Python:入门基础
This commit is contained in:
parent
ac4f99e9cf
commit
f63df77321
@ -8,20 +8,20 @@ tags:
|
|||||||
- Python
|
- Python
|
||||||
sidebar_position: 4
|
sidebar_position: 4
|
||||||
author: 7Wate
|
author: 7Wate
|
||||||
date: 2022-12-03
|
date: 2023-08-03
|
||||||
---
|
---
|
||||||
|
|
||||||
## 函数
|
## 函数
|
||||||
|
|
||||||
通过白盒/黑盒封装多行代码的实现,一般情况下拥有输入和输出,用来**简化代码**、**重复调用**和**模块化编程**。
|
|
||||||
|
|
||||||
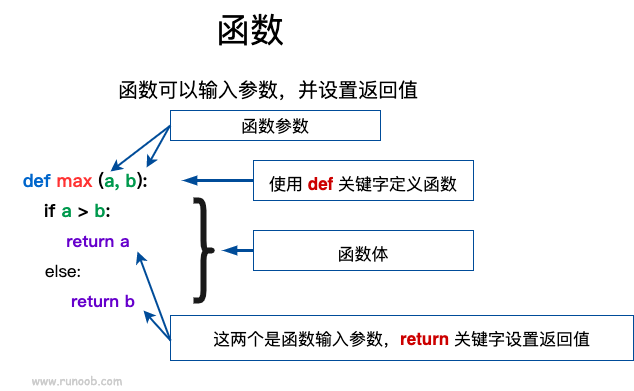
在 Python 中可以使用`def`关键字来定义函数,和变量一样每个函数也有一个响亮的名字,而且命名规则跟变量的命名规则是一致的。函数内的第一条语句是字符串时,该字符串就是**文档字符串**,也称为 docstring。
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
函数是通过白盒/黑盒封装多行代码的实现方式,通常具有输入和输出,目的是为了**简化代码**、**重复调用**和**模块化编程**。
|
||||||
|
|
||||||
|
在 Python 中,`def`关键字用于定义函数,每个函数都具有一个唯一的名称,其命名规则与变量命名规则相同。函数体的第一条语句可以是一个字符串,该字符串被称为**文档字符串**或 docstring,用于提供关于函数的简要描述。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
# 语法
|
# 语法
|
||||||
def 函数名(参数列表):
|
def 函数名(参数列表):
|
||||||
函数体
|
函数体
|
||||||
|
|
||||||
# 实例
|
# 实例
|
||||||
@ -36,7 +36,7 @@ def fib(n):
|
|||||||
|
|
||||||
### 参数传递
|
### 参数传递
|
||||||
|
|
||||||
python 中类型属于对象,对象有不同类型的区分,变量是没有类型的。**python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象**。
|
python 中类型属于对象,变量是没有类型的。**python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。**而不可变对象和可变对象的区别在于:不可变对象的值不可以改变,而可变对象的值可以改变。
|
||||||
|
|
||||||
#### 可更改与不可更改对象
|
#### 可更改与不可更改对象
|
||||||
|
|
||||||
@ -58,8 +58,8 @@ python 中类型属于对象,对象有不同类型的区分,变量是没有
|
|||||||
def add(a=0, b=0, c=0):
|
def add(a=0, b=0, c=0):
|
||||||
"""三个数相加"""
|
"""三个数相加"""
|
||||||
return a + b + c
|
return a + b + c
|
||||||
add(1,2)
|
add(1,2,3)
|
||||||
# 3
|
# 6
|
||||||
```
|
```
|
||||||
|
|
||||||
### 键值参数
|
### 键值参数
|
||||||
@ -129,7 +129,7 @@ def kwd_only_arg(*, arg):
|
|||||||
print(arg)
|
print(arg)
|
||||||
```
|
```
|
||||||
|
|
||||||
特殊参数组合
|
#### 特殊参数组合
|
||||||
|
|
||||||
```python
|
```python
|
||||||
def combined_example(pos_only, /, standard, *, kwd_only):
|
def combined_example(pos_only, /, standard, *, kwd_only):
|
||||||
@ -171,7 +171,76 @@ total = sum( 10, 20 )
|
|||||||
print ("函数外 : ", total)
|
print ("函数外 : ", total)
|
||||||
```
|
```
|
||||||
|
|
||||||
|
## 全局、局部变量
|
||||||
|
|
||||||
|
在 Python 中,变量的作用范围可分为全局变量和局部变量。
|
||||||
|
|
||||||
|
- **全局变量:**在函数体外部声明的变量被称为全局变量。全局变量在程序的整个生命周期内都是可访问的。
|
||||||
|
- **局部变量:**在函数体内部声明的变量被称为局部变量。它们只能在声明它们的函数内部被访问。
|
||||||
|
|
||||||
|
```python
|
||||||
|
x = 10 # 这是一个全局变量
|
||||||
|
|
||||||
|
def func():
|
||||||
|
y = 5 # 这是一个局部变量
|
||||||
|
print(y) # 输出:5
|
||||||
|
|
||||||
|
func()
|
||||||
|
print(x) # 输出:10
|
||||||
|
print(y) # 将会引发一个错误,因为 y 在这个作用域内不存在
|
||||||
|
```
|
||||||
|
|
||||||
|
## global、nonlocal
|
||||||
|
|
||||||
|
当需要在函数或其他作用域内部改变全局变量或嵌套作用域中的变量时,我们需要使用 `global` 或 `nonlocal` 关键字。
|
||||||
|
|
||||||
|
- **global 关键字:** 允许你在函数或其他局部作用域内部修改全局变量。
|
||||||
|
- **nonlocal 关键字:** 允许你在嵌套的函数(即闭包)中修改上一层非全局作用域的变量。
|
||||||
|
|
||||||
|
```python
|
||||||
|
# 使用 global 关键字:
|
||||||
|
x = 10
|
||||||
|
|
||||||
|
def func():
|
||||||
|
global x
|
||||||
|
x = 20 # 修改全局变量 x
|
||||||
|
|
||||||
|
func()
|
||||||
|
print(x) # 输出:20
|
||||||
|
|
||||||
|
# 使用 nonlocal 关键字:
|
||||||
|
def outer():
|
||||||
|
x = 10
|
||||||
|
def inner():
|
||||||
|
nonlocal x
|
||||||
|
x = 20 # 修改上一层函数中的 x
|
||||||
|
|
||||||
|
inner()
|
||||||
|
print(x) # 输出:20
|
||||||
|
|
||||||
|
outer()
|
||||||
|
```
|
||||||
|
|
||||||
|
## yield
|
||||||
|
|
||||||
|
`yield` 是 Python 中用于创建生成器(generator)的关键字。一个包含 `yield` 表达式的函数被称为一个生成器函数。这种函数在被调用时不会立即执行,而是返回一个迭代器,这个迭代器可以在其元素需要被处理时生成它们。这种延迟生成元素的方式使得生成器在处理大数据集或无限序列时非常有用,因为它们不需要一次性生成所有元素,从而节省内存。
|
||||||
|
|
||||||
|
生成器函数在执行到 `yield` 表达式时会暂停并保存当前所有的状态信息(包括局部变量等),在下次从该函数获取下一个元素(即进行下一次迭代)时,它会从保存的状态和位置继续执行。
|
||||||
|
|
||||||
|
```python
|
||||||
|
# yield a 语句会暂停函数的执行并返回当前的 a 值作为序列的下一个元素。
|
||||||
|
# 在下次迭代时,函数会从 yield a 语句后的语句继续执行,计算出序列的下一个值。
|
||||||
|
def fibonacci():
|
||||||
|
a, b = 0, 1
|
||||||
|
while True:
|
||||||
|
yield a
|
||||||
|
a, b = b, a + b
|
||||||
|
|
||||||
|
# zip(range(10), fibonacci()) 部分会生成一个迭代器
|
||||||
|
# 这个迭代器在每次迭代时都会返回斐波那契数列的下一个数字,直到生成了前 10 个数字为止。
|
||||||
|
for _, val in zip(range(10), fibonacci()):
|
||||||
|
print(val)
|
||||||
|
```
|
||||||
|
|
||||||
## Lambda
|
## Lambda
|
||||||
|
|
||||||
@ -184,64 +253,14 @@ lambda 关键字用于创建小巧的匿名函数。Lambda 函数可用于任何
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
# 语法
|
# 语法
|
||||||
lambda [arg1 [,arg2,.....argn]]:expression
|
lambda arguments: expression
|
||||||
# 实例
|
|
||||||
>>> def make_incrementor(n):
|
# lambda 实例
|
||||||
... return lambda x: x + n
|
double = lambda x: x * 2
|
||||||
...
|
|
||||||
>>> f = make_incrementor(42)
|
# 常规函数
|
||||||
>>> f(0)
|
def double(x):
|
||||||
42
|
return x * 2
|
||||||
>>> f(1)
|
|
||||||
43
|
print(double(5)) # 输出:10
|
||||||
```
|
|
||||||
|
|
||||||
## 全局、局部变量
|
|
||||||
|
|
||||||
**定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。**
|
|
||||||
|
|
||||||
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。如下实例:
|
|
||||||
|
|
||||||
```python
|
|
||||||
total = 0 # 全局变量
|
|
||||||
|
|
||||||
def sum( arg1, arg2 ):
|
|
||||||
# 返回 2 个参数的和
|
|
||||||
total = arg1 + arg2 # total在这里是局部变量.
|
|
||||||
print ("函数内是局部变量 : ", total)
|
|
||||||
return total
|
|
||||||
|
|
||||||
#调用 sum 函数
|
|
||||||
sum( 10, 20 )
|
|
||||||
print ("函数外是全局变量 : ", total)
|
|
||||||
```
|
|
||||||
|
|
||||||
## global、nonlocal 关键字
|
|
||||||
|
|
||||||
内部作用域修改外部作用域的变量时,需要使用 global 关键字声明。反之要修改嵌套作用域(enclosing 作用域,外层非全局作用域)中的变量则需要 nonlocal 关键字。
|
|
||||||
|
|
||||||
```python
|
|
||||||
num = 1
|
|
||||||
|
|
||||||
def fun1():
|
|
||||||
global num # 需要使用 global 关键字声明
|
|
||||||
print(num)
|
|
||||||
num = 123
|
|
||||||
print(num)
|
|
||||||
|
|
||||||
fun1()
|
|
||||||
print(num)
|
|
||||||
```
|
|
||||||
|
|
||||||
```python
|
|
||||||
def outer():
|
|
||||||
num = 10
|
|
||||||
def inner():
|
|
||||||
nonlocal num # nonlocal关键字声明
|
|
||||||
num = 100
|
|
||||||
print(num)
|
|
||||||
inner()
|
|
||||||
print(num)
|
|
||||||
|
|
||||||
outer()
|
|
||||||
```
|
```
|
||||||
|
|||||||
@ -8,7 +8,7 @@ tags:
|
|||||||
- Python
|
- Python
|
||||||
sidebar_position: 1
|
sidebar_position: 1
|
||||||
author: 7Wate
|
author: 7Wate
|
||||||
date: 2022-11-20
|
date: 2023-08-03
|
||||||
---
|
---
|
||||||
|
|
||||||
## 简介
|
## 简介
|
||||||
@ -27,7 +27,6 @@ Python 官网上免费提供了 Python 解释器和扩展的标准库,包括
|
|||||||
|
|
||||||
Python 官网还包含许多**免费丰富的第三方 Python 模块**、程序和工具发布包及文档链接。
|
Python 官网还包含许多**免费丰富的第三方 Python 模块**、程序和工具发布包及文档链接。
|
||||||
|
|
||||||
|
|
||||||
## 使用
|
## 使用
|
||||||
|
|
||||||
### 安装
|
### 安装
|
||||||
@ -116,3 +115,29 @@ else :
|
|||||||
suite
|
suite
|
||||||
```
|
```
|
||||||
|
|
||||||
|
此外,Python还支持一些更高级的特性,如函数式编程、面向对象编程和元编程等。随着学习的深入,你会发现Python的世界越来越广阔。
|
||||||
|
|
||||||
|
## 关键字
|
||||||
|
|
||||||
|
Python 的标准库提供了一个 keyword 模块,可以输出当前版本的所有关键字:
|
||||||
|
|
||||||
|
```python
|
||||||
|
$ import keyword
|
||||||
|
$ print(keyword.kwlist)
|
||||||
|
|
||||||
|
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
|
||||||
|
```
|
||||||
|
|
||||||
|
## 声明
|
||||||
|
|
||||||
|
**硬性规则:**
|
||||||
|
|
||||||
|
- 变量名由**字母**(广义的 Unicode 字符,不包括特殊字符)、**数字**和**下划线**构成,**数字不能开头**。
|
||||||
|
- **大小写敏感**(大写的`a`和小写的`A`是两个不同的变量)。
|
||||||
|
- 不要跟**关键字**(有特殊含义的单词)和系统保留字(如函数、模块等的名字)冲突。
|
||||||
|
|
||||||
|
**PEP 8要求:**
|
||||||
|
|
||||||
|
- 用小写字母拼写,多个单词用下划线连接。
|
||||||
|
- 受保护的实例属性用单个下划线开头。
|
||||||
|
- 私有的实例属性用两个下划线开头。
|
||||||
|
|||||||
@ -8,19 +8,23 @@ tags:
|
|||||||
- Python
|
- Python
|
||||||
sidebar_position: 3
|
sidebar_position: 3
|
||||||
author: 7Wate
|
author: 7Wate
|
||||||
date: 2022-11-19
|
date: 2023-08-03
|
||||||
---
|
---
|
||||||
|
|
||||||
## 条件
|
Python 中的控制语句有条件语句,循环语句,异常处理,以及其他一些特殊的控制语句。
|
||||||
|
|
||||||
在 Python 中,判断的值可以分为:
|
## 条件语句
|
||||||
|
|
||||||
|
Python中的条件语句是通过一条或多条语句的执行结果(即True或False)来决定执行的代码块。
|
||||||
|
|
||||||
|
判断的值可以分为:
|
||||||
|
|
||||||
- 假值 :None、空列表、空集合、空字典,空元组、空字符串、0、False 等。
|
- 假值 :None、空列表、空集合、空字典,空元组、空字符串、0、False 等。
|
||||||
- 真值 :非空列表、非空集合、非空字典,非空元组、非空字符串、非 0 数值、True 等。
|
- 真值 :非空列表、非空集合、非空字典,非空元组、非空字符串、非 0 数值、True 等。
|
||||||
|
|
||||||
### if
|
### if
|
||||||
|
|
||||||
在Python中,要构造分支结构可以使用`if`、`elif`和`else`关键字。
|
在Python中,要构造分支结构可以使用`if`、`elif`和`else`关键字。`elif`和`else`都是可选的,可以根据需要进行使用。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
# 示例
|
# 示例
|
||||||
@ -41,7 +45,7 @@ Please enter an integer: 42
|
|||||||
|
|
||||||
### match
|
### match
|
||||||
|
|
||||||
match 语句接受一个表达式并将它的值与以一个或多个 case 语句块形式给出的一系列模式进行比较。 这在表面上很类似 C, Java 或 JavaScript (以及许多其他语言) 中的 switch 语句,但它还能够从值中提取子部分 (序列元素或对象属性) 并赋值给变量。
|
Python 3.10 引入了新的`match`语句,它是模式匹配的一种形式。`match`语句接受一个表达式并将它的值与一系列的模式进行比较。 每个模式都关联到一个代码块,当模式与表达式的值匹配时,该代码块将被执行。这在某种程度上类似于其他语言中的 switch 语句。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
def http_error(status):
|
def http_error(status):
|
||||||
@ -52,12 +56,11 @@ def http_error(status):
|
|||||||
return "Not found"
|
return "Not found"
|
||||||
case 418:
|
case 418:
|
||||||
return "I'm a teapot"
|
return "I'm a teapot"
|
||||||
|
#"变量名" `_` 被作为 通配符 并必定会匹配成功
|
||||||
case _:
|
case _:
|
||||||
return "Something's wrong with the internet"
|
return "Something's wrong with the internet"
|
||||||
```
|
```
|
||||||
|
|
||||||
最后一个代码块: **"变量名" `_` 被作为 通配符 并必定会匹配成功**。 如果没有任何 case 语句匹配成功,则任何分支都不会被执行。
|
|
||||||
|
|
||||||
你可以使用 `|` (“ or ”)在一个模式中组合几个字面值:
|
你可以使用 `|` (“ or ”)在一个模式中组合几个字面值:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
@ -65,10 +68,14 @@ case 401 | 403 | 404:
|
|||||||
return "Not allowed"
|
return "Not allowed"
|
||||||
```
|
```
|
||||||
|
|
||||||
## 循环
|
*注意,`match`语句和模式匹配的概念是Python 3.10中新增的特性,可能在更早版本的Python中无法使用。*
|
||||||
|
|
||||||
|
## 循环语句
|
||||||
|
|
||||||
### for
|
### for
|
||||||
|
|
||||||
|
Python 的 for 语句用于遍历任何序列的项目,如列表或字符串。
|
||||||
|
|
||||||
Python 的 for 语句与 C 或 Pascal 中的不同。**Python 的 for 语句不迭代算术递增数值**(如 Pascal),或是给予用户定义迭代步骤和暂停条件的能力(如 C),而是迭代列表或字符串等任意序列,元素的迭代顺序与在序列中出现的顺序一致。
|
Python 的 for 语句与 C 或 Pascal 中的不同。**Python 的 for 语句不迭代算术递增数值**(如 Pascal),或是给予用户定义迭代步骤和暂停条件的能力(如 C),而是迭代列表或字符串等任意序列,元素的迭代顺序与在序列中出现的顺序一致。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
@ -84,16 +91,17 @@ print(sum)
|
|||||||
|
|
||||||
**内置函数 range() 表示不可变的数字序列,通常用于在 for 循环中循环指定的次数。**
|
**内置函数 range() 表示不可变的数字序列,通常用于在 for 循环中循环指定的次数。**
|
||||||
|
|
||||||
`range(101)`可以用来构造一个从 1 到 100 的范围,当我们把这样一个范围放到 `for-in` 循环中,就可以通过前面的循环变量 `x` 依次取出从 1 到 100 的整数。当然,`range` 的用法非常灵活,下面给出了一个例子:
|
在 Python 中,`range()` 是一个内置函数,用于生成一个不可变的数字序列。通常,这个函数在 for 循环中使用,用于指定循环的次数。`range(101)`可以用来生成一个包含0到100(不包含101)的整数序列。
|
||||||
|
|
||||||
- `range(101)`:可以用来产生 0 到 100 范围的整数,需要注意的是取不到 101。
|
你也可以根据需要更改`range()`函数的参数,例如:
|
||||||
- `range(1, 101)`:可以用来产生 1 到 100 范围的整数,相当于前面是闭区间后面是开区间。
|
|
||||||
- `range(1, 101, 2)`:可以用来产生 1 到 100 的奇数,其中 2 是步长,即每次数值递增的值。
|
- `range(1, 101)`:生成一个包含1到100(不包含101)的整数序列。
|
||||||
- `range(100, 0, -2)`:可以用来产生 100 到 1 的偶数,其中 -2 是步长,即每次数字递减的值。
|
- `range(1, 101, 2)`:生成一个包含1到100的奇数序列,其中2是步长。
|
||||||
|
- `range(100, 0, -2)`:生成一个包含100到1的偶数序列,其中-2是步长。
|
||||||
|
|
||||||
### while
|
### while
|
||||||
|
|
||||||
如果要构造不知道具体循环次数的循环结构,那么使用`while`循环通过一个能够产生或转换出`bool`值的表达式来控制循环,表达式的值为`True`则继续循环;表达式的值为`False`则结束循环。
|
`while` 循环语句用于在条件满足的情况下重复执行一个代码块。条件表达式的结果为`True`时,继续循环;结果为`False`时,结束循环。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
"""
|
"""
|
||||||
@ -120,91 +128,136 @@ if counter > 7:
|
|||||||
|
|
||||||
### break
|
### break
|
||||||
|
|
||||||
break 语句和 C 中的类似,用于跳出最近的 for 或 while 循环。
|
`break` 语句可以提前退出循环。具体来说,**`break` 用于完全结束一个循环,并跳出该循环体。**
|
||||||
|
|
||||||
### continue
|
### continue
|
||||||
|
|
||||||
continue 语句也借鉴自 C 语言,表示继续执行循环的下一次迭代。
|
`continue` 语句用于**跳过当前循环的剩余语句,然后继续进行下一轮循环。**
|
||||||
|
|
||||||
### else
|
### else
|
||||||
|
|
||||||
循环语句支持 else 子句;for 循环中,可迭代对象中的元素全部循环完毕时,或 while 循环的条件为假时,执行该子句;break 语句终止循环时,不执行该子句。
|
在 Python 中,`else` 子句可以与 `for` 循环和 `while` 循环一起使用。当循环正常完成(即没有碰到 `break` 语句)时,`else` 块的内容会被执行。这个特性在很多其他语言中都没有,因此对于初学者来说可能会感到有些不熟悉。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
for n in range(2, 10):
|
# 使用 else 的 for 循环的示例
|
||||||
for x in range(2, n):
|
for i in range(5):
|
||||||
if n % x == 0:
|
if i == 10:
|
||||||
print(n, 'equals', x, '*', n//x)
|
break
|
||||||
break
|
else:
|
||||||
else:
|
print("循环正常完成")
|
||||||
# loop fell through without finding a factor
|
|
||||||
print(n, 'is a prime number')
|
|
||||||
|
|
||||||
"""
|
|
||||||
2 is a prime number
|
|
||||||
3 is a prime number
|
|
||||||
4 equals 2 * 2
|
|
||||||
5 is a prime number
|
|
||||||
6 equals 2 * 3
|
|
||||||
7 is a prime number
|
|
||||||
8 equals 2 * 4
|
|
||||||
9 equals 3 * 3
|
|
||||||
"""
|
|
||||||
```
|
```
|
||||||
|
|
||||||
## 异常
|
在这个示例中,循环会正常完成,因为没有任何一个元素使得 `i == 10` 为 `True`,所以 `break` 语句不会被执行,`else` 块的内容会被打印出来。
|
||||||
|
|
||||||
|
如果我们修改 `if` 语句的条件使得 `break` 语句被执行,那么 `else` 块的内容就不会被打印出来:
|
||||||
|
|
||||||
|
```Python
|
||||||
|
for i in range(5):
|
||||||
|
if i == 3:
|
||||||
|
break
|
||||||
|
else:
|
||||||
|
print("循环正常完成")
|
||||||
|
```
|
||||||
|
|
||||||
|
在这个示例中,当 `i` 等于3时,`break` 语句就会被执行,所以循环没有正常完成,`else` 块的内容不会被打印出来。
|
||||||
|
|
||||||
|
同样的,`else` 也可以与 `while` 循环一起使用,当 `while` 循环的条件变为 `False` 时,`else` 块的内容会被执行。
|
||||||
|
|
||||||
|
```python
|
||||||
|
i = 0
|
||||||
|
while i < 5:
|
||||||
|
if i == 3:
|
||||||
|
break
|
||||||
|
i += 1
|
||||||
|
else:
|
||||||
|
print("循环正常完成")
|
||||||
|
```
|
||||||
|
|
||||||
|
在这个示例中,当 `i` 等于3时,`break` 语句就会被执行,所以循环没有正常完成,`else` 块的内容不会被打印出来。
|
||||||
|
|
||||||
|
## 异常语句
|
||||||
|
|
||||||
### try、except、finally
|
### try、except、finally
|
||||||
|
|
||||||

|
```mermaid
|
||||||
|
graph TD
|
||||||
|
A(开始)
|
||||||
|
B[try 块]
|
||||||
|
C[except 块1]
|
||||||
|
D[except 块2]
|
||||||
|
E[else 块]
|
||||||
|
F[finally 块]
|
||||||
|
G(结束)
|
||||||
|
A --> B
|
||||||
|
B -- 异常1 --> C
|
||||||
|
B -- 异常2 --> D
|
||||||
|
B -- 无异常 --> E
|
||||||
|
C --> F
|
||||||
|
D --> F
|
||||||
|
E --> F
|
||||||
|
F --> G
|
||||||
|
|
||||||
1. `except`语句不是必须的,`finally`语句也不是必须的,但是二者必须要有一个,否则就没有`try`的意义了。
|
```
|
||||||
2. `except`语句可以有多个,Python会按`except`语句的顺序依次匹配你指定的异常,如果异常已经处理就不会再进入后面的`except`语句。
|
|
||||||
3. `except`语句可以以元组形式同时指定多个异常,参见实例代码。
|
1. **确定需要的异常处理结构**:在开始编写异常处理结构时,首先确定你需要 `try`, `except`, `else` 和/或 `finally` 语句块。要记住的是,`except` 和 `finally` 块至少需要一个,否则 `try` 将失去其意义。
|
||||||
4. `except`语句后面如果不指定异常类型,则默认捕获所有异常,你可以通过logging或者sys模块获取当前异常。
|
2. **编写 `try` 语句块**:将可能抛出异常的代码放入 `try` 块。如果在 `try` 块中发生异常,Python 将停止执行 `try` 块的其余部分,并转到 `except` 块。
|
||||||
5. 如果要捕获异常后要重复抛出,请使用`raise`,后面不要带任何参数或信息。
|
3. **编写 `except` 语句块**:为每种可能抛出的异常类型编写一个 `except` 块。Python 会按照它们在代码中出现的顺序来检查这些 `except` 块。如果匹配到异常,Python 将执行相应的 `except` 块并停止查找。
|
||||||
6. 不建议捕获并抛出同一个异常,请考虑重构你的代码。
|
4. **处理多个异常**:你可以将多个异常类型放入一个元组中,然后使用一个 `except` 块来处理它们。例如:`except (TypeError, ValueError):`。
|
||||||
7. 不建议在不清楚逻辑的情况下捕获所有异常,有可能你隐藏了很严重的问题。
|
5. **处理所有异常**:如果 `except` 块后面没有指定异常类型,那么这个 `except` 块将处理所有异常。你可以通过 `logging` 或 `sys` 模块获取异常的详细信息。
|
||||||
8. 尽量使用内置的异常处理语句来替换`try/except`语句,比如`with`语句,`getattr()`方法。
|
6. **重新抛出异常**:如果你在 `except` 块中捕获了一个异常,然后想要再次抛出它,你可以使用 `raise` 语句而不需要附加任何参数或信息。
|
||||||
|
7. **编写 `else` 语句块**:`else` 块中的代码只有在 `try` 块没有发生任何异常时才会被执行。
|
||||||
|
8. **编写 `finally` 语句块**:无论是否发生异常,`finally` 块中的代码总是会被执行。这对于清理(例如关闭文件或网络连接)非常有用。
|
||||||
|
9. **重构代码**:考虑使用 `with` 语句或 `getattr()` 方法等内置的异常处理语句,而不是 `try/except`。此外,如果可能,尽量避免在同一个 `except` 块中捕获和抛出相同的异常。最后,除非你确定需要处理所有可能的异常,否则不应该捕获所有异常,因为这可能会隐藏严重的问题。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
|
# 示例
|
||||||
|
try:
|
||||||
|
# 这里可能会抛出异常的代码
|
||||||
|
do_something()
|
||||||
|
except SomeException as e:
|
||||||
|
# 当捕获到SomeException时的处理代码
|
||||||
|
handle_exception(e)
|
||||||
|
|
||||||
|
# 实例
|
||||||
def div(a, b):
|
def div(a, b):
|
||||||
try:
|
try:
|
||||||
print(a / b)
|
print(a / b)
|
||||||
except ZeroDivisionError:
|
except ZeroDivisionError:
|
||||||
print("Error: b should not be 0 !!")
|
print("错误:b 不应为 0 !!")
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print("Unexpected Error: {}".format(e))
|
print("意外错误:{}".format(e))
|
||||||
else:
|
else:
|
||||||
print('Run into else only when everything goes well')
|
print('只有当一切正常时,才会运行 else')
|
||||||
finally:
|
finally:
|
||||||
print('Always run into finally block.')
|
print('始终运行 finally 块。')
|
||||||
|
|
||||||
# tests
|
# 测试
|
||||||
div(2, 0)
|
div(2, 0)
|
||||||
div(2, 'bad type')
|
div(2, '错误的类型')
|
||||||
div(1, 2)
|
div(1, 2)
|
||||||
|
|
||||||
# Mutiple exception in one line
|
|
||||||
|
# 在一行中捕获多个异常
|
||||||
try:
|
try:
|
||||||
print(a / b)
|
print(a / b)
|
||||||
except (ZeroDivisionError, TypeError) as e:
|
except (ZeroDivisionError, TypeError) as e:
|
||||||
print(e)
|
print(e)
|
||||||
|
|
||||||
# Except block is optional when there is finally
|
|
||||||
|
# 当存在 finally 时,except 是可选的
|
||||||
try:
|
try:
|
||||||
open(database)
|
open(database)
|
||||||
finally:
|
finally:
|
||||||
close(database)
|
close(database)
|
||||||
|
|
||||||
# catch all errors and log it
|
# 捕获所有错误并记录下来
|
||||||
try:
|
try:
|
||||||
do_work()
|
do_work()
|
||||||
except:
|
except:
|
||||||
# get detail from logging module
|
# 从 logging 模块获取详细信息
|
||||||
logging.exception('Exception caught!')
|
logging.exception('捕获到异常!')
|
||||||
|
|
||||||
# get detail from sys.exc_info() method
|
# 从 sys.exc_info() 方法获取详细信息
|
||||||
error_type, error_value, trace_back = sys.exc_info()
|
error_type, error_value, trace_back = sys.exc_info()
|
||||||
print(error_value)
|
print(error_value)
|
||||||
raise
|
raise
|
||||||
@ -212,15 +265,15 @@ except:
|
|||||||
|
|
||||||
### with
|
### with
|
||||||
|
|
||||||
Python 的 with 语句支持通过上下文管理器所定义的运行时上下文这一概念。 此对象的实现使用了一对专门方法,**允许用户自定义类来定义运行时上下文**,在语句体被执行前进入该上下文,并在语句执行完毕时退出该上下文。
|
Python 的 with 语句支持通过上下文管理器所定义的运行时上下文这一概念。
|
||||||
|
|
||||||
通过上下文管理器,我们可以更好的控制对象在不同区间的特性,并且**可以使用 with 语句替代 try...except** 方法,使得代码更加的简洁,主要的**使用场景是访问资源,可以保证不管过程中是否发生错误或者异常都会执行相应的清理操作,释放出访问的资源。**
|
`with`语句是一种处理上下文管理器的语句,上下文管理器通常包含`__enter__`和`__exit__`这两个方法。在`with`语句的代码块被执行前,会首先执行`__enter__`方法,在执行完毕后,会调用`__exit__`方法。这在你需要管理资源,如文件,网络连接或锁定等情况非常有用,因为它可以**保证在任何情况下都会执行必要的清理操作。**
|
||||||
|
|
||||||
```python
|
```python
|
||||||
# with 读写文件
|
# 在这里,文件已经被关闭,无需再次手动关闭
|
||||||
with open("myfile.txt") as f:
|
with open("file.txt", "r") as file:
|
||||||
for line in f:
|
for line in file:
|
||||||
print(line, end="")
|
print(line)
|
||||||
```
|
```
|
||||||
|
|
||||||
```python
|
```python
|
||||||
@ -228,109 +281,76 @@ with open("myfile.txt") as f:
|
|||||||
# 紧跟 with 后面的语句被求值后,返回对象的 enter() 方法被调用,并将返回值赋值给 as 后面的变量。
|
# 紧跟 with 后面的语句被求值后,返回对象的 enter() 方法被调用,并将返回值赋值给 as 后面的变量。
|
||||||
# 当 with 的代码块全部被执行完之后,将调用前面返回对象的 exit() 方法。
|
# 当 with 的代码块全部被执行完之后,将调用前面返回对象的 exit() 方法。
|
||||||
|
|
||||||
class Sample:
|
class ManagedFile:
|
||||||
|
def __init__(self, filename):
|
||||||
|
self.filename = filename
|
||||||
|
|
||||||
def __enter__(self):
|
def __enter__(self):
|
||||||
print("In __enter__()")
|
self.file = open(self.filename, 'r')
|
||||||
return "Foo"
|
return self.file
|
||||||
|
|
||||||
def __exit__(self, type, value, trace):
|
def __exit__(self, exc_type, exc_val, exc_tb):
|
||||||
print("In __exit__()")
|
if self.file:
|
||||||
|
self.file.close()
|
||||||
|
|
||||||
|
# 使用自定义的上下文管理器
|
||||||
def get_sample():
|
with ManagedFile("file.txt") as file:
|
||||||
return Sample()
|
print(file.read())
|
||||||
|
|
||||||
|
|
||||||
with get_sample() as sample:
|
|
||||||
print("sample:", sample)
|
|
||||||
```
|
```
|
||||||
|
|
||||||
### raise
|
### raise
|
||||||
|
|
||||||
`raise`语句支持强制触发指定的异常。例如:
|
`raise`语句用于引发特定的异常。你可以定义异常类型并附加一个错误消息:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
raise NameError('HiThere')
|
raise ValueError("这是一个无效的值!")
|
||||||
|
|
||||||
Traceback (most recent call last):
|
|
||||||
File "<stdin>", line 1, in <module>
|
|
||||||
|
|
||||||
NameError: HiThere
|
|
||||||
```
|
```
|
||||||
|
|
||||||
## 其他
|
如果你在`except`块中使用`raise`语句,而不提供任何参数,它将默认重新引发最近的异常。
|
||||||
|
|
||||||
|
```python
|
||||||
|
try:
|
||||||
|
print(5/0)
|
||||||
|
except ZeroDivisionError as e:
|
||||||
|
print("发生了一个错误!")
|
||||||
|
raise # 重新引发最近的异常
|
||||||
|
```
|
||||||
|
|
||||||
|
## 其他语句
|
||||||
|
|
||||||
### assert
|
### assert
|
||||||
|
|
||||||
Python 断言(assert)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
|
`assert` 语句用于断言某个条件为真,如果条件为假,则会抛出 `AssertionError` 异常。它常常用于调试代码,确认代码的某些方面满足预期,例如:
|
||||||
|
|
||||||
简单形式 `assert expression` 等价于:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
if __debug__:
|
x = 1
|
||||||
if not expression: raise AssertionError
|
assert x == 1 # 条件为真,没有问题
|
||||||
|
|
||||||
|
# 条件为假,抛出 AssertionError,并附带错误信息
|
||||||
|
assert x == 2, "x should be 2 but is actually " + str(x)
|
||||||
```
|
```
|
||||||
|
|
||||||
扩展形式 `assert expression1, expression2` 等价于:
|
*注意,`assert` 语句在优化模式下(使用 `-O` 参数启动 Python 时)会被全局禁用。*
|
||||||
|
|
||||||
```python
|
|
||||||
if __debug__:
|
|
||||||
if not expression1: raise AssertionError(expression2)
|
|
||||||
```
|
|
||||||
|
|
||||||
### pass
|
### pass
|
||||||
|
|
||||||
pass 语句不执行任何操作。语法上需要一个语句,但程序不实际执行任何动作时,可以使用该语句。例如:
|
`pass` 语句是 Python 中的空语句,用于在需要语句的地方保持语法的完整性,但是**实际上不做任何事情**。通常,我们使用它作为未完成代码的占位符:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
while True:
|
def my_function():
|
||||||
pass # Busy-wait for keyboard interrupt (Ctrl+C)
|
pass # TODO: implement this function
|
||||||
|
|
||||||
# 最小的类
|
|
||||||
class MyEmptyClass:
|
class MyEmptyClass:
|
||||||
pass
|
pass
|
||||||
|
|
||||||
# 三个点 等同于 pass
|
|
||||||
class MyEmptyClass:
|
|
||||||
...
|
|
||||||
```
|
|
||||||
|
|
||||||
### del
|
|
||||||
|
|
||||||
目标列表的删除将从左至右递归地删除每一个目标
|
|
||||||
|
|
||||||
```python
|
|
||||||
del a
|
|
||||||
del b[]
|
|
||||||
```
|
```
|
||||||
|
|
||||||
### return
|
### return
|
||||||
|
|
||||||
return 会离开当前函数调用,并以表达式列表 (或 None) 作为返回值。
|
`return` 语句用于从函数返回一个值。所有函数都会返回一个值:如果函数执行到结尾而没有遇到 `return` 语句,它将返回特殊值 `None`:
|
||||||
|
|
||||||
### yield
|
|
||||||
|
|
||||||
生成迭代器
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
def foo(num):
|
def add(a, b):
|
||||||
print("starting...")
|
return a + b
|
||||||
while num<10:
|
|
||||||
num=num+1
|
|
||||||
yield num
|
|
||||||
for n in foo(0):
|
|
||||||
print(n)
|
|
||||||
|
|
||||||
# 输出
|
print(add(1, 2)) # 输出:3
|
||||||
starting...
|
|
||||||
1
|
|
||||||
2
|
|
||||||
3
|
|
||||||
4
|
|
||||||
5
|
|
||||||
6
|
|
||||||
7
|
|
||||||
8
|
|
||||||
9
|
|
||||||
10
|
|
||||||
```
|
```
|
||||||
|
|||||||
@ -8,47 +8,183 @@ tags:
|
|||||||
- Python
|
- Python
|
||||||
sidebar_position: 2
|
sidebar_position: 2
|
||||||
author: 7Wate
|
author: 7Wate
|
||||||
date: 2022-11-19
|
date: 2023-08-03
|
||||||
---
|
---
|
||||||
|
|
||||||
## 内置类型
|
在编程领域,理解和掌握各种数据类型是任何编程语言的基础,Python 也不例外。Python 3 提供了多种内置数据类型,包括但不限于数字(整型、浮点型、复数)、布尔型、列表、元组、字符串、集合、字典等,还有函数、模块等高级类型。每种数据类型都有其特定的特性和适用场景。
|
||||||
|
|
||||||
**Python中的一切都是对象,变量是对象的引用!同时 Python 的动态语言特性变量和常量不需要事先声明类型。**
|
> 在Python中,变量可以被理解为一个标签(tag)或者标记,它是附着在特定对象上的名字。你可以将这个理念理解为在超市里的商品标签,标签告诉你这是什么商品,而商品是具体的物品。同样的,Python的变量名就像是一个标签,它告诉我们这个变量指向的是什么对象,而对象是存储在内存中的具体数据。
|
||||||
|
|
||||||
Python 不同于其他程序设计语言使用**存储期(存储空间生命周期)** 对变量和对象进行管理,Python 使用**引用计数**,即引用对象的变量个数,对变量和对象进行管理。
|
## 对象与类型
|
||||||
|
|
||||||
Python 可以使用 **id 函数**获取标识值(伪指针)、**type 函数**获取类型。
|
**在 Python 中,几乎所有的数据都可以被视为对象,每一个对象都有其相应的类型。**例如:
|
||||||
|
|
||||||
Python 中根据值是否可以改变,类型分为两类:
|
```python
|
||||||
|
print(type(123)) # <class 'int'>
|
||||||
|
print(type(3.14)) # <class 'float'>
|
||||||
|
print(type('hello')) # <class 'str'>
|
||||||
|
```
|
||||||
|
|
||||||
- **可变类型**:列表、字典、集合等。
|
**Python 是动态类型语言,我们不需要预先声明变量的类型。**在程序运行过程中,变量的类型可以根据赋值而改变。例如:
|
||||||
- **不可变类型**:数值、字符串、元组等。
|
|
||||||
|
|
||||||
如果对不可变类型的变量(引用的对象)的值进行变更、则会生成新的对象,然后变量重新引用新的对象。**赋值语句复制的是对象的引用而不是值。** *Python 的“变量”不同于其他程序语言的“变量”,Python 的“变量”翻译成“标志”更合适!*
|
```python
|
||||||
|
x = 123 # x 是一个整数
|
||||||
|
print(type(x)) # <class 'int'>
|
||||||
|
|
||||||
**Python 3 内置类型**如下,除了各种数据类型,Python 解释器内建了还有很多其他类型,比如上下文管理器类型,模块、方法、代码对象、类型对象、内部对象等类型。
|
x = 'hello' # x 变成了一个字符串
|
||||||
|
print(type(x)) # <class 'str'>
|
||||||
|
```
|
||||||
|
|
||||||
| 类型 | 可变性 | 描述 | 语法例子 |
|
Python中有两个内置函数`id`和`type`。
|
||||||
| :------------------------: | :------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
|
|
||||||
| `bool` | 不可变 | 布尔值 | `True` `False` |
|
- `id(obj)`函数:返回对象`obj`的唯一标识符,其实质上是该对象在内存中的地址。
|
||||||
| `int` | 不可变 | 理论上无限制大小的整数 | `42` |
|
- `type(obj)`函数:返回对象`obj`的类型。
|
||||||
| `float` | 不可变 | 双精度浮点数。精度是机器依赖的但实际上一般实现为 64 位IEEE 754 数而带有 53 位的精度 | `1.414` |
|
|
||||||
| `complex` | 不可变 | 复数,具有实部和虚部 | `3+2.7j` |
|
### 引用计数和垃圾收集
|
||||||
| `range` | 不可变 | 通常用在循环中的数的序列,规定在 for 循环中的次数 | `range(1, 10)` `range(10, -5, -2)` |
|
|
||||||
| `str` | 不可变 | 字符串,Unicode 代码点序列 | `'Wikipedia'` `"Wikipedia"` `"""Spanning multiple lines"""` |
|
Python 不依赖存储期(即对象在内存中存在的时间)来管理变量和对象,而是**使用引用计数。每个对象都会计算有多少个变量引用了它,当引用计数为 0 时,对象就会被垃圾收集器删除**。可以使用内置的 `id` 函数获取对象的标识(这实际上是该对象的内存地址),使用 `type` 函数获取对象的类型。
|
||||||
| `bytes` | 不可变 | 字节序列 | `b'Some ASCII'` `b"Some ASCII"` `bytes([119, 105, 107, 105])` |
|
|
||||||
| `bytearray` | **可变** | 字节序列 | `bytearray(b'Some ASCII')` `bytearray(b"Some ASCII")` `bytearray([119, 105, 107, 105])` |
|
```python
|
||||||
| `list` | **可变** | 列表,可以包含混合的类型 | `[4.0, 'string', True]` `[]` |
|
# 引用计数和垃圾收集的例子:
|
||||||
| `tuple` | 不可变 | 元组,可以包含混合的类型 | `(4.0, 'string', True)` `('single element',)` `()` |
|
# 在代码中,`sys.getrefcount(a)`可以获得对象`a`的引用计数。
|
||||||
| `dict` | **可变** | 键-值对的关联数组(或称字典);可以包含混合的类型(键和值),键必须是可散列的类型 | `{'key1': 1.0, 3: False}` `{}` |
|
# 当我们创建一个新的引用`b`时,`a`的引用计数增加1。
|
||||||
| `set` | **可变** | 无序集合,不包含重复项;可以包含混合的类型,如果可散列的话 | `{4.0, 'string', True}` `set()` |
|
# 当我们删除`b`时,`a`的引用计数减少1。
|
||||||
| `frozenset` | 不可变 | 无序集合,不包含重复项;可以包含混合的类型,如果可散列的话 | `frozenset([4.0, 'string', True])` |
|
|
||||||
| `types.EllipsisType` | 不可变 | 省略号占位符,用作 NumPy 数组的索引 | `...` `Ellipsis` |
|
import sys
|
||||||
| `types.NoneType` | 不可变 | 表示值缺席的对象,在其他语言中经常叫做 null | `None` |
|
|
||||||
| `types.NotImplementedType` | 不可变 | 可从重载运算符返回的占位符,用来指示未支持的运算数(operand)类型 | `NotImplemented` |
|
a = [] # 创建一个空列表
|
||||||
|
|
||||||
|
print(sys.getrefcount(a)) # 输出:2,一个引用来自 a,一个来自 getrefcount 的参数
|
||||||
|
|
||||||
|
b = a # 增加一个引用
|
||||||
|
|
||||||
|
print(sys.getrefcount(a)) # 输出:3,新增一个引用来自 b
|
||||||
|
|
||||||
|
b = None # 删除一个引用
|
||||||
|
|
||||||
|
print(sys.getrefcount(a)) # 输出:2,b 不再引用
|
||||||
|
```
|
||||||
|
|
||||||
|
### 可变类型、不可变类型
|
||||||
|
|
||||||
|
Python 中的数据类型可以分为两大类:可变类型与不可变类型。
|
||||||
|
|
||||||
|
- **可变类型**:值可以更改,如列表、字典和集合。
|
||||||
|
- **不可变类型**:值不可更改,如数字、字符串、元组等。
|
||||||
|
|
||||||
|
不可变类型的变量如果改变值,实际上是生成了一个新的对象,并使变量引用新的对象。Python的赋值语句复制的是对象的引用,而不是对象的值。因此,Python中的“变量”与其他编程语言中的“变量”不完全相同,将其翻译为“引用”可能更加合适。
|
||||||
|
|
||||||
|
```python
|
||||||
|
# 在代码中,`list1`是一个列表,是可变类型。
|
||||||
|
# 我们可以通过`append`方法修改`list1`,但是`list1`的`id`并未改变,说明`list1`还是同一个对象。
|
||||||
|
# `x`是一个整数,是不可变类型。当我们改变`x`的值时,`x`的`id`改变了,说明`x`现在是一个新的对象。
|
||||||
|
|
||||||
|
# 可变类型:列表
|
||||||
|
list1 = [1, 2, 3]
|
||||||
|
print(id(list1)) # 输出 list1 的 id
|
||||||
|
list1.append(4) # 修改 list1
|
||||||
|
print(id(list1)) # id 没有改变
|
||||||
|
|
||||||
|
# 不可变类型:整数
|
||||||
|
x = 1
|
||||||
|
print(id(x)) # 输出 x 的 id
|
||||||
|
x = x + 1 # 修改 x
|
||||||
|
print(id(x)) # id 改变了
|
||||||
|
```
|
||||||
|
|
||||||
|
## Python3 内置类型
|
||||||
|
|
||||||
|
Python 3内置了多种数据类型,同时还内建了许多其他类型,如上下文管理器类型、模块、方法、代码对象、类型对象、内部对象等。
|
||||||
|
|
||||||
|
### 数字类型
|
||||||
|
|
||||||
|
数字类型主要用于存储和处理数值。这包括整数、浮点数、复数和布尔类型。
|
||||||
|
|
||||||
|
| 类型 | 描述 | 示例 | 可变性 |
|
||||||
|
| ------- | ---------------------------------- | ---------------------- | ------ |
|
||||||
|
| int | 整数,无论大小都可以是正数或负数。 | `123`, `-456`, `0` | 不可变 |
|
||||||
|
| float | 浮点数,包含小数部分的数字。 | `3.14`, `-0.01`, `9.0` | 不可变 |
|
||||||
|
| complex | 复数,包含实部和虚部的数字。 | `1+2j`, `3-4j` | 不可变 |
|
||||||
|
|
||||||
|
### 布尔类型
|
||||||
|
|
||||||
|
| 类型 | 描述 | 示例 | 可变性 |
|
||||||
|
| ---- | ---------------------- | --------------- | ------ |
|
||||||
|
| bool | 布尔,表示真或假的值。 | `True`, `False` | 不可变 |
|
||||||
|
|
||||||
|
### 序列类型
|
||||||
|
|
||||||
|
序列类型是一种有序的元素集合,包括字符串、列表和元组。每个元素都有一个相应的索引,可以通过索引来访问。
|
||||||
|
|
||||||
|
| 类型 | 描述 | 示例 | 可变性 |
|
||||||
|
| ----- | ---------------------------------------- | -------------------------- | ------ |
|
||||||
|
| str | 字符串,由零个或多个字符组成的文本。 | `'hello'`, `"world"`, `''` | 不可变 |
|
||||||
|
| list | 列表,由一系列按特定顺序排列的元素组成。 | `[1, 'two', 3.0]` | 可变 |
|
||||||
|
| tuple | 元组,类似于列表,但元素不可更改。 | `(1, 'two', 3.0)` | 不可变 |
|
||||||
|
|
||||||
|
### 集合类型
|
||||||
|
|
||||||
|
集合类型是一个无序的元素集合,其中的元素都是唯一的。这包括集合和冻结集合。
|
||||||
|
|
||||||
|
| 类型 | 描述 | 示例 | 可变性 |
|
||||||
|
| --------- | ---------------------------------------- | ---------------------------- | ------ |
|
||||||
|
| set | 集合,一组无序的、不重复的元素。 | `{1, 'two', 3.0}` | 可变 |
|
||||||
|
| frozenset | 不可变集合,类似于集合,但元素不可更改。 | `frozenset({1, 'two', 3.0})` | 不可变 |
|
||||||
|
|
||||||
|
### 映射类型
|
||||||
|
|
||||||
|
映射类型是一个存储键值对的元素集合,其中的键是唯一的。字典就是一个映射类型。
|
||||||
|
|
||||||
|
| 类型 | 描述 | 示例 | 可变性 |
|
||||||
|
| ---- | ---------------------------- | ----------------------------- | ------ |
|
||||||
|
| dict | 字典,包含键值对的数据结构。 | `{'name': 'John', 'age': 25}` | 可变 |
|
||||||
|
|
||||||
|
### 特殊类型
|
||||||
|
|
||||||
|
| 类型 | 描述 | 示例 | 可变性 |
|
||||||
|
| ------------------ | ------------------------------------------------------ | ------------------- | ------ |
|
||||||
|
| NoneType | 表示None的特殊类型。 | `None` | 不可变 |
|
||||||
|
| EllipsisType | 表示省略的特殊类型,主要在切片和NumPy库中使用。 | `Ellipsis` 或 `...` | 不可变 |
|
||||||
|
| NotImplementedType | 表示未实现方法的特殊类型,主要在自定义比较方法中使用。 | `NotImplemented` | 不可变 |
|
||||||
|
|
||||||
|
### 二进制类型
|
||||||
|
|
||||||
|
| 类型 | 描述 | 示例 | 可变性 |
|
||||||
|
| ---------- | ------------------------------------------------------------ | ------------------------- | -------------- |
|
||||||
|
| bytes | 字节,包含零个或多个范围为0<=x<256的整数的不可变序列。 | `b'hello'`, `b'\x01\x02'` | 不可变 |
|
||||||
|
| bytearray | 字节数组,包含零个或多个范围为0<=x<256的整数的可变序列。 | `bytearray(b'hello')` | 可变 |
|
||||||
|
| memoryview | 内存查看,用于访问其他二进制序列、打包的数组和缓冲区的内部数据。 | `memoryview(b'hello')` | 依据所查看对象 |
|
||||||
|
|
||||||
|
### 类、实例和异常
|
||||||
|
|
||||||
|
| 类型 | 描述 | 示例 | 可变性 |
|
||||||
|
| --------- | ------------------------ | --------------------------- | ---------- |
|
||||||
|
| object | 对象,所有类的基类。 | `obj = object()` | 依据具体类 |
|
||||||
|
| exception | 异常,程序运行时的错误。 | `raise Exception('Error!')` | 不可变 |
|
||||||
|
|
||||||
|
### 其他内置类型
|
||||||
|
|
||||||
|
| 类型 | 描述 | 示例 | 可变性 |
|
||||||
|
| --------- | ----------------------------------------------------------- | ------------------------------ | ------ |
|
||||||
|
| function | 函数,包含一系列指令的代码块。 | `def greet(): print('Hello!')` | 不可变 |
|
||||||
|
| type | 类型,表示对象的类型。 | `type(123)` | 不可变 |
|
||||||
|
| generator | 生成器,一种可迭代的对象,由函数定义并使用 `yield` 产生值。 | `(x**2 for x in range(10))` | 不可变 |
|
||||||
|
|
||||||
## 类型转换
|
## 类型转换
|
||||||
|
|
||||||
|
Python提供了多种函数,用于在不同类型之间进行转换:
|
||||||
|
|
||||||
|
```Python
|
||||||
|
x = "123" # 这是一个字符串
|
||||||
|
print(type(x)) # <class 'str'>
|
||||||
|
|
||||||
|
x = int(x) # 将字符串转为整数
|
||||||
|
print(type(x)) # <class 'int'>
|
||||||
|
|
||||||
|
x = float(x) # 将整数转为浮点数
|
||||||
|
print(type(x)) # <class 'float'>
|
||||||
|
```
|
||||||
|
|
||||||
| 函数 | 描述 |
|
| 函数 | 描述 |
|
||||||
| :-------------------- | :-------------------------------------------------- |
|
| :-------------------- | :-------------------------------------------------- |
|
||||||
| int(x [,base]) | 将x转换为一个整数 |
|
| int(x [,base]) | 将x转换为一个整数 |
|
||||||
@ -60,7 +196,7 @@ Python 中根据值是否可以改变,类型分为两类:
|
|||||||
| tuple(s) | 将序列 s 转换为一个元组 |
|
| tuple(s) | 将序列 s 转换为一个元组 |
|
||||||
| list(s) | 将序列 s 转换为一个列表 |
|
| list(s) | 将序列 s 转换为一个列表 |
|
||||||
| set(s) | 转换为可变集合 |
|
| set(s) | 转换为可变集合 |
|
||||||
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
|
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列 |
|
||||||
| frozenset(s) | 转换为不可变集合 |
|
| frozenset(s) | 转换为不可变集合 |
|
||||||
| chr(x) | 将一个整数转换为一个字符 |
|
| chr(x) | 将一个整数转换为一个字符 |
|
||||||
| ord(x) | 将一个字符转换为它的整数值 |
|
| ord(x) | 将一个字符转换为它的整数值 |
|
||||||
@ -71,6 +207,30 @@ Python 中根据值是否可以改变,类型分为两类:
|
|||||||
|
|
||||||
在实际开发中,如果搞不清楚运算符的优先级,可以**使用括号来确保运算的执行顺序**。
|
在实际开发中,如果搞不清楚运算符的优先级,可以**使用括号来确保运算的执行顺序**。
|
||||||
|
|
||||||
|
```python
|
||||||
|
# 运算符
|
||||||
|
a = 10
|
||||||
|
b = 20
|
||||||
|
|
||||||
|
print(a + b) # 加法,输出: 30
|
||||||
|
print(a - b) # 减法,输出: -10
|
||||||
|
print(a * b) # 乘法,输出: 200
|
||||||
|
print(a / b) # 除法,输出: 0.5
|
||||||
|
print(a ** 2) # 幂运算,输出: 100
|
||||||
|
print(a % 3) # 取模,输出: 1
|
||||||
|
|
||||||
|
# 逻辑运算符
|
||||||
|
print(a > b) # 大于,输出: False
|
||||||
|
print(a < b) # 小于,输出: True
|
||||||
|
print(a == b) # 等于,输出: False
|
||||||
|
print(a != b) # 不等于,输出: True
|
||||||
|
|
||||||
|
# 成员运算符
|
||||||
|
s = 'Hello World'
|
||||||
|
print('World' in s) # 输出: True
|
||||||
|
print('Python' not in s) # 输出: True
|
||||||
|
```
|
||||||
|
|
||||||
| 运算符 | 描述 |
|
| 运算符 | 描述 |
|
||||||
| ------------------------------------------------------------ | ------------------------------ |
|
| ------------------------------------------------------------ | ------------------------------ |
|
||||||
| `[]` `[:]` | 下标,切片 |
|
| `[]` `[:]` | 下标,切片 |
|
||||||
@ -86,29 +246,4 @@ Python 中根据值是否可以改变,类型分为两类:
|
|||||||
| `is` `is not` | 身份运算符 |
|
| `is` `is not` | 身份运算符 |
|
||||||
| `in` `not in` | 成员运算符 |
|
| `in` `not in` | 成员运算符 |
|
||||||
| `not` `or` `and` | 逻辑运算符 |
|
| `not` `or` `and` | 逻辑运算符 |
|
||||||
| `=` `+=` `-=` `*=` `/=` `%=` `//=` `**=` `&=` `| =` `^=` `>>=` `<<=` | 赋值运算符 |
|
| `=` `+=` `-=` `*=` `/=` `%=` `//=` `**=` `&=` `| =``^=``>>=``<<=` | 赋值运算符 |
|
||||||
|
|
||||||
## 关键字
|
|
||||||
|
|
||||||
Python 的标准库提供了一个 keyword 模块,可以输出当前版本的所有关键字:
|
|
||||||
|
|
||||||
```python
|
|
||||||
$ import keyword
|
|
||||||
$ print(keyword.kwlist)
|
|
||||||
|
|
||||||
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
|
|
||||||
```
|
|
||||||
|
|
||||||
## 声明
|
|
||||||
|
|
||||||
**硬性规则:**
|
|
||||||
|
|
||||||
- 变量名由**字母**(广义的Unicode字符,不包括特殊字符)、**数字**和**下划线**构成,**数字不能开头**。
|
|
||||||
- **大小写敏感**(大写的`a`和小写的`A`是两个不同的变量)。
|
|
||||||
- 不要跟**关键字**(有特殊含义的单词,后面会讲到)和系统保留字(如函数、模块等的名字)冲突。
|
|
||||||
|
|
||||||
**PEP 8要求:**
|
|
||||||
|
|
||||||
- 用小写字母拼写,多个单词用下划线连接。
|
|
||||||
- 受保护的实例属性用单个下划线开头(后面会讲到)。
|
|
||||||
- 私有的实例属性用两个下划线开头(后面会讲到)。
|
|
||||||
|
|||||||
File diff suppressed because it is too large
Load Diff
@ -8,46 +8,37 @@ tags:
|
|||||||
- Python
|
- Python
|
||||||
sidebar_position: 7
|
sidebar_position: 7
|
||||||
author: 7Wate
|
author: 7Wate
|
||||||
date: 2022-11-28
|
date: 2023-08-03
|
||||||
---
|
---
|
||||||
在编程语言中,代码块、函数、类、模块,一直到包,逐级封装,层层调用。**在 Python 中,一个`.py`文件就是一个模块,模块是比类更高一级的封装。**在其他语言,被导入的模块也通常称为库。
|
在编程语言中,我们常常会看到各种不同级别的封装,如代码块、函数、类、模块,甚至包,每个级别都会进行逐级调用。**在Python中,一个`.py`文件就被看作是一个模块,这实际上是比类级别更高的封装。**在其他的编程语言中,被导入的模块通常被称为库。
|
||||||
|
|
||||||
## 模块
|
## 模块
|
||||||
|
|
||||||
**模块可以分为自定义模块、内置模块和第三方模块**。使用模块有什么好处?
|
在 Python 中,模块可以分为**自定义模块、内置模块(标准模块)和第三方模块。**使用模块主要有以下几个好处:
|
||||||
|
|
||||||
- 首先,提高了代码的可维护性。
|
- **提高了代码的可维护性。**通过将代码拆分为多个模块,可以降低每个模块的复杂性,更容易进行理解和维护。
|
||||||
- 其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他的模块引用。不要重复造轮子,我们简简单单地使用已经有的模块就好了。
|
- **重用代码。**当一个模块编写完毕,就可以被其他的模块引用。这避免了“重复造轮子”,允许开发者更加专注于新的任务。
|
||||||
- 使用模块还可以避免类名、函数名和变量名发生冲突。相同名字的类、函数和变量完全可以分别存在不同的模块中。但是也要注意尽量不要与内置函数名(类名)冲突。
|
- **避免命名冲突。**同名的类、函数和变量可以分别存在于不同的模块中,防止名称冲突。但也要注意尽量避免与内置函数名(类名)冲突。
|
||||||
|
|
||||||
### 自定义模块
|
### 自定义模块
|
||||||
|
|
||||||
自主开发完成复用的模块。
|
自定义模块是开发者根据实际需求编写的代码,封装为模块方便在多个地方使用。
|
||||||
|
|
||||||
### 标准模块
|
### 标准模块
|
||||||
|
|
||||||
Python 拥有一个强大的标准库。Python语言的核心只包含数值、字符串、列表、字典、文件等常见类型和函数,而由 Python 标准库提供了系统管理、网络通信、文本处理、数据库接口、图形系统、XML 处理等额外的功能。
|
Python 拥有一个强大的标准库。Python语言的核心只包含数值、字符串、列表、字典、文件等常见类型和函数,而由 Python 标准库提供了系统管理、网络通信、文本处理、数据库接口、图形系统、XML 处理等额外的功能。如文本处理、文件系统操作、操作系统功能、网络通信、W3C 格式支持等。
|
||||||
|
|
||||||
Python 标准库的主要功能有:
|
|
||||||
|
|
||||||
- 文本处理,包含文本格式化、正则表达式、文本差异计算与合并、Unicode 支援,二进制数据处理等功能。
|
|
||||||
- 文件系统功能,包含文件和目录操作、建立临时文件、文件压缩与归档、操作配置文件等功能。
|
|
||||||
- 操作系统功能,包含线程与进程支持、IO 复用、日期与时间处理、调用系统函数、日志(logging)等功能。
|
|
||||||
- 网络通信,包含网络套接字,SSL 加密通信、异步网络通信等功能。支持 HTTP,FTP,SMTP,POP,IMAP,NNTP,XMLRPC 等多种网络协议,并提供了编写网络服务器的框架。
|
|
||||||
- W3C 格式支持,包含 HTML,SGML,XML 的处理。
|
|
||||||
- 其它功能,包括国际化支持、数学运算、HASH、Tkinter 等。
|
|
||||||
|
|
||||||
### 第三方模块
|
### 第三方模块
|
||||||
|
|
||||||
Python 拥有大量的第三方模块,这也是其核心优点之一。基本上,所有的第三方模块都会在[PyPI - the Python Package Index](https://pypi.python.org/)上注册,只要找到对应的模块名字,即可用 pip 安装。
|
Python 拥有大量的第三方模块,这也是其核心优点之一。这些模块通常在 Python 包管理系统 [PyPI](https://pypi.python.org/) 中注册,你可以通过 pip 工具来安装。
|
||||||
|
|
||||||
## 包
|
## 包
|
||||||
|
|
||||||
Python 为了避免模块名冲突,又引入了按目录来组织模块的方法,称为包(Package),**包是模块的集合,比模块又高一级的封装。**包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。**包名通常为全部小写,避免使用下划线。**
|
Python 为了避免模块名冲突,又引入了按目录来组织模块的方法,称为包(Package)。**包是模块的集合,比模块又高一级的封装。**包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。**一般来说,包名通常为全部小写,避免使用下划线。**
|
||||||
|
|
||||||
### 标准包
|
### 标准包
|
||||||
|
|
||||||
简单来说标准包就是文件夹下必须存在 `__init__.py` 文件,该文件的内容可以为空。如果没有该文件,Python 无法识别出标准包。Python 中导入包后会初始化并执行 `__init__.py` 进行初始化;在 `__init__.py` 中,如果将`__all__` 定义为列表,其中包含对象名称的字符串,程序就可以通过 * 的方式导入。
|
标准包就是文件夹下必须存在 `__init__.py` 文件,该文件的内容可以为空。如果没有该文件,Python 无法识别出标准包。Python 中导入包后会初始化并执行 `__init__.py` 进行初始化;在 `__init__.py` 中,如果将`__all__` 定义为列表,其中包含对象名称的字符串,程序就可以通过 * 的方式导入。
|
||||||
|
|
||||||
```markdown
|
```markdown
|
||||||
test.py
|
test.py
|
||||||
@ -85,80 +76,55 @@ runoob2()
|
|||||||
# I'm in runoob2
|
# I'm in runoob2
|
||||||
```
|
```
|
||||||
|
|
||||||
## import
|
## 模块和包的导入
|
||||||
|
|
||||||
`import` 语句不带 `from` 会分两步执行:
|
Python 模块是一个包含 Python 定义和语句的文件,模块可以定义函数,类和变量。模块也可以包含可执行的代码。**包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。**
|
||||||
|
|
||||||
1. 查找一个模块,如果有必要还会加载并初始化模块。
|
### 导入方式
|
||||||
|
|
||||||
2. 在局部命名空间中为 import 语句发生位置所处的作用域定义一个或多个名称。
|
在Python中,可以通过以下四种方式导入模块或包:
|
||||||
|
|
||||||
from 形式使用的过程略微繁复一些:
|
#### `import xx.xx`
|
||||||
|
|
||||||
1. 查找 from 子句中指定的模块,如有必要还会加载并初始化模块;
|
这种方式将整个模块导入。如果模块中有函数、类或变量,我们需要以`module.xxx`的方式调用。
|
||||||
|
|
||||||
2. 对于 import 子句中指定的每个标识符:
|
|
||||||
1. 检查被导入模块是否有该名称的属性。
|
|
||||||
2. 如果没有,尝试导入具有该名称的子模块,然后再次检查被导入模块是否有该属性。
|
|
||||||
3. 如果未找到该属性,则引发 ImportError。
|
|
||||||
4. 否则的话,将对该值的引用存入局部命名空间,如果有 as 子句则使用其指定的名称,否则使用该属性的名称。
|
|
||||||
|
|
||||||
```python
|
|
||||||
# Python 中,模块(包、类、函数)的导入方式有以下四种:
|
|
||||||
import xx.xx
|
|
||||||
from xx.xx import xx
|
|
||||||
from xx.xx import xx as rename
|
|
||||||
from xx.xx import *
|
|
||||||
```
|
|
||||||
|
|
||||||
### import xx.xx
|
|
||||||
|
|
||||||
将对象(这里的对象指的是包、模块、类或者函数,下同)中的所有内容导入。如果该对象是个模块,那么调用对象内的类、函数或变量时,需要以`module.xxx`的方式。
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
# Module_a.py
|
# Module_a.py
|
||||||
|
|
||||||
def func():
|
def func():
|
||||||
print("this is module A!")
|
print("This is module A!")
|
||||||
|
|
||||||
# Main.py
|
# Main.py
|
||||||
|
|
||||||
import module_a
|
import module_a
|
||||||
module_a.func() # 调用方法
|
module_a.func() # 调用函数
|
||||||
```
|
```
|
||||||
|
|
||||||
### from xx.xx import xx.xx
|
#### `from xx.xx import xx`
|
||||||
|
|
||||||
从某个对象内导入某个指定的部分到当前命名空间中,不会将整个对象导入。这**种方式可以节省写长串导入路径的代码,但要小心名字冲突**。
|
这种方式从某个模块中导入某个指定的部分到当前命名空间,不会将整个模块导入。这种方式可以节省代码量,但需要注意避免名字冲突。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
# Main.py
|
# Main.py
|
||||||
|
|
||||||
from module_a import func
|
from module_a import func
|
||||||
|
func() # 直接调用 func
|
||||||
module_a.func() # 错误的调用方式
|
|
||||||
func() # 这时需要直接调用 func
|
|
||||||
```
|
```
|
||||||
|
|
||||||
### from xx.xx import xx as rename
|
#### `from xx.xx import xx as rename`
|
||||||
|
|
||||||
为了避免命名冲突,在导入的时候,可以给导入的对象重命名。
|
为了避免命名冲突,我们可以在导入时重命名模块。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
# Main.py
|
# Main.py
|
||||||
|
|
||||||
from module_a import func as f
|
from module_a import func as f
|
||||||
|
f() # 使用新名称 f 来调用函数
|
||||||
def func(): # main 模块内部已经有了 func 函数
|
|
||||||
print("this is main module!")
|
|
||||||
|
|
||||||
func()
|
|
||||||
f()
|
|
||||||
```
|
```
|
||||||
|
|
||||||
### from xx.xx import *
|
#### `from xx.xx import \*`
|
||||||
|
|
||||||
将对象内的所有内容全部导入。非常容易发生命名冲突,请慎用!
|
这种方式将模块中的所有内容全部导入,非常容易发生命名冲突,因此需要谨慎使用。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
# Main.py
|
# Main.py
|
||||||
@ -166,88 +132,93 @@ f()
|
|||||||
from module_a import *
|
from module_a import *
|
||||||
|
|
||||||
def func():
|
def func():
|
||||||
print("this is main module!")
|
print("This is the main module!")
|
||||||
|
|
||||||
func() # 从 module 导入的 func 被 main 的 func 覆盖了
|
func() # func 从 module_a 导入被 main 中的 func 覆盖
|
||||||
```
|
```
|
||||||
|
|
||||||
### 模块路径搜索顺序
|
### 模块路径搜索顺序
|
||||||
|
|
||||||
**不管在程序中执行了多少次import,一个模块只会被导入一次。**导入一个模块,Python 解析器对模块位置的搜索顺序是:
|
当我们尝试导入一个模块时,Python 解释器对模块位置的搜索顺序是:
|
||||||
|
|
||||||
1. Python 项目当前目录
|
1. Python 项目的当前目录
|
||||||
2. Python 搜索在 shell 变量 PYTHONPATH 下的每个目录。
|
2. 在环境变量 PYTHONPATH 中列出的所有目录
|
||||||
3. Python 默认搜索路径。UNIX下,默认路径一般为 /usr/local/lib/python/。
|
3. Python 的安装目录和其他默认目录
|
||||||
|
|
||||||
模块搜索路径存储在 system 模块的 sys.path 变量中。变量里包含当前目录,PYTHONPATH 由安装过程决定的默认目录。
|
模块搜索路径存储在`sys`模块的`sys.path`变量中。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
import sys
|
import sys
|
||||||
print(sys.path)
|
print(sys.path)
|
||||||
|
|
||||||
# ['/workspace/PythonStudy', '/usr/local/lib/python310.zip', '/usr/local/lib/python3.10', '/usr/local/lib/python3.10/lib-dynload', '/home/user/.local/lib/python3.10/site-packages']
|
|
||||||
```
|
```
|
||||||
|
|
||||||
## 命名空间
|
## 命名空间和作用域
|
||||||
|
|
||||||
命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是通过 Python 字典来实现的。
|
在Python中,命名空间(Namespace)是从名称到对象的映射,主要用于避免命名冲突。命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。
|
||||||
|
|
||||||
命名空间提供了在项目中避免名字冲突的一种方法。各个命名空间是独立的,没有任何关系的,所以一个命名空间中不能有重名,但不同的命名空间是可以重名而没有任何影响。
|
### 命名空间类型
|
||||||
|
|
||||||
一般有三种命名空间:
|
|
||||||
|
|
||||||
- **内置名称(built-in names**):Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。
|
|
||||||
- **全局名称(global names)**:模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
|
|
||||||
- **局部名称(local names)**:函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
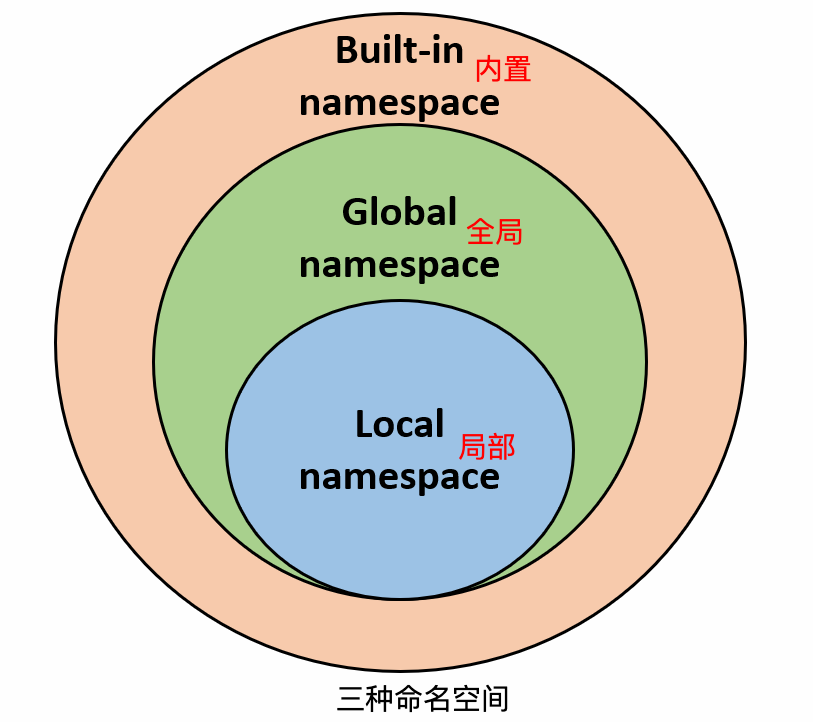
假设我们要使用变量 runoob,则 **Python 的查找顺序为:局部的命名空间 -> 全局命名空间 -> 内置命名空间。**
|
Python有三种命名空间:
|
||||||
|
|
||||||
如果找不到变量 runoob,它将放弃查找并引发一个 NameError 异常:`NameError: name 'runoob' is not defined。`
|
- **内置名称(built-in names)**:Python语言内置的名称,如函数名`abs`、`char`和异常名称`BaseException`、`Exception`等。
|
||||||
|
- **全局名称(global names)**:模块中定义的名称,包括模块的函数、类、导入的模块、模块级别的变量和常量。
|
||||||
|
- **局部名称(local names)**:函数中定义的名称,包括函数的参数和局部定义的变量。
|
||||||
|
|
||||||
### 生命周期
|
### 作用域
|
||||||
|
|
||||||
命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。因此,我们**无法从外部命名空间访问内部命名空间的对象。**
|
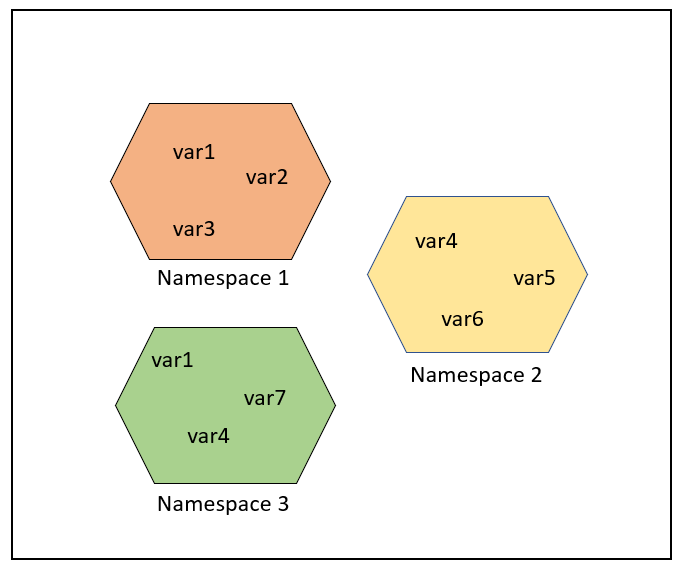
作用域定义了命名空间可以直接访问的代码段,决定了在哪一部分程序可以访问特定的变量名。Python的作用域一共有4种,分别是:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
```python
|
|
||||||
# var1 是全局名称
|
|
||||||
var1 = 5
|
|
||||||
def some_func():
|
|
||||||
|
|
||||||
# var2 是局部名称
|
|
||||||
var2 = 6
|
|
||||||
def some_inner_func():
|
|
||||||
|
|
||||||
# var3 是内嵌的局部名称
|
|
||||||
var3 = 7
|
|
||||||
```
|
|
||||||
|
|
||||||
## 作用域
|
|
||||||
|
|
||||||
作用域就是一个 Python 程序可以直接访问命名空间的正文区域。
|
|
||||||
|
|
||||||
在一个 python 程序中,直接访问一个变量,会从内到外依次访问所有的作用域直到找到,否则会报未定义的错误。
|
|
||||||
|
|
||||||
Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。
|
|
||||||
|
|
||||||
变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。Python 的作用域一共有4种,分别是:
|
|
||||||
|
|
||||||
- **L(Local)**:最内层,包含局部变量,比如一个函数/方法内部。
|
|
||||||
- **E(Enclosing)**:包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
|
|
||||||
- **G(Global)**:当前脚本的最外层,比如当前模块的全局变量。
|
|
||||||
- **B(Built-in)**: 包含了内建的变量 / 关键字等,最后被搜索。
|
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
规则顺序: **L –> E –> G –> B**。
|
- **L(Local)**:最内层,包含局部变量,比如一个函数/方法内部。
|
||||||
|
- **E(Enclosing)**:包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类)A里面又包含了一个函数B,那么对于B中的名称来说A中的作用域就为nonlocal。
|
||||||
|
- **G(Global)**:当前脚本的最外层,比如当前模块的全局变量。
|
||||||
|
- **B(Built-in)**: 包含了内建的变量/关键字等,最后被搜索。
|
||||||
|
|
||||||
|
变量的查找顺序是:L --> E --> G --> B。
|
||||||
|
|
||||||
|
### 代码示例
|
||||||
|
|
||||||
```python
|
```python
|
||||||
g_count = 0 # 全局作用域
|
# 全局变量
|
||||||
|
x = 10
|
||||||
|
z = 40
|
||||||
|
|
||||||
|
# 定义函数 foo
|
||||||
|
def foo():
|
||||||
|
# 局部变量
|
||||||
|
x = 20
|
||||||
|
z = 50
|
||||||
|
|
||||||
|
def bar():
|
||||||
|
nonlocal z
|
||||||
|
print("局部变量 z =", z) # 输出 "局部变量 z = 50"
|
||||||
|
|
||||||
|
def baz():
|
||||||
|
global z
|
||||||
|
print("全局变量 z =", z) # 输出 "全局变量 z = 40"
|
||||||
|
|
||||||
|
print("局部变量 x =", x) # 输出 "局部变量 x = 20"
|
||||||
|
bar()
|
||||||
|
baz()
|
||||||
|
|
||||||
|
# 定义函数 outer
|
||||||
def outer():
|
def outer():
|
||||||
o_count = 1 # 闭包函数外的函数中
|
y = 30 # 封闭作用域变量
|
||||||
|
|
||||||
def inner():
|
def inner():
|
||||||
i_count = 2 # 局部作用域
|
nonlocal y
|
||||||
|
print("封闭作用域 y =", y) # 输出 "封闭作用域 y = 30"
|
||||||
|
|
||||||
|
inner()
|
||||||
|
|
||||||
|
# 执行函数
|
||||||
|
foo()
|
||||||
|
print("全局变量 x =", x) # 输出 "全局变量 x = 10"
|
||||||
|
outer()
|
||||||
|
|
||||||
|
# 调用内置函数
|
||||||
|
print(abs(-5)) # 输出 5
|
||||||
```
|
```
|
||||||
|
|||||||
File diff suppressed because it is too large
Load Diff
Loading…
Reference in New Issue
Block a user