活的特性,仍然是许多系统管理员的首选工具。
|
||||
|
||||
#### 常用的命令
|
||||
|
||||
```shell
|
||||
# 列出所有防火墙规则
|
||||
sudo iptables -L
|
||||
|
||||
# 添加一条新的规则
|
||||
sudo iptables -A INPUT -p tcp --dport 22 -j ACCEPT
|
||||
|
||||
# 删除一条规则
|
||||
sudo iptables -D INPUT 1
|
||||
|
||||
# 清空所有规则
|
||||
sudo iptables -F
|
||||
|
||||
# 设置默认策略
|
||||
sudo iptables -P INPUT DROP
|
||||
|
||||
# 创建新的链
|
||||
sudo iptables -N LOGGING
|
||||
|
||||
# 删除一个空链
|
||||
sudo iptables -X LOGGING
|
||||
|
||||
# 在链中插入一条规则
|
||||
sudo iptables -I INPUT 1 -p tcp --dport 22 -j ACCEPT
|
||||
|
||||
# 替换链中的一条规则
|
||||
sudo iptables -R INPUT 1 -p tcp --dport 80 -j ACCEPT
|
||||
|
||||
# 列出所有规则的详细信息
|
||||
sudo iptables -S
|
||||
|
||||
# 列出规则,不解析服务名称
|
||||
sudo iptables -n -L
|
||||
|
||||
# 保存 iptables 规则
|
||||
sudo iptables-save > /etc/iptables/rules.v4
|
||||
|
||||
# 恢复 iptables 规则
|
||||
sudo iptables-restore < /etc/iptables/rules.v4
|
||||
```
|
||||
|
||||
### Nftables
|
||||
|
||||
nftables 是一种 Linux 内核的包过滤框架,**它是 iptables,ip6tables,arptables,ebtables 等工具的替代品**,旨在提供单一、统一的解决方案,以简化包过滤和防火墙的配置。nftables 提供了一个新的、更高级的语法,用于更简洁、更直观地定义和管理规则。
|
||||
|
||||
nftables 于 2014 年作为 Linux 内核 3.13 的一部分首次发布。它由同样也是 iptables 创建者的 Netfilter 项目团队开发,主要目的是解决 iptables 在易用性和性能上的一些问题。新的框架是为了改善和扩展现有的过滤系统,提供更强大的网络数据包处理能力。
|
||||
|
||||
nftables 提供了一种新的、基于 Netlink 的接口,用于配置网络过滤规则。它还提供了一种新的语法,用于定义过滤规则。这种**语法更加简洁、直观,比 iptables 的语法更易于学习和使用。**
|
||||
|
||||
与 iptables 相比,nftables 还有一些其他的优点。例如,它能**更高效地处理大量的规则,支持更多的数据类型和操作符,提供更强大的过滤和分类功能,支持动态更新规则,等等。**
|
||||
|
||||
nftables 目前的发展方向主要集中在以下几个方面:
|
||||
|
||||
1. **提升性能:**nftables 将继续优化其性能,以满足日益增长的网络过滤需求,并尽量减少性能开销。
|
||||
2. **增强易用性:**通过改进语法和工具,nftables 将进一步简化规则的配置和管理,使其更易于使用和理解。
|
||||
3. **扩展功能和支持:**nftables 将继续扩展其功能,支持更多的数据类型和操作符,增强过滤和分类功能,等等。
|
||||
|
||||
#### 特性
|
||||
|
||||
1. **更简洁、更直观的语法:**nftables 的语法比 iptables 的语法更简洁、更直观,更易于学习和使用。
|
||||
2. **更高的性能:**nftables 能更高效地处理大量的规则,对性能的影响较小。
|
||||
3. **更强大的功能:**nftables 支持更多的数据类型和操作符,提供更强大的过滤和分类功能,支持动态更新规则。
|
||||
4. **替代多种工具:**nftables 可以替代 iptables,ip6tables,arptables,ebtables 等工具,提供一个统一的解决方案。
|
||||
5. **使用新技术:**作为一种新的包过滤框架,nftables 使用了许多新的技术和接口,这可能需要一些学习和适应。
|
||||
|
||||
尽管 nftables 在许多方面都优于 iptables,但它也存在一些问题。例如,它的**语法和接口与 iptables 不兼容**,这可能导致一些旧的脚本和工具无法正常工作。此外,由于 nftables 是相对较新的技术,可能还存在一些 bug 或不稳定的问题。
|
||||
|
||||
总的来说,nftables 是一种强大而灵活的网络过滤框架,它提供了许多 iptables 所不具备的特性和优点。它的目标是简化网络过滤和防火墙的配置,提供更高的性能,支持更多的功能,使得网络管理员能够更有效地管理他们的网络。
|
||||
|
||||
#### 常用的命令
|
||||
|
||||
```shell
|
||||
# 显示当前已定义的所有表
|
||||
nft list tables
|
||||
|
||||
# 添加一个新表,表名为 "mytable",表类型为 "ip"
|
||||
nft add table ip mytable
|
||||
|
||||
# 列出在表 "mytable" 下的 "mychain" 中定义的所有链
|
||||
nft list chain ip mytable mychain
|
||||
|
||||
# 在表 "mytable" 下添加一个新链 "mychain",并设置链的类型为 "filter",hook 为 "input",优先级为 0
|
||||
nft add chain ip mytable mychain { type filter hook input priority 0 \; }
|
||||
|
||||
# 在 "mychain" 中添加一个新规则,如果源 IP 地址是 192.0.2.1,则丢弃该包
|
||||
nft add rule ip mytable mychain ip saddr 192.0.2.1 drop
|
||||
|
||||
# 列出所有已定义的规则集
|
||||
nft list ruleset
|
||||
|
||||
# 删除在 "mychain" 中的 handle 是 1 的规则
|
||||
nft delete rule ip mytable mychain handle 1
|
||||
|
||||
# 清空指定链 "mychain" 中的所有规则
|
||||
nft flush chain ip mytable mychain
|
||||
|
||||
# 删除指定链 "mytable" 中的 "mychain"
|
||||
nft delete chain ip mytable mychain
|
||||
|
||||
# 删除指定表 "mytable"
|
||||
nft delete table ip mytable
|
||||
|
||||
```
|
||||
|
||||
### UFW
|
||||
|
||||
UFW(Uncomplicated Firewall)是一种简洁的防火墙配置工具,专门为 Linux 设计。该工具的主要目标是简化 iptables 防火墙配置的复杂性,并提供一个用户友好的界面,以便于用户进行操作和管理。UFW 是由 Ubuntu 开发的,但它也能在其他的 Linux 发行版上使用。
|
||||
|
||||
UFW 的功能主要是通过控制网络流量来提供安全防护。用户可以设置防火墙规则,来允许或拒绝某个 IP 地址、端口或服务的入站或出站流量。同时,UFW 也支持 IPv6,这样可以满足现代网络环境的需求。
|
||||
|
||||
#### 特性
|
||||
|
||||
1. **用户友好**:UFW 提供了一个简单易用的命令行界面,使用户能够方便地创建和管理防火墙规则,无需深入理解复杂的 iptables 语法。
|
||||
2. **默认策略**:UFW 默认所有入站连接都被拒绝,所有出站连接都被允许。用户可以根据需要更改这些默认策略。
|
||||
3. **应用配置**:UFW 支持预配置应用规则。用户可以通过简单的命令,轻松添加或删除常见应用的防火墙规则。
|
||||
4. **日志**:UFW 支持日志记录功能,用户可以轻松追踪网络活动和可能的安全问题。
|
||||
5. **IPv6 支持**:UFW 完全支持 IPv6,确保在现代网络环境中提供全面的防火墙保护。
|
||||
|
||||
UFW 的未来发展主要聚焦于以下几个方面:
|
||||
|
||||
1. **用户界面优化**:UFW 将持续优化其用户界面,使其更易于使用和理解。
|
||||
2. **功能扩展**:UFW 将继续扩展其功能,以满足不断增长的网络安全需求。
|
||||
3. **兼容性和稳定性**:UFW 将持续改善其在不同 Linux 发行版上的兼容性和稳定性。
|
||||
|
||||
总的来说,UFW 是一款高度用户友好、简单易用且功能强大的防火墙工具,适用于需要简化防火墙配置的 Linux 用户。
|
||||
|
||||
#### 常用命令
|
||||
|
||||
```shell
|
||||
# 启用 UFW
|
||||
sudo ufw enable
|
||||
|
||||
# 禁用 UFW
|
||||
sudo ufw disable
|
||||
|
||||
# 显示 UFW 状态和规则
|
||||
sudo ufw status
|
||||
|
||||
# 允许特定端口或服务的流量
|
||||
sudo ufw allow 22
|
||||
|
||||
# 拒绝特定端口或服务的流量
|
||||
sudo ufw deny 22
|
||||
|
||||
# 删除特定规则
|
||||
sudo ufw delete allow 22
|
||||
|
||||
# 设置默认的入站或出站策略
|
||||
sudo ufw default deny incoming
|
||||
|
||||
# 显示预配置的应用规则
|
||||
sudo ufw app list
|
||||
|
||||
# 显示特定应用的规则信息
|
||||
sudo ufw app info 'Apache'
|
||||
|
||||
# 设置日志记录级别
|
||||
sudo ufw logging medium
|
||||
|
||||
# 重新加载 UFW 规则,无需重启防火墙服务
|
||||
sudo ufw reload
|
||||
|
||||
# 重置 UFW 配置为默认状态
|
||||
sudo ufw reset
|
||||
```
|
||||
|
||||
### Firewalld
|
||||
|
||||
firewalld 是一个用于管理 Linux 发行版的防火墙的动态守护程序。主要用于 IPv4、IPv6 防火墙规则以及以太网桥的管理,firewalld 基于 nftables 或 iptables 实现网络包过滤。
|
||||
|
||||
相较于传统的防火墙管理方式,firewalld 采用动态管理,能够让你在无需重启防火墙的情况下实时更新策略和规则。firewalld 提供了一种区分网络/防火墙区域并定义其行为的方法,这使你能够为信任的网络接口、设备和服务定义区域,实现更加灵活的防火墙管理。
|
||||
|
||||
#### 特性
|
||||
|
||||
- 对 IPv4 和 IPv6 防火墙规则的全面支持。
|
||||
- 对以太网桥防火墙规则的全面支持。
|
||||
- 通过引入服务和区域概念,使防火墙管理变得更加简单。
|
||||
- 支持动态修改防火墙规则,无需重启。
|
||||
- 提供 D-Bus 和 CLI 界面,方便进行操作。
|
||||
- 具备在容器环境下工作的能力。
|
||||
|
||||
#### 优点
|
||||
|
||||
1. 动态管理:你可以动态地更改设置,无需重启整个防火墙,这在需要临时或频繁更改规则时非常有用。
|
||||
2. 高度定制:你可以创建多个配置文件,并根据实际需要启用或禁用它们,满足各种复杂的应用场景。
|
||||
3. 强大的规则管理:firewalld 支持非常复杂的规则,例如可以基于源 IP 地址或目标 IP 地址,或者基于网络服务(如 HTTP 或 SSH)来设置防火墙规则。
|
||||
|
||||
#### 缺点
|
||||
|
||||
1. 学习曲线:由于 firewalld 的配置和管理方式与 iptables 和 nftables 有所不同,初次接触需要投入一定的时间来学习和熟悉。
|
||||
2. 大规模规则处理性能:虽然在大多数场景下,firewalld 的性能都足够好,但在处理大量的规则时,其性能可能稍逊于 nftables 或 iptables。
|
||||
|
||||
总的来说,firewalld 是一个强大且灵活的防火墙管理工具,适合于对防火墙规则有动态管理需求和复杂配置需求的场景。
|
||||
|
||||
#### 常用命令
|
||||
|
||||
```shell
|
||||
# 启动 firewalld
|
||||
systemctl start firewalld
|
||||
|
||||
# 停止 firewalld
|
||||
systemctl stop firewalld
|
||||
|
||||
# 在启动时启用 firewalld
|
||||
systemctl enable firewalld
|
||||
|
||||
# 查看 firewalld 状态
|
||||
firewall-cmd --state
|
||||
|
||||
# 列出所有默认防火墙规则
|
||||
firewall-cmd --list-all
|
||||
|
||||
# 添加服务到防火墙
|
||||
firewall-cmd --permanent --add-service=http
|
||||
|
||||
# 删除服务
|
||||
firewall-cmd --permanent --remove-service=http
|
||||
|
||||
# 开放端口
|
||||
firewall-cmd --permanent --add-port=8080/tcp
|
||||
|
||||
# 移除端口
|
||||
firewall-cmd --permanent --remove-port=8080/tcp
|
||||
|
||||
# 重新载入防火墙规则
|
||||
firewall-cmd --reload
|
||||
```
|
||||
|
||||
### iptables、nftables、UFW、firewalld 对比
|
||||
|
||||
在 Linux 环境下,`iptables`,`nftables`,`ufw` 和 `firewalld` 都是常用的防火墙工具,每种工具都有其独特的优点和使用场景:
|
||||
|
||||
| | iptables | nftables | ufw | firewalld |
|
||||
| -------------- | ------------ | ------------ | ---------- | ----------------- |
|
||||
| 发布日期 | 1998 | 2014 | 2008 | 2011 |
|
||||
| 操作复杂度 | 高 | 中 | 低 | 中 |
|
||||
| 基于 | netfilter | netfilter | iptables | iptables/nftables |
|
||||
| 内建于内核 | 是 | 是 | 否 | 否 |
|
||||
| GUI | 否 | 否 | 否 | 是 |
|
||||
| 基于区域的过滤 | 否 | 否 | 否 | 是 |
|
||||
| 直接规则 | 是 | 是 | 否 | 是 |
|
||||
| 规则集合 | 否 | 是 | 否 | 是 |
|
||||
| 协议 | IPv4/IPv6 | IPv4/IPv6 | IPv4/IPv6 | IPv4/IPv6 |
|
||||
| 适用于 | 服务器、桌面 | 服务器、桌面 | 桌面、新手 | 服务器、桌面 |
|
||||
| 跨平台 | 是 | 是 | 是 | 是 |
|
||||
| 语法复杂度 | 高 | 低 | 低 | 中 |
|
||||
|
||||
- `iptables` 是最早的防火墙工具之一,尽管其语法复杂,但提供了极高的灵活性和全面的控制,适合需要精细控制防火墙规则的用户或者服务器环境。
|
||||
- `nftables` 是 `iptables` 的现代化替代品,提供了更简洁的语法和规则集合功能,使得配置更为简单。它保持了 `iptables` 的灵活性,同时大大简化了防火墙的配置。
|
||||
- `ufw`(Uncomplicated Firewall)是一个对初学者友好的防火墙前端,主要用于简化 `iptables` 规则的管理。尽管它的功能没有其他工具丰富,但对于只需要基本防火墙功能的用户来说,`ufw` 是一个不错的选择。
|
||||
- `firewalld` 是一个强大的防火墙工具,它可以在不中断网络连接的情况下动态修改防火墙规则。此外,`firewalld` 的基于区域的过滤,图形用户界面,以及规则集合等功能使得管理规则更加简便。
|
||||
|
||||
**总的来说,您应该根据您的特定需求和技能水平选择最适合的防火墙工具。**对于初学者和只需要基本防火墙功能的用户来说,`ufw` 可能是最好的选择。对于需要进行精细控制和高级配置的用户,`iptables` 和 `nftables` 可能更合适。如果您需要一种同时提供强大功能和易用性的防火墙工具,那么 `firewalld` 可能是最好的选择。
|
||||
|
||||
## 网络优化
|
||||
|
||||
### 网络带宽管理
|
||||
|
||||
网络带宽管理是一种在 Linux 系统上优化网络性能和响应时间的方法。它允许管理员控制和分配网络带宽,从而为不同的应用程序和服务提供最佳性能。
|
||||
|
||||
常用工具:
|
||||
|
||||
- tc (Traffic Control):Linux 内核的一部分,用于实现复杂的带宽管理和流量控制策略。
|
||||
- HTB (Hierarchical Token Bucket):一个基于 tc 的流量整形工具,允许管理员创建多层次的带宽限制和优先级分配策略。
|
||||
|
||||
### 网络质量管理(QoS)
|
||||
|
||||
网络质量管理(Quality of Service,QoS)是一种用于分配网络带宽的技术,确保网络资源的公平使用和最佳利用。通过 QoS,管理员可以根据应用程序的需求和优先级分配网络带宽,从而优化网络性能。
|
||||
|
||||
常用工具:
|
||||
|
||||
- tc (Traffic Control):用于实现复杂的 QoS 策略和流量控制。
|
||||
- Wondershaper:一个基于 tc 的简单 QoS 工具,允许管理员轻松设置带宽限制和优先级策略。
|
||||
|
||||
### 负载均衡
|
||||
|
||||
负载均衡是在多个服务器之间分配负载的技术,以提高应用程序的性能和可靠性。在 Linux 系统上,可以使用软件负载均衡器和硬件负载均衡器来实现负载均衡。
|
||||
|
||||
常用工具:
|
||||
|
||||
- HAProxy:一个高性能、高可用性的软件负载均衡器,支持 TCP 和 HTTP 协议。
|
||||
- Nginx:一个功能强大的 Web 服务器,也可以作为负载均衡器和反向代理服务器。
|
||||
- LVS (Linux Virtual Server):一个基于 Linux 内核的负载均衡解决方案,支持多种负载均衡算法。
|
||||
|
||||
### 数据压缩
|
||||
|
||||
数据压缩技术可以减少网络传输的数据量,从而提高网络带宽利用率和传输效率。Linux 系统提供了多种压缩工具和库,支持不同的压缩算法。
|
||||
|
||||
常用工具:
|
||||
|
||||
- gzip:一种广泛使用的文件压缩工具,基于 DEFLATE 压缩算法。
|
||||
- bzip2:一个基于 Burrows-Wheeler 算法的文件压缩工具,提供较高的压缩率。
|
||||
- lz4:一种快速的无损压缩算法,适用于实时场景和大数据处理。
|
||||
|
||||
### 缓存服务
|
||||
|
||||
缓存服务用于在网络上存储和提供数据,以提高访问速度和响应时间。Linux 系统上有多种缓存服务可用,包括 Web 缓存、DNS 缓存和内容分发网络(CDN)。
|
||||
|
||||
常用工具:
|
||||
|
||||
- Squid:一个成熟的 Web 缓存代理服务器,可以用来缓存网站内容和优化网络访问速度。
|
||||
- Unbound:一个轻量级的 DNS 缓存服务器,用于加速 DNS 解析请求和提高域名解析性能。
|
||||
- Varnish:一个高性能的 HTTP 加速器和缓存服务器,广泛用于 Web 应用程序的性能优化。
|
||||
|
||||
### TCP/IP 优化
|
||||
|
||||
TCP/IP 优化包括调整 TCP 拥塞控制算法、修改最大传输单元(MTU)、调整 Nagle 算法等,以提高网络性能和传输速度。Linux 系统提供了多种工具和设置来优化 TCP/IP 性能。
|
||||
|
||||
常用方法:
|
||||
|
||||
- 修改内核参数:通过调整/proc/sys/net/ipv4/目录下的内核参数,如 tcp_wmem、tcp_rmem 和 tcp_congestion_control,以优化 TCP 性能。
|
||||
- 调整 MTU:修改网卡的 MTU 设置,以适应网络环境和提高传输效率。
|
||||
- 禁用 Nagle 算法:通过设置 TCP_NODELAY 选项,关闭 Nagle 算法以减小传输延迟。
|
||||
|
||||
### CDN(内容分发网络)
|
||||
|
||||
内容分发网络(CDN)是一种用于分发静态内容的技术,通过在全球范围内部署多个数据中心,将内容缓存到离用户最近的节点,从而提高访问速度和减轻源服务器负担。CDN 广泛应用于 Web 应用程序和大型网站,以提供优质的用户体验。
|
||||
|
||||
常用 CDN 服务商:
|
||||
|
||||
- Akamai:全球最大的 CDN 服务商,提供广泛的网络加速和安全解决方案。
|
||||
- Cloudflare:一家提供 CDN 和网络安全服务的公司,帮助网站加速和保护其内容。
|
||||
- Amazon CloudFront:亚马逊提供的全球内容分发服务,与其他 AWS 服务紧密集成。
|
||||
|
||||
## 网络安全
|
||||
|
||||
### 网络故障排查与诊断
|
||||
|
||||
Linux 系统提供了一系列工具来帮助用户进行网络故障排查与诊断,包括 ping、traceroute、mtr、nslookup、dig 和 whois 等。
|
||||
|
||||
- ping:用于检测网络连接和延迟,通过发送 ICMP 数据包来检测目标主机是否可达。
|
||||
- traceroute:用于显示数据包从源主机到目标主机经过的路由路径。
|
||||
- mtr:结合了 ping 和 traceroute 功能的网络诊断工具,提供实时路由分析。
|
||||
- nslookup:用于查询 DNS 服务器以获取域名解析信息。
|
||||
- dig:功能强大的 DNS 查询工具,可以获取详细的 DNS 记录信息。
|
||||
- whois:用于查询域名注册信息和 IP 地址分配信息。
|
||||
|
||||
### 安全隔离
|
||||
|
||||
安全隔离是网络安全的重要概念,可以防止潜在的网络攻击和数据泄露。主要实现技术包括 VLAN、DMZ 和容器网络隔离。
|
||||
|
||||
- VLAN (Virtual Local Area Network):通过在网络交换机上配置 VLAN,可以将物理网络划分为多个逻辑子网,实现网络资源的安全隔离。
|
||||
- DMZ (Demilitarized Zone):一种网络安全策略,通过在内部网络和外部网络之间建立一个隔离区域,保护内部网络资源免受外部攻击。
|
||||
- 容器网络隔离:通过使用容器技术(如 Docker、Kubernetes)和虚拟网络(如 Calico、Flannel)来实现应用程序的安全隔离。
|
||||
|
||||
### SSH 安全配置
|
||||
|
||||
SSH 是远程登录和管理 Linux 系统的常用协议。正确配置 SSH 可以提高系统的安全性。
|
||||
|
||||
- 密钥认证:使用公钥/私钥对进行身份验证,替代密码认证,提高安全性。
|
||||
- 端口改变:将 SSH 服务端口从默认的 22 更改为其他端口,降低被扫描和攻击的风险。
|
||||
- 禁止 root 登录:禁止直接通过 SSH 以 root 身份登录,减少被攻击者利用的可能性。
|
||||
- 防止暴力破解:通过限制登录尝试次数、使用防火墙规则或安装防暴力破解软件(如 Fail2Ban)来防止暴力破解攻击。
|
||||
|
||||
和攻击的风险。
|
||||
|
||||
- 禁止 root 登录:禁止直接通过 SSH 以 root 身份登录,减少被攻击者利用的可能性。
|
||||
- 防止暴力破解:通过限制登录尝试次数、使用防火墙规则或安装防暴力破解软件(如 Fail2Ban)来防止暴力破解攻击。
|
||||
|
||||
### 虚拟化网络
|
||||
|
||||
虚拟化网络是在物理网络基础上创建虚拟网络资源的技术,包括虚拟网卡、虚拟交换机、网桥和 SDN(软件定义网络)等。
|
||||
|
||||
- 虚拟网卡:在虚拟机和容器中模拟的网络接口,与物理网卡类似,可用于建立虚拟网络连接。
|
||||
- 虚拟交换机:在虚拟环境中实现网络连接和数据包转发的虚拟设备。
|
||||
- 网桥:用于连接虚拟网络和物理网络,实现虚拟机与外部网络通信。
|
||||
- SDN:一种将网络控制平面与数据平面分离的技术,允许通过软件实现网络资源的动态配置和管理。
|
||||
|
||||
### 网络监测和分析
|
||||
|
||||
网络监测和分析工具可以帮助管理员实时监控网络状况、发现异常行为和安全威胁。常用工具包括 tcpdump、wireshark、netstat、nmap、sniffing、IDS 和 NMS 等。
|
||||
|
||||
- tcpdump:用于捕获和分析网络数据包的命令行工具。
|
||||
- wireshark:一个图形界面的网络协议分析器。
|
||||
- netstat:用于显示网络连接状态和监听端口的命令行工具。
|
||||
- nmap:一款强大的网络扫描和安全审计工具。
|
||||
|
||||
### 网络入侵检测系统(IDS)
|
||||
|
||||
网络入侵检测系统(Intrusion Detection System,IDS)可以检测网络中的恶意行为和攻击活动。常见的 IDS 工具包括 Snort、Suricata、OSSEC 和 Bro/Zeek。
|
||||
|
||||
- Snort:一款开源的网络入侵检测和防御系统,基于规则匹配和异常检测来识别恶意流量。
|
||||
- Suricata:一个高性能的开源 IDS/IPS/NSM(网络安全监控)引擎,支持实时流量分析和威胁防御。
|
||||
- OSSEC:一个开源的主机入侵检测系统,用于监控文件系统、日志文件和网络活动。
|
||||
- Bro/Zeek:一款强大的网络安全监控平台,支持实时流量分析、协议解析和异常检测。
|
||||
|
||||
### 网络安全监控系统(NMS)
|
||||
|
||||
网络安全监控系统(Network Monitoring System,NMS)用于实时监控网络设备和服务的运行状况,发现性能问题和安全威胁。常见的 NMS 工具包括 Nagios、Zabbix、Cacti、Prometheus 和 Grafana。
|
||||
|
||||
- Nagios:一款功能强大的开源网络监控系统,支持多种插件和扩展,用于监控网络设备、服务和应用程序。
|
||||
- Zabbix:一种企业级的开源监控解决方案,提供分布式监控、报警和报表功能。
|
||||
- Cacti:一个基于 RRDtool 的网络图形监控工具,用于绘制网络设备性能图表。
|
||||
- Prometheus:一个开源的监控和告警系统,广泛用于监控微服务和容器化应用程序。
|
||||
- Grafana:一个流行的开源监控数据可视化工具,支持多种数据源,如 Prometheus、InfluxDB 和 Elasticsearch 等。
|
||||
|
||||
### 网络安全审计系统
|
||||
|
||||
网络安全审计系统用于评估网络设备和应用程序的安全性,发现潜在的漏洞和配置问题。常见的安全审计工具包括 OSSEC、Tripwire、AIDE、OpenSCAP 和 Lynis。
|
||||
|
||||
- OSSEC:一个开源的主机入侵检测系统,也可以用于安全审计和配置检查。
|
||||
- Tripwire:一款用于文件完整性检查和安全审计的工具,可以检测文件的变更和潜在的安全问题。
|
||||
- AIDE (Advanced Intrusion Detection Environment):一个用于文件完整性检查和入侵检测的开源工具。
|
||||
- OpenSCAP (Open Security Content Automation Protocol):一个开源的安全配置和漏洞管理框架,基于 SCAP 标准实现。
|
||||
- Lynis:一个开源的安全审计和硬化工具,用于检查 Linux 系统的配置和安全性。
|
||||
|
||||
### 网络加密技术
|
||||
|
||||
网络加密技术用于保护数据在传输过程中的隐私和完整性。主要的网络加密技术包括 SSL/TLS、IPSec、SSH 等。
|
||||
|
||||
- SSL/TLS:安全套接层(Secure Sockets Layer,SSL)和传输层安全(Transport Layer Security,TLS)是应用于网络传输层的加密技术,用于保护 Web 浏览、电子邮件和其他应用程序的数据安全。
|
||||
- IPSec:Internet 协议安全(IP Security,IPSec)是一个用于保护 IP 数据包传输安全的协议套件,提供加密、认证和完整性保护功能。IPSec 广泛应用于 VPN 技术中。
|
||||
- SSH:安全外壳(Secure Shell,SSH)是一种加密网络协议,用于在不安全的网络环境中实现安全的远程登录、文件传输和其他网络服务。
|
||||
|
||||
### 安全认证和授权
|
||||
|
||||
安全认证和授权技术用于验证用户身份和控制用户访问权限。主要技术包括 RADIUS、TACACS+、LDAP、Kerberos 等。
|
||||
|
||||
- RADIUS:远程认证拨号用户服务(Remote Authentication Dial-In User Service,RADIUS)是一个用于 AAA(认证、授权和计费)的网络协议,广泛应用于网络接入和 VPN 服务中。
|
||||
- TACACS+:终端访问控制器访问控制系统 +(Terminal Access Controller Access-Control System+,TACACS+)是一种用于网络设备管理的 AAA 协议,主要应用于路由器、交换机等网络设备的远程管理。
|
||||
- LDAP:轻型目录访问协议(Lightweight Directory Access Protocol,LDAP)是一种用于访问和维护分布式目录信息服务的协议,常用于企业网络的用户认证和组织结构管理。
|
||||
- Kerberos:一种基于票据的网络认证协议,用于实现单点登录(Single Sign-On,SSO)和安全的跨域认证。
|
||||
|
||||
### 网络安全策略和最佳实践
|
||||
|
||||
为了提高网络安全,企业和组织需要制定和实施合适的网络安全策略,并遵循最佳实践。
|
||||
|
||||
- 制定并执行网络安全政策:明确网络资源的访问控制、数据保护和应急响应等方面的要求。
|
||||
- 定期进行安全审计和漏洞扫描:检查网络设备和应用程序的安全配置,发现并修复潜在的安全漏洞。
|
||||
- 提高员工安全意识:通过培训和教育,提高员工对网络安全的认识,防止误操作和内部威胁。
|
||||
1032
Tech/operating-system/Linux/6.网络管理/Linux 网络管理.md
Normal file
1032
Tech/operating-system/Linux/6.网络管理/Linux 网络管理.md
Normal file
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@ -1,472 +0,0 @@
|
||||
## 虚拟化概述
|
||||
|
||||
KVM(Kernel-based Virtual Machine)是一种开源的虚拟化技术,它将 Linux 内核转变为一个功能强大的虚拟化宿主机。通过 KVM,用户可以在同一物理机器上运行多个虚拟机,每个虚拟机都可以运行独立的操作系统和应用程序,从而提高资源利用率和灵活性。
|
||||
|
||||
与其他虚拟化技术相比,KVM 直接集成在 Linux 内核中,提供了一种将 Linux 转变为一个高效且功能强大的虚拟化宿主机的方式。
|
||||
|
||||
### KVM 基本原理
|
||||
|
||||
#### KVM 的技术起源与发展
|
||||
|
||||
KVM 由 Qumranet 公司开发,并于 2007 年被合并到 Linux 内核中,成为内核的一部分。它利用了现代处理器中的硬件辅助虚拟化功能,如 Intel VT-x 和 AMD-V 技术,以提供高效的虚拟化支持。2008 年,红帽公司收购了 Qumranet,进一步推动了 KVM 的发展和应用,使其成为企业级环境中的首选虚拟化解决方案。
|
||||
|
||||
#### KVM 在现代计算中的作用
|
||||
|
||||
KVM 在云计算和数据中心中扮演着至关重要的角色。由于其开源性质和强大的性能,KVM 被许多大型云服务提供商采用,如 Google Cloud、Amazon Web Services 和 IBM Cloud。KVM 提供了接近物理硬件的性能,支持广泛的客户操作系统,并能够高效地管理资源和安全性。
|
||||
|
||||
### KVM 工作原理
|
||||
|
||||
#### KVM 的内核集成方式
|
||||
|
||||
KVM 通过加载 kvm.ko 和处理器特定的模块(如 kvm-intel.ko 或 kvm-amd.ko)来实现虚拟化功能。作为 Linux 内核的一部分,KVM 能够利用内核的调度器、内存管理和 I/O 子系统来高效地管理虚拟机资源。这种紧密的集成使得 KVM 能够提供卓越的性能和稳定性。
|
||||
|
||||
#### KVM 的硬件辅助虚拟化
|
||||
|
||||
KVM 利用硬件辅助虚拟化技术(如 Intel VT-x 和 AMD-V)来创建和管理虚拟机。硬件辅助虚拟化通过提供独立的处理器状态和内存空间,使得每个虚拟机都能独立运行,几乎不受其他虚拟机的影响。这不仅提高了虚拟机的执行效率,还增强了系统的安全性和隔离性。
|
||||
|
||||
### KVM 组件架构
|
||||
|
||||
#### 核心组件和功能
|
||||
|
||||
KVM 的核心组件包括虚拟机管理程序(VMM),如 QEMU。QEMU 是一个开源的虚拟机管理程序,它负责虚拟机的创建、执行和硬件模拟。QEMU 与 KVM 协同工作,通过 KVM 提供的接口来执行客户机代码,并模拟各种硬件设备,如网络接口、存储设备和图形适配器。
|
||||
|
||||
#### 扩展组件和插件系统
|
||||
|
||||
为了适应不同的虚拟化需求,KVM 支持多种扩展组件和插件。例如,网络虚拟化插件可以实现虚拟机之间的网络隔离和通信,而存储管理工具可以提供高效的存储资源分配和管理。这些插件通过模块化的方式集成到 KVM 系统中,提供了灵活的扩展能力和强大的功能。
|
||||
|
||||
#### KVM 与其他虚拟化技术对比
|
||||
|
||||
#### KVM 与 Xen
|
||||
|
||||
Xen 是一种流行的开源虚拟化技术,它通过一个微内核来运行并管理虚拟机。与 KVM 不同,Xen 需要一个单独的管理操作系统来管理虚拟机。虽然 Xen 在某些情况下可能提供更好的隔离性,但 KVM 由于直接集成在 Linux 内核中,通常在性能上更具优势,特别是在利用硬件辅助虚拟化方面。
|
||||
|
||||
#### KVM 与 VMware ESXi
|
||||
|
||||
VMware ESXi 是一个商业虚拟化平台,提供了丰富的企业级功能和支持服务。尽管 KVM 是开源且免费的,但 VMware ESXi 在管理工具和技术支持方面更为成熟。对于寻求开源解决方案的用户而言,KVM 提供了一个具有竞争力的选择,并且在性能和灵活性方面表现出色。
|
||||
|
||||
#### KVM 与 Microsoft Hyper-V
|
||||
|
||||
Microsoft Hyper-V 是一个基于 Windows 的虚拟化解决方案,也支持硬件辅助虚拟化。与 KVM 相比,Hyper-V 在 Windows 环境中更为集成,提供了良好的用户体验和管理工具。然而,KVM 在 Linux 系统中提供了更好的性能和灵活性,对于 Linux 用户来说,是一个更为理想的虚拟化解决方案。
|
||||
|
||||
## 虚拟化管理工具
|
||||
|
||||
虚拟化管理工具是确保虚拟环境高效、安全运行的关键组件。这些工具不仅帮助管理员配置和管理虚拟机,还提供监控、资源管理和优化等功能。本文将详细介绍主要的虚拟化管理工具,包括它们的功能、用途以及优缺点比较。
|
||||
|
||||
### 虚拟机管理器
|
||||
|
||||
#### Cockpit
|
||||
|
||||
Cockpit 是一个基于 Web 的管理界面,适用于 Linux 系统的管理,包括虚拟化管理。Cockpit 提供了一个现代、易用的 Web 界面,使得管理员可以通过浏览器方便地管理系统和虚拟机。它支持 KVM 虚拟化,并可以与 libvirt 一起使用来创建和管理虚拟机。
|
||||
|
||||
#### Virt-manager
|
||||
|
||||
virt-manager,即虚拟机管理器,是一个基于 GTK+ 的图形界面程序,用于管理通过 libvirt 管理的虚拟机。它提供了一个用户友好的界面,使得用户可以创建、修改、监控和控制虚拟机。virt-manager 支持多种虚拟化技术,包括 KVM、Xen 以及 QEMU。此工具的主要优势在于它的简洁性和直观性,使得即便是没有深厚技术背景的用户也能够轻松管理虚拟机。
|
||||
|
||||
#### Qemu-kvm
|
||||
|
||||
qemu-kvm 是 KVM 的核心组件之一,它提供了基于命令行的接口,用于直接创建和管理虚拟机。qemu-kvm 利用 KVM 内核模块和 QEMU 设备模拟功能,实现高效的虚拟化。配置 qemu-kvm 需要了解各种命令行参数,如设定 CPU、内存配置、网络设置等。其灵活性和强大的定制能力是它的主要优点,但同时也需要用户具备较高的技术知识。
|
||||
|
||||
#### Cockpit、virt-manager 和 Qemu-kvm 对比
|
||||
|
||||
| 特性/工具 | Cockpit | virt-manager | qemu-kvm |
|
||||
| ------------------ | -------------------------------------------- | ------------------------------------------ | -------------------------------------------- |
|
||||
| **接口类型** | Web 界面 | 图形界面(GTK+) | 命令行界面 |
|
||||
| **虚拟化技术支持** | KVM, libvirt | KVM, Xen, QEMU | KVM, QEMU |
|
||||
| **用户友好性** | 高,适合初学者和非技术用户 | 中等,适合技术水平一般的用户 | 低,需要高级用户 |
|
||||
| **功能全面性** | 较全面,包括系统管理和监控功能 | 较全面,专注于虚拟机管理 | 高度全面,但需要手动配置 |
|
||||
| **实时监控** | 是 | 是 | 否,需借助其他监控工具 |
|
||||
| **性能调优** | 基础性能监控和调优 | 基础性能监控和调优 | 强大的调优功能,但需手动操作 |
|
||||
| **资源管理** | 支持基本的资源管理功能 | 支持基本的资源管理功能 | 高度灵活的资源管理,但需命令行配置 |
|
||||
| **扩展性** | 高,可集成多个系统管理插件 | 中等,主要依赖 libvirt | 高,可通过命令行和脚本进行深度定制 |
|
||||
| **易用性** | 高,浏览器访问,无需额外客户端安装 | 中等,需要安装客户端 | 低,需要较高的命令行操作能力 |
|
||||
| **适用场景** | 中小型环境、初学者、需要简便的管理界面的场景 | 技术水平中等的用户、需要图形界面管理的场景 | 高级用户、大规模复杂环境、需要高度定制的场景 |
|
||||
| **优点** | 易用、无需额外客户端、集成多种系统管理功能 | 简洁直观的界面、支持多种虚拟化技术 | 灵活性强、可定制性高、强大的命令行控制能力 |
|
||||
| **缺点** | 功能相对基础、不适合复杂的企业级环境 | 功能较为基础、在复杂环境中可能不够灵活 | 学习曲线陡峭、缺乏图形界面、对初学者不友好 |
|
||||
|
||||
#### Libvirt 的角色和功能
|
||||
|
||||
libvirt 是一个开源的库,用于提供统一的方式来管理各种虚拟化技术。它支持 KVM、Xen、LXC、OpenVZ 等多种虚拟化平台。libvirt 提供了一组 API,允许管理虚拟机、存储和网络配置等资源。它的主要优势是能够提供跨多个虚拟化平台的一致性接口,简化了虚拟化资源的管理工作。
|
||||
|
||||
##### 安装依赖
|
||||
|
||||
首先,你需要安装 libvirt 和 libvirt-python 库。如果你使用的是 Ubuntu,可以通过以下命令安装:
|
||||
|
||||
```shell
|
||||
# RHEL 系列
|
||||
sudo apt-get install libvirt-bin libvirt-dev
|
||||
sudo apt-get install python3-libvirt
|
||||
|
||||
# Debian 系列
|
||||
sudo yum install libvirt libvirt-python
|
||||
```
|
||||
|
||||
##### 示例代码
|
||||
|
||||
以下是一个简单的 Python 脚本,用于连接到 libvirt,并列出所有虚拟机的名称和状态:
|
||||
|
||||
```python
|
||||
import libvirt
|
||||
|
||||
def list_vm():
|
||||
try:
|
||||
# 连接到本地的 libvirt 实例
|
||||
conn = libvirt.open('qemu:///system')
|
||||
if conn is None:
|
||||
print('Failed to open connection to qemu:///system')
|
||||
return
|
||||
|
||||
# 获取所有虚拟机的列表
|
||||
domains = conn.listAllDomains(0)
|
||||
if len(domains) == 0:
|
||||
print('No active domains')
|
||||
return
|
||||
|
||||
# 列出每个虚拟机的名称和状态
|
||||
for domain in domains:
|
||||
state, reason = domain.state()
|
||||
state_str = {
|
||||
libvirt.VIR_DOMAIN_NOSTATE: 'No State',
|
||||
libvirt.VIR_DOMAIN_RUNNING: 'Running',
|
||||
libvirt.VIR_DOMAIN_BLOCKED: 'Blocked',
|
||||
libvirt.VIR_DOMAIN_PAUSED: 'Paused',
|
||||
libvirt.VIR_DOMAIN_SHUTDOWN: 'Shutting down',
|
||||
libvirt.VIR_DOMAIN_SHUTOFF: 'Shut off',
|
||||
libvirt.VIR_DOMAIN_CRASHED: 'Crashed',
|
||||
libvirt.VIR_DOMAIN_PMSUSPENDED: 'Suspended'
|
||||
}.get(state, 'Unknown')
|
||||
|
||||
print(f'Domain {domain.name()} is {state_str}')
|
||||
|
||||
# 关闭连接
|
||||
conn.close()
|
||||
|
||||
except libvirt.libvirtError as e:
|
||||
print(repr(e))
|
||||
return
|
||||
|
||||
if __name__ == '__main__':
|
||||
list_vm()
|
||||
```
|
||||
|
||||
#### 资源分配策略和最佳实践
|
||||
|
||||
在虚拟化环境中,合理的资源分配策略是保证性能和稳定性的关键。资源包括 CPU 时间、内存空间、网络带宽和存储容量。以下是一些系统全面的资源分配策略和最佳实践,帮助优化虚拟化环境的性能和稳定性,同时提高资源的利用率。
|
||||
|
||||
##### 1. 均衡分配
|
||||
|
||||
避免单个虚拟机占用过多资源,应通过设置资源限额和保证来均衡各虚拟机的资源使用。
|
||||
|
||||
- **资源限额(Quota)**:为每个虚拟机设置 CPU、内存、网络和存储的使用限额,防止某些虚拟机占用过多资源,影响其他虚拟机的性能。
|
||||
- **资源保证(Reservation)**:确保关键虚拟机在高负载时仍能获得足够的资源,如为数据库服务器或关键应用保留最低的 CPU 和内存资源。
|
||||
|
||||
##### 2. 动态资源管理
|
||||
|
||||
使用动态资源分配技术,根据实际需求调整资源配置。
|
||||
|
||||
- **CPU 和内存热添加(Hot-Add)**:在虚拟机运行时,动态增加 CPU 和内存,无需停机。例如,KVM 支持 CPU 和内存热添加功能,可以根据负载情况实时调整资源。
|
||||
- **自动化资源调度**:利用资源调度工具(如 Kubernetes 或 OpenStack)自动调整虚拟机资源分配,确保资源的高效利用和负载均衡。
|
||||
|
||||
##### 3. 优先级设定
|
||||
|
||||
为关键任务的虚拟机设置较高的资源优先级,确保关键应用的性能和响应时间。
|
||||
|
||||
- **优先级策略**:在虚拟化管理平台中,为关键虚拟机设置较高的优先级,如使用 cgroups 或 libvirt 的调度策略来分配更多的 CPU 时间片。
|
||||
- **性能隔离**:通过虚拟机监控工具(如 Prometheus)定期评估各虚拟机的资源使用情况,并根据业务需求动态调整优先级。
|
||||
|
||||
##### 4. 监控和调整
|
||||
|
||||
定期监控资源使用情况,并根据性能数据调整资源分配策略。
|
||||
|
||||
- **性能监控工具**:使用性能监控工具(如 Zabbix、Nagios、Prometheus 等)监控虚拟机的 CPU、内存、网络和存储使用情况。
|
||||
- **趋势分析**:分析历史性能数据,识别资源使用趋势和瓶颈,提前调整资源分配以应对未来的需求。
|
||||
- **自动化调整**:利用自动化工具(如 Ansible、Chef、Puppet 等)实现资源分配策略的自动化调整,确保虚拟化环境始终处于最佳状态。
|
||||
|
||||
##### 5. 资源隔离
|
||||
|
||||
在多租户环境中,确保各虚拟机之间的资源隔离,防止资源争用和性能干扰。
|
||||
|
||||
- **网络隔离**:使用虚拟局域网(VLAN)或虚拟交换机(vSwitch)隔离不同虚拟机的网络流量,确保网络安全和性能稳定。
|
||||
- **存储隔离**:为不同虚拟机分配独立的存储卷,避免存储 I/O 争用。例如,使用 Ceph 或 iSCSI 实现存储资源的隔离和分配。
|
||||
|
||||
##### 6. 容量规划
|
||||
|
||||
进行容量规划,确保虚拟化环境中的资源能够满足未来的增长需求。
|
||||
|
||||
- **资源预测**:基于历史性能数据和业务增长趋势,预测未来的资源需求,提前进行资源扩展和优化。
|
||||
- **弹性扩展**:使用弹性扩展技术(如自动伸缩组)在高负载时自动增加虚拟机实例,在负载减少时自动减少实例,确保资源利用的高效性和成本的可控性。
|
||||
|
||||
##### 7. 备份和恢复
|
||||
|
||||
定期进行虚拟机的备份,确保在发生故障时能够快速恢复。
|
||||
|
||||
- **快照技术**:使用快照技术定期备份虚拟机的状态和数据,如 KVM 支持的 LVM 快照和 Ceph 快照。
|
||||
- **灾难恢复**:建立完善的灾难恢复计划,确保在发生硬件故障或其他灾难时能够迅速恢复关键虚拟机和业务应用。
|
||||
|
||||
通过实施这些资源分配策略和最佳实践,能够有效优化虚拟化环境的性能和稳定性,提高资源利用率,确保关键业务的连续性和可靠性。
|
||||
|
||||
### 虚拟机监控器
|
||||
|
||||
虚拟机监控是管理虚拟化环境中不可或缺的一部分,它包括对虚拟机的性能、资源使用情况和运行状态的实时监控。通过有效的监控,管理员可以确保虚拟化环境的高效运行,及时发现并解决潜在问题。以下是一些主要的监控工具和技术,以及性能数据的收集与分析方法。
|
||||
|
||||
#### 监控工具和技术
|
||||
|
||||
常用的虚拟机监控工具包括 Zabbix、Nagios、Prometheus 等,它们能够提供细粒度的监控并支持定制化的告警系统。
|
||||
|
||||
- **Zabbix**
|
||||
- **功能**:提供全面的监控解决方案,支持多种数据采集和可视化功能,适合大规模环境。
|
||||
- **优点**:强大的可扩展性和灵活的配置选项,支持自动发现和自定义模板,适合复杂的企业环境。
|
||||
- **缺点**:配置较为复杂,初始设置可能需要较多时间。
|
||||
- **Nagios**
|
||||
- **功能**:广泛使用的开源监控工具,具有灵活的插件系统和强大的告警功能。
|
||||
- **优点**:成熟稳定的架构,支持广泛的第三方插件和扩展,适合中小型企业。
|
||||
- **缺点**:用户界面较为简陋,配置管理复杂,需要较多手动工作。
|
||||
- **Prometheus**
|
||||
- **功能**:专注于时间序列数据的监控和告警,支持强大的查询语言和图表功能。
|
||||
- **优点**:高效的数据存储和查询能力,支持多种数据导出方式,适合云原生环境。
|
||||
- **缺点**:需要与 Grafana 等工具结合使用以实现更丰富的可视化功能。
|
||||
|
||||
#### 性能数据的收集与分析
|
||||
|
||||
收集虚拟机的性能数据对于优化配置、预测未来资源需求和故障排除至关重要。以下是一些关键的性能数据收集和分析方法:
|
||||
|
||||
- **CPU 和内存使用率**
|
||||
- **监控内容**:CPU 使用率、每个虚拟 CPU 的负载情况、内存使用率、内存分配和使用情况。
|
||||
- **工具**:top、htop、vmstat、Zabbix、Prometheus。
|
||||
- **分析方法**:通过监控 CPU 和内存使用率,及时发现和解决性能瓶颈,确保关键任务的资源需求得到满足。
|
||||
- **磁盘 I/O 和网络流量**
|
||||
- **监控内容**:磁盘读写速率、磁盘 I/O 延迟、网络吞吐量、网络包丢失率。
|
||||
- **工具**:iostat、iftop、Zabbix、Prometheus。
|
||||
- **分析方法**:通过监控磁盘 I/O 和网络流量,识别虚拟机的负载模式和潜在的配置问题,优化存储和网络资源配置。
|
||||
- **虚拟机实例的响应时间**
|
||||
- **监控内容**:应用程序响应时间、虚拟机启动和停止时间。
|
||||
- **工具**:Zabbix、Nagios、Prometheus。
|
||||
- **分析方法**:通过监控虚拟机实例的响应时间,评估用户体验和服务质量,及时调整资源分配和优化配置。
|
||||
|
||||
#### 监控策略和最佳实践
|
||||
|
||||
- **实时监控和告警**:设置实时监控和告警系统,确保在问题发生时能够及时通知管理员,迅速采取措施。
|
||||
- **定期审核和优化**:定期审核监控数据,识别和解决性能问题,优化资源配置,提高虚拟化环境的效率和稳定性。
|
||||
- **自动化监控**:利用自动化工具和脚本,简化监控配置和管理,提高监控系统的可靠性和效率。
|
||||
- **历史数据分析**:收集和分析历史性能数据,识别趋势和模式,预测未来资源需求,提前进行容量规划和优化配置。
|
||||
|
||||
通过系统全面的监控和分析,管理员可以确保虚拟化环境的高效运行,及时发现并解决潜在问题,提高资源利用率和用户体验。
|
||||
|
||||
### 虚拟化管理软件比较
|
||||
|
||||
#### 开源工具与商业工具的优缺点
|
||||
|
||||
开源工具,如 KVM 和 Xen,提供了灵活性和成本效益,适合技术能力较强的团队和预算有限的项目。然而,它们可能缺乏商业支持和一些高级功能。
|
||||
|
||||
商业工具,如 VMware ESXi 和 Microsoft Hyper-V,提供全面的技术支持和集成的管理平台,适用于需要高度可靠性和易用性的企业环境。不过,这些工具的成本较高,且可能存在更严格的许可和使用限制。
|
||||
|
||||
#### 主流管理工具的功能对比
|
||||
|
||||
- **VMware vSphere**:提供高级的资源调度、备份和恢复功能,以及广泛的操作系统支持。适合大型企业和数据中心,具备强大的可扩展性和可靠性。
|
||||
- **Microsoft Hyper-V**:与 Windows 环境紧密集成,提供易于使用的管理工具和良好的企业级支持。适合以 Windows 为主的 IT 基础设施。
|
||||
- **Citrix XenServer**:专注于应用虚拟化和桌面虚拟化,提供强大的图形性能和虚拟桌面接口。适合需要高性能图形和桌面虚拟化的环境。
|
||||
|
||||
## 虚拟化管理
|
||||
|
||||
KVM(Kernel-based Virtual Machine)作为一个成熟的虚拟化平台,提供了全面的管理工具和技术来优化虚拟机的部署、配置和监控。本文将详细探讨在 KVM 环境下的虚拟机创建、资源调度、网络和存储管理。
|
||||
|
||||
### 虚拟机创建与配置
|
||||
|
||||
#### 创建虚拟机的步骤
|
||||
|
||||
在 KVM 中,创建虚拟机通常包括以下步骤:
|
||||
|
||||
1. **选择安装介质**:用户需确定虚拟机的操作系统安装源,可以选择 ISO 文件、网络安装源或使用现有的虚拟磁盘作为启动盘。
|
||||
2. **配置虚拟硬件**:根据需要配置虚拟机的 CPU 核心数量、内存大小、网络接口卡、硬盘容量等硬件资源。
|
||||
3. **虚拟机安装**:可以使用图形界面的 virt-manager 或命令行工具 virt-install 启动安装过程。
|
||||
4. **安装客户操作系统**:在虚拟机中安装所选择的操作系统,包括必要的驱动程序和系统组件。
|
||||
5. **安装客户端扩展**:安装如 QEMU guest agent 等工具,以提高虚拟机的性能和管理的便捷性。
|
||||
|
||||
#### 高级配置选项
|
||||
|
||||
对于高级用户或特定应用,KVM 提供了多种高级配置选项,例如:
|
||||
|
||||
- **NUMA 配置**:对于多处理器系统,可以优化内存访问,提高系统性能。
|
||||
- **PCI 直通**:支持虚拟机直接访问物理硬件,适合需要高性能如 GPU 加速的场景。
|
||||
- **CPU 引脚化**:将虚拟机的 CPU 固定到特定的物理 CPU 核心,减少性能损失。
|
||||
|
||||
### 资源调度与监控
|
||||
|
||||
#### CPU 和内存资源管理
|
||||
|
||||
在 KVM 中,合理的 CPU 和内存资源管理对于保证虚拟机性能和响应速度至关重要:
|
||||
|
||||
- **CPU 分配**:可以为虚拟机设定 CPU 份额或限制,以保证多个虚拟机之间的公平资源分配。
|
||||
- **内存分配**:支持动态内存管理,根据虚拟机的实际使用情况自动调整分配的内存大小。
|
||||
|
||||
#### 资源监控工具和技术
|
||||
|
||||
有效的资源监控是确保虚拟化环境稳定运行的关键。常用的监控工具包括:
|
||||
|
||||
- **Nagios**:用于监控系统和网络的开源工具,可以配置用于监视 KVM 虚拟机的状态。
|
||||
- **Grafana 和 Prometheus**:这对组合提供了强大的数据收集与实时监控视图,适用于大规模虚拟化环境。
|
||||
|
||||
### 网络管理
|
||||
|
||||
#### 虚拟网络接口配置
|
||||
|
||||
KVM 提供了灵活的虚拟网络配置选项,包括:
|
||||
|
||||
- **桥接模式**:将虚拟机连接到物理网络,使其表现如同物理机一般。
|
||||
- **NAT 模式**:虚拟机共享宿主机的 IP 地址,适用于不需要直接暴露在外网的环境。
|
||||
|
||||
#### 网络性能优化
|
||||
|
||||
网络性能可以通过以下方式优化:
|
||||
|
||||
- **使用虚拟化网络加速技术**:例如 virtio-net,它提供了比传统模拟设备更高的数据传输效率。
|
||||
- **调整网络缓冲区大小**:根据网络负载调整发送和接收缓冲区,以优化网络响应。
|
||||
|
||||
### 存储管理
|
||||
|
||||
#### 存储配置选项
|
||||
|
||||
KVM 支持多种存储后端,包括:
|
||||
|
||||
- **本地存储**:如直接附加的硬盘或 SSD。
|
||||
- **网络存储解决方案**:如 NFS 或 iSCSI,适用于需要共享存储资源的环境。
|
||||
|
||||
#### 高性能存储解决方案
|
||||
|
||||
为了达到更高的性能,可以采用以下存储优化措施:
|
||||
|
||||
- **使用高性能存储设备**:例如 NVMe 驱动的存储设备,提供极高的读写速度。
|
||||
- **存储 I/O 调优**:优化存储设备的 I/O 性能,如调整队列深度和缓存策略。
|
||||
|
||||
## 虚拟机性能优化
|
||||
|
||||
在虚拟化环境中,性能优化是关键任务之一,它确保虚拟机能够在提供最大效率的同时,还能满足应用程序和用户的需求。本文将探讨针对 CPU、内存、存储和网络的性能优化策略。
|
||||
|
||||
### CPU 性能优化
|
||||
|
||||
#### CPU Pinning 和调度优先级
|
||||
|
||||
**CPU pinning** 是一种技术,通过将虚拟机的 CPU 核心绑定到宿主机的特定物理核心上,可以减少 CPU 调度的延迟和提高缓存的有效性。这通常适用于高性能计算任务或需要高实时性的应用。
|
||||
|
||||
**调度优先级** 的调整也是优化 CPU 资源使用的一种方式。通过设置不同虚拟机的 CPU 调度优先级,可以确保关键应用获得足够的 CPU 时间,从而提高其性能。
|
||||
|
||||
#### NUMA Awareness
|
||||
|
||||
**NUMA(Non-Uniform Memory Access)awareness** 能够优化处理器和内存之间的路径,减少内存访问延迟。在 KVM 虚拟化中启用 NUMA awareness 意味着虚拟机将智能地调度到有利于其性能的物理 NUMA 节点上。
|
||||
|
||||
### 内存性能优化
|
||||
|
||||
#### Huge Pages 的配置和使用
|
||||
|
||||
**Huge pages** 提供了更大的页大小(通常为 2MB 或更大),这减少了页表条目的数量,降低了内存管理的开销,从而提高了性能。在 KVM 中配置 huge pages 可以显著提高内存密集型应用的执行效率。
|
||||
|
||||
#### 内存分配策略
|
||||
|
||||
合理的**内存分配策略** 是提高虚拟机性能的另一个关键因素。动态内存分配可以根据虚拟机的实际使用情况调整其内存大小,而内存预留则可以保证关键应用始终有足够的内存资源。
|
||||
|
||||
### 存储性能优化
|
||||
|
||||
#### 高级存储配置
|
||||
|
||||
采用**高性能存储设备**,如使用 NVMe SSD 代替传统 SATA SSD,可以大幅提升 I/O 性能。同时,合理配置存储缓存和选择正确的文件系统也是优化存储性能的重要因素。
|
||||
|
||||
#### I/O 性能调整
|
||||
|
||||
**I/O 性能调整** 包括适当设置 I/O 调度器、优化队列长度和使用 I/O 虚拟化技术如 virtio。这些调整可以减少 I/O 操作的延迟,提高数据处理速率。
|
||||
|
||||
#### 网络性能优化
|
||||
|
||||
##### 虚拟网络硬件加速
|
||||
|
||||
**虚拟网络硬件加速**,如使用 virtio-net 或 SR-IOV(Single Root I/O Virtualization),可以提供接近物理网络性能的数据传输率。这些技术通过减少虚拟化开销来优化网络性能。
|
||||
|
||||
##### 网络流量管理
|
||||
|
||||
有效的**网络流量管理**策略,包括流量整形、负载均衡和使用高效的网络协议,可以提高网络的吞吐量和响应时间。例如,使用 QoS(Quality of Service)规则可以保证重要应用的网络带宽需求。
|
||||
|
||||
## 虚拟化安全管理
|
||||
|
||||
虚拟化环境提供了灵活、可扩展的计算资源,但同时也带来了新的安全挑战。本文将探讨虚拟化安全管理的关键方面,包括虚拟机的隔离与安全、访问控制、安全更新与漏洞修复,以及安全审计与监控的实施策略。
|
||||
|
||||
### 虚拟机隔离与安全
|
||||
|
||||
#### 隔离技术和实现
|
||||
|
||||
在虚拟化环境中,确保虚拟机之间的隔离是保护数据安全的基础。使用硬件辅助的虚拟化技术(如 Intel VT-x 和 AMD-V)可以在更底层的硬件级别提供隔离。此外,网络隔离可以通过虚拟局域网(VLAN)和网络策略来实现,防止跨虚拟机的数据泄漏或未授权访问。
|
||||
|
||||
#### 安全多租户环境构建
|
||||
|
||||
在构建安全的多租户环境时,采用细粒度的资源访问控制和租户数据加密是关键。此外,通过实施完善的租户隔离策略和使用安全的虚拟网络架构,可以进一步增强环境的安全性。
|
||||
|
||||
### 访问控制
|
||||
|
||||
#### 角色基权限管理
|
||||
|
||||
角色基权限管理(RBAC)是一种有效的访问控制机制,通过为不同的用户分配基于其角色的权限,来限制对敏感操作和数据的访问。在虚拟化平台上实施 RBAC,可以确保只有授权用户才能执行特定的管理任务或访问特定的资源。
|
||||
|
||||
#### 安全访问策略
|
||||
|
||||
安全访问策略应包括强制的身份验证措施、多因素认证和定期的访问权限审查。通过这些策略,可以防止未授权的访问和潜在的安全威胁。
|
||||
|
||||
### 安全更新与漏洞修复
|
||||
|
||||
#### 定期安全更新流程
|
||||
|
||||
建立一个定期的安全更新流程,确保所有虚拟化组件(如虚拟机监控器、管理软件和客户机操作系统)都及时更新,以抵御已知的安全威胁。自动化更新工具和定期的安全检查可以帮助维持系统的安全性。
|
||||
|
||||
#### 快速漏洞响应机制
|
||||
|
||||
对于新发现的漏洞,应建立快速响应机制,包括紧急补丁发布和快速部署。监控安全公告和与虚拟化供应商保持紧密联系,可以确保在漏洞被广泛利用前及时修复。
|
||||
|
||||
### 安全审计与监控
|
||||
|
||||
#### 审计日志管理
|
||||
|
||||
有效的审计日志管理不仅可以帮助跟踪关键操作,还可以在发生安全事件时提供必要的信息以便追踪和分析。应确保审计日志的完整性和保密性,并定期对日志进行审查。
|
||||
|
||||
#### 安全事件监控与响应
|
||||
|
||||
实施全面的安全事件监控系统,能够实时检测和响应潜在的安全威胁。使用入侵检测系统(IDS)和入侵预防系统(IPS)以及现代的安全信息和事件管理(SIEM)解决方案,可以大大提高对复杂威胁的响应能力。
|
||||
|
||||
## 虚拟化管理自动化
|
||||
|
||||
虚拟化管理自动化是提高数据中心效率和响应能力的关键技术。通过自动化,可以减少人为错误,提高操作速度,并确保虚拟环境的一致性和可靠性。本文将探讨虚拟化自动化的几个核心领域:自动化部署、监控、备份与恢复,以及资源扩展与缩减。
|
||||
|
||||
### 自动化部署
|
||||
|
||||
#### 使用脚本和 API 进行自动部署
|
||||
|
||||
自动化部署可以通过编写脚本或使用 API 来实现。脚本(如 Bash, Python 等)可以自动执行创建虚拟机的一系列步骤,包括配置网络、分配资源和安装操作系统。APIs 如 OpenStack 或 VMware vSphere API 则提供了更为复杂和可定制的自动化选项,允许开发者直接与虚拟化基础设施交互,实现高度定制的部署策略。
|
||||
|
||||
#### 模板和快照的应用
|
||||
|
||||
模板和快照是自动化虚拟机部署的强大工具。模板允许管理员创建预配置的虚拟机镜像,用于快速部署新的实例,而快照可以在特定时间点捕捉虚拟机的完整状态,用于快速恢复或克隆。这些工具极大地简化了扩展和管理虚拟环境的过程。
|
||||
|
||||
### 自动化监控
|
||||
|
||||
#### 自动化性能和健康监测
|
||||
|
||||
自动化监控工具如 Zabbix、Nagios 或 Prometheus 可以用于实时跟踪虚拟环境的性能和健康状态。这些工具可以自动化收集和分析 CPU 使用率、内存消耗、存储 I/O 操作和网络流量等关键指标,从而及时发现并响应潜在的问题。
|
||||
|
||||
#### 预警和通知系统
|
||||
|
||||
自动化监控系统通常包括预警和通知功能,当监测到性能降低或系统错误时,它会自动向管理员发送警告。这些通知可以通过电子邮件、短信或集成到其他通信平台如 Slack 中,确保问题能够得到快速响应。
|
||||
|
||||
### 自动化备份与恢复
|
||||
|
||||
#### 备份策略和工具
|
||||
|
||||
自动化备份策略确保所有关键数据定期并且安全地备份。使用如 Veeam、Acronis 或更传统的工具如 rsync,可以配置定期执行的备份任务,包括全备份和增量备份,以及自动验证备份数据的完整性。
|
||||
|
||||
#### 灾难恢复过程自动化
|
||||
|
||||
在发生系统故障时,自动化的灾难恢复过程可以快速恢复服务和数据。通过预设的恢复脚本和策略,系统可以在最短时间内自动重建虚拟机和网络配置,最小化业务中断时间。
|
||||
|
||||
### 自动化扩展与缩减
|
||||
|
||||
#### 弹性计算资源管理
|
||||
|
||||
在需求变化时,自动化的资源管理系统可以根据负载自动调整计算资源的分配。使用如 Kubernetes 这样的容器编排平台可以实现容器级的自动扩展,而传统虚拟机环境可以利用如 VMware DRS(分布式资源调度器)来自动平衡资源负载。
|
||||
|
||||
#### 负载平衡和资源优化
|
||||
|
||||
自动化负载平衡工具可以监控应用程序的需求,并在多台虚拟机间智能分配网络流量和计算任务,以优化性能和资源利用率。此外,资源优化也可以通过自动化工具来实现,如自动关闭低利用率的虚拟机或重新分配资源。
|
||||
Loading…
Reference in New Issue
Block a user