2022-01-27 17:58:05 +08:00
|
|
|
|
---
|
2022-02-10 17:58:49 +08:00
|
|
|
|
title: 数据结构
|
2022-11-20 19:10:55 +08:00
|
|
|
|
description: Python 数据结构
|
|
|
|
|
|
keywords:
|
|
|
|
|
|
- Python
|
|
|
|
|
|
- 数据结构
|
|
|
|
|
|
tags:
|
|
|
|
|
|
- Python
|
2022-11-19 21:18:21 +08:00
|
|
|
|
sidebar_position: 4
|
2022-11-20 19:10:55 +08:00
|
|
|
|
author: 7Wate
|
|
|
|
|
|
date: 2022-11-20
|
2022-01-27 17:58:05 +08:00
|
|
|
|
---
|
|
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
## 数字
|
|
|
|
|
|
|
|
|
|
|
|
Python 数字数据类型用于存储数值。数据类型是不允许改变的,这就意味着如果改变数字数据类型的值,将重新分配内存空间。Python 支持三种不同的数值类型:
|
|
|
|
|
|
|
|
|
|
|
|
- **整型(int)** - 通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用,所以 Python3 没有 Python2 的 Long 类型。布尔(bool)是整型的子类型。
|
|
|
|
|
|
- **浮点型(float)** - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
|
|
|
|
|
|
- **复数( (complex))** - 复数由实数部分和虚数部分构成,可以用 a + bj,或者 complex(a,b) 表示, 复数的实部 a 和虚部 b 都是浮点型。
|
|
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
|
num1 = -100 # 整数
|
|
|
|
|
|
num2 = 200.01 # 浮点数
|
|
|
|
|
|
num3 = 0xA0F # 十六进制
|
|
|
|
|
|
num4 = 0o37 # 八进制
|
|
|
|
|
|
|
|
|
|
|
|
# 数学常量 PI 和 e
|
|
|
|
|
|
pi
|
|
|
|
|
|
e
|
|
|
|
|
|
|
|
|
|
|
|
# 绝对值
|
|
|
|
|
|
abs(num1)
|
|
|
|
|
|
|
|
|
|
|
|
# 向上取整
|
|
|
|
|
|
ceil(num2)
|
|
|
|
|
|
|
|
|
|
|
|
# 返回最大数
|
|
|
|
|
|
max(num1, num2)
|
|
|
|
|
|
|
|
|
|
|
|
# x**y 运算后的值
|
|
|
|
|
|
pow(num1, num2)
|
|
|
|
|
|
|
|
|
|
|
|
# 随机数
|
|
|
|
|
|
random.random()
|
|
|
|
|
|
|
|
|
|
|
|
# x弧度的正弦值。
|
|
|
|
|
|
sin(x)
|
|
|
|
|
|
```
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
2022-02-10 17:58:49 +08:00
|
|
|
|
## 字符串
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
|
|
|
|
|
所谓**字符串**,就是由零个或多个字符组成的有限序列。在Python程序中,如果我们把单个或多个字符用单引号或者双引号包围起来,就可以表示一个字符串。
|
|
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
- 单引号 **'** 和双引号 **"** 使用完全相同。
|
|
|
|
|
|
- 三引号(**'''** 或 **"""**)可以指定一个多行字符串。
|
|
|
|
|
|
- 反斜杠 **\\** 可以用来转义,使用 **r** 可以让反斜杠不发生转义。
|
|
|
|
|
|
- 字面意义级联字符串:如 **"this " "is " "string"** 会被自动转换为 **this is string**。
|
|
|
|
|
|
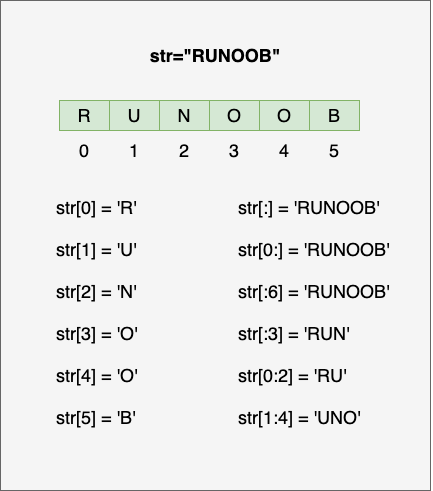
- 字符串有两种索引方式,从左往右以 **0** 开始,从右往左以 **-1** 开始。
|
|
|
|
|
|
- 字符串不能改变,一个字符就是长度为 1 的字符串。
|
|
|
|
|
|
- 字符串的截取的语法格式如下:**变量[头下标:尾下标:步长]**
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
```python
|
2022-02-11 16:28:35 +08:00
|
|
|
|
# 单引号、双引号字符串
|
2022-01-27 17:58:05 +08:00
|
|
|
|
s1 = 'hello, world!'
|
|
|
|
|
|
s2 = "hello, world!"
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 以三个双引号或单引号开头的字符串可以折行
|
|
|
|
|
|
s3 = """
|
|
|
|
|
|
hello,
|
|
|
|
|
|
world!
|
|
|
|
|
|
"""
|
|
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 在字符串中使用 \(反斜杠)来表示转义
|
2022-02-11 16:28:35 +08:00
|
|
|
|
s4 = '\n\t\141\u9a86\u660a'
|
|
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 字符串开头使用 r 来取消转义
|
2022-02-11 16:28:35 +08:00
|
|
|
|
s5 = r'\n\\hello, world!\\\n'
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 输出:\n\\hello, world!\\\n
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 级联字符串
|
|
|
|
|
|
s6 = "this " "is " "string"
|
|
|
|
|
|
# 输出:this is string
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 字符串无法改变
|
|
|
|
|
|
s6[2] = "c"
|
|
|
|
|
|
# 输出:错误!
|
|
|
|
|
|
```
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
### 转义
|
|
|
|
|
|
|
|
|
|
|
|
| 转义字符 | 描述 | 实例 |
|
|
|
|
|
|
| :---------- | :----------------------------------------------------------- | :----------------------------------------------------------- |
|
|
|
|
|
|
| \(在行尾时) | 续行符 | `>>> print("line1 \ ... line2 \ ... line3") line1 line2 line3 >>> ` |
|
|
|
|
|
|
| \\ | 反斜杠符号 | `>>> print("\\") \` |
|
|
|
|
|
|
| \' | 单引号 | `>>> print('\'') '` |
|
|
|
|
|
|
| \" | 双引号 | `>>> print("\"") "` |
|
|
|
|
|
|
| \a | 响铃 | `>>> print("\a")`执行后电脑有响声。 |
|
|
|
|
|
|
| \b | 退格(Backspace) | `>>> print("Hello \b World!") Hello World!` |
|
|
|
|
|
|
| \000 | 空 | `>>> print("\000") >>> ` |
|
|
|
|
|
|
| \n | 换行 | `>>> print("\n") >>>` |
|
|
|
|
|
|
| \v | 纵向制表符 | `>>> print("Hello \v World!") Hello World! >>>` |
|
|
|
|
|
|
| \t | 横向制表符 | `>>> print("Hello \t World!") Hello World! >>>` |
|
|
|
|
|
|
| \r | 回车,将 **\r** 后面的内容移到字符串开头,并逐一替换开头部分的字符,直至将 **\r** 后面的内容完全替换完成。 | `>>> print("Hello\rWorld!") World! >>> print('google runoob taobao\r123456') 123456 runoob taobao` |
|
|
|
|
|
|
| \f | 换页 | `>>> print("Hello \f World!") Hello World! >>> ` |
|
|
|
|
|
|
| \yyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 | `>>> print("\110\145\154\154\157\40\127\157\162\154\144\41") Hello World!` |
|
|
|
|
|
|
| \xyy | 十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 | `>>> print("\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21") Hello World!` |
|
|
|
|
|
|
| \other | 其它的字符以普通格式输出 | |
|
|
|
|
|
|
|
|
|
|
|
|
### 运算
|
|
|
|
|
|
|
|
|
|
|
|
| 操作符 | 描述 | 实例 |
|
|
|
|
|
|
| :----- | :----------------------------------------------------------- | :------------------------------ |
|
|
|
|
|
|
| + | 字符串连接 | a + b 输出结果: HelloPython |
|
|
|
|
|
|
| * | 重复输出字符串 | a*2 输出结果:HelloHello |
|
|
|
|
|
|
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 **e** |
|
|
|
|
|
|
| [ : ] | 截取字符串中的一部分,遵循**左闭右开**原则,str[0:2] 是不包含第 3 个字符的。 | a[1:4] 输出结果 **ell** |
|
|
|
|
|
|
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | **'H' in a** 输出结果 True |
|
|
|
|
|
|
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | **'M' not in a** 输出结果 True |
|
|
|
|
|
|
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 **r**(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | `print( r'\n' ) print( R'\n' )` |
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
|
|
|
|
|
```python
|
2022-11-20 19:10:55 +08:00
|
|
|
|
a = "Hello"
|
|
|
|
|
|
b = "Python"
|
|
|
|
|
|
|
|
|
|
|
|
print("a + b 输出结果:", a + b) # a + b 输出结果: HelloPython
|
|
|
|
|
|
print("a * 2 输出结果:", a * 2) # a * 2 输出结果: HelloHello
|
|
|
|
|
|
print("a[1] 输出结果:", a[1]) # a[1] 输出结果: e
|
|
|
|
|
|
print("a[1:4] 输出结果:", a[1:4]) # a[1:4] 输出结果: ell
|
|
|
|
|
|
|
|
|
|
|
|
if( "H" in a) : # H 在变量 a 中
|
|
|
|
|
|
print("H 在变量 a 中")
|
|
|
|
|
|
else :
|
|
|
|
|
|
print("H 不在变量 a 中")
|
|
|
|
|
|
|
|
|
|
|
|
if( "M" not in a) : # M 不在变量 a 中
|
|
|
|
|
|
print("M 不在变量 a 中")
|
|
|
|
|
|
else :
|
|
|
|
|
|
print("M 在变量 a 中")
|
|
|
|
|
|
|
|
|
|
|
|
print (r'\n') # \n
|
|
|
|
|
|
print (R'\n') # \n
|
|
|
|
|
|
```
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
### 格式化
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
```python
|
|
|
|
|
|
print ("我叫 %s 今年 %d 岁!" % ('小明', 10)) # 我叫 小明 今年 10 岁!
|
|
|
|
|
|
```
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
#### 符号
|
|
|
|
|
|
|
|
|
|
|
|
| 符 号 | 描述 |
|
|
|
|
|
|
| :----- | :----------------------------------- |
|
|
|
|
|
|
| %c | 格式化字符及其ASCII码 |
|
|
|
|
|
|
| %s | 格式化字符串 |
|
|
|
|
|
|
| %d | 格式化整数 |
|
|
|
|
|
|
| %u | 格式化无符号整型 |
|
|
|
|
|
|
| %o | 格式化无符号八进制数 |
|
|
|
|
|
|
| %x | 格式化无符号十六进制数 |
|
|
|
|
|
|
| %X | 格式化无符号十六进制数(大写) |
|
|
|
|
|
|
| %f | 格式化浮点数字,可指定小数点后的精度 |
|
|
|
|
|
|
| %e | 用科学计数法格式化浮点数 |
|
|
|
|
|
|
| %E | 作用同%e,用科学计数法格式化浮点数 |
|
|
|
|
|
|
| %g | %f和%e的简写 |
|
|
|
|
|
|
| %G | %f 和 %E 的简写 |
|
|
|
|
|
|
| %p | 用十六进制数格式化变量的地址 |
|
|
|
|
|
|
|
|
|
|
|
|
#### 辅助指令
|
|
|
|
|
|
|
|
|
|
|
|
| 符号 | 功能 |
|
|
|
|
|
|
| :---- | :----------------------------------------------------------- |
|
|
|
|
|
|
| * | 定义宽度或者小数点精度 |
|
|
|
|
|
|
| - | 用做左对齐 |
|
|
|
|
|
|
| + | 在正数前面显示加号( + ) |
|
2022-11-20 21:02:44 +08:00
|
|
|
|
| `<sp>` | 在正数前面显示空格 |
|
2022-11-20 19:10:55 +08:00
|
|
|
|
| # | 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') |
|
|
|
|
|
|
| 0 | 显示的数字前面填充'0'而不是默认的空格 |
|
|
|
|
|
|
| % | '%%'输出一个单一的'%' |
|
|
|
|
|
|
| (var) | 映射变量(字典参数) |
|
|
|
|
|
|
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
|
|
|
|
|
|
|
|
|
|
|
|
### `f`格式化输出
|
|
|
|
|
|
|
|
|
|
|
|
**Python 3.6** 以后,格式化字符串还有更为简洁的书写方式,就是在字符串前加上字母`f`,我们可以使用下面的语法糖来简化上面的代码。其可以通过变量后 冒号+数字 指定输出宽度,例如 {a:10} 将占用 10 个字符宽度。
|
|
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
|
a, b = 5, 10
|
|
|
|
|
|
print(f'{a:10} * {b:10} = {a * b}')
|
2022-01-27 17:58:05 +08:00
|
|
|
|
```
|
|
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
### 常用函数
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
|
str1 = 'hello, world!'
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 通过内置函数len计算字符串的长度
|
2022-02-11 16:28:35 +08:00
|
|
|
|
len(str1) # 13
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 获得字符串首字母大写的拷贝
|
2022-02-11 16:28:35 +08:00
|
|
|
|
str1.capitalize() # Hello, world!
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 获得字符串每个单词首字母大写的拷贝
|
2022-02-11 16:28:35 +08:00
|
|
|
|
str1.title() # Hello, World!
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 获得字符串变大写后的拷贝
|
2022-02-11 16:28:35 +08:00
|
|
|
|
str1.upper() # HELLO, WORLD!
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 从字符串中查找子串所在位置
|
2022-02-11 16:28:35 +08:00
|
|
|
|
str1.find('or') # 8
|
|
|
|
|
|
str1.find('shit') # -1
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 与find类似但找不到子串时会引发异常
|
|
|
|
|
|
# print(str1.index('or'))
|
|
|
|
|
|
# print(str1.index('shit'))
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 检查字符串是否以指定的字符串开头
|
2022-02-11 16:28:35 +08:00
|
|
|
|
str1.startswith('He') # False
|
|
|
|
|
|
str1.startswith('hel') # True
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 检查字符串是否以指定的字符串结尾
|
2022-02-11 16:28:35 +08:00
|
|
|
|
str1.endswith('!') # True
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 将字符串以指定的宽度居中并在两侧填充指定的字符
|
2022-02-11 16:28:35 +08:00
|
|
|
|
str1.center(50, '*')
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 将字符串以指定的宽度靠右放置左侧填充指定的字符
|
2022-02-11 16:28:35 +08:00
|
|
|
|
str1.rjust(50, ' ')
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
str2 = 'abc123456'
|
|
|
|
|
|
# 检查字符串是否由数字构成
|
2022-02-11 16:28:35 +08:00
|
|
|
|
str2.isdigit() # False
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 检查字符串是否以字母构成
|
2022-02-11 16:28:35 +08:00
|
|
|
|
str2.isalpha() # False
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 检查字符串是否以数字和字母构成
|
2022-02-11 16:28:35 +08:00
|
|
|
|
str2.isalnum() # True
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
str3 = ' jackfrued@126.com '
|
|
|
|
|
|
# 获得字符串修剪左右两侧空格之后的拷贝
|
2022-02-11 16:28:35 +08:00
|
|
|
|
str3.strip()
|
2022-01-27 17:58:05 +08:00
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
## 列表(List)
|
|
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
列表(`list`)是一种结构化的、非标量类型,它是值的有序序列,每个值都可以通过索引进行标识,定义列表可以将列表的元素放在`[]`中,多个元素用`,`进行分隔,可以使用`for`循环对列表元素进行遍历,也可以使用`[]`或`[:]`运算符取出列表中的一个或多个元素。
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
### 操作
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
|
|
|
|
|
```python
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 列表定义
|
|
|
|
|
|
list1 = [ 'abcd', 786 , 2.23, 'runoob', 70.2 ]
|
|
|
|
|
|
tinylist = [123, 'runoob']
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
print (list1) # 输出完整列表
|
|
|
|
|
|
print (list1[0]) # 输出列表第一个元素
|
|
|
|
|
|
print (list1[1:3]) # 从第二个开始输出到第三个元素
|
|
|
|
|
|
print (list1[2:]) # 输出从第三个元素开始的所有元素
|
|
|
|
|
|
print (tinylist * 2) # 输出两次列表
|
|
|
|
|
|
print (list1 + tinylist) # 连接列表
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 通过循环用下标遍历列表元素
|
|
|
|
|
|
for index in range(len(list1)):
|
|
|
|
|
|
print(list1[index])
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 通过for 循环遍历列表元素
|
2022-01-27 17:58:05 +08:00
|
|
|
|
for elem in list1:
|
|
|
|
|
|
print(elem)
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 通过 enumerate 函数处理列表之后再遍历可以同时获得元素索引和值
|
2022-01-27 17:58:05 +08:00
|
|
|
|
for index, elem in enumerate(list1):
|
|
|
|
|
|
print(index, elem)
|
2022-11-20 19:10:55 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 添加元素
|
|
|
|
|
|
list1.append(200)
|
|
|
|
|
|
list1.insert(1, 400)
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 合并两个列表
|
|
|
|
|
|
# list1.extend([1000, 2000])
|
|
|
|
|
|
list1 += [1000, 2000]
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 指定位置插入元素
|
|
|
|
|
|
list1.insert(2,700)
|
|
|
|
|
|
|
|
|
|
|
|
# 删除元素
|
|
|
|
|
|
list1.remove(700)
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 指定位置删除元素
|
2022-01-27 17:58:05 +08:00
|
|
|
|
list1.pop(0)
|
|
|
|
|
|
list1.pop(len(list1) - 1)
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 删除列表所有元素
|
2022-01-27 17:58:05 +08:00
|
|
|
|
list1.clear()
|
2022-11-20 19:10:55 +08:00
|
|
|
|
|
|
|
|
|
|
# 返回元素索引
|
|
|
|
|
|
list1.index(700)
|
|
|
|
|
|
|
|
|
|
|
|
# 返回元素出现次数
|
|
|
|
|
|
list1.count(700)
|
|
|
|
|
|
|
|
|
|
|
|
# 翻转列表中的元素
|
|
|
|
|
|
list1.reverse()
|
|
|
|
|
|
|
|
|
|
|
|
# 返回列表的浅拷贝
|
|
|
|
|
|
list1.copy()
|
2022-01-27 17:58:05 +08:00
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
### 切片
|
|
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
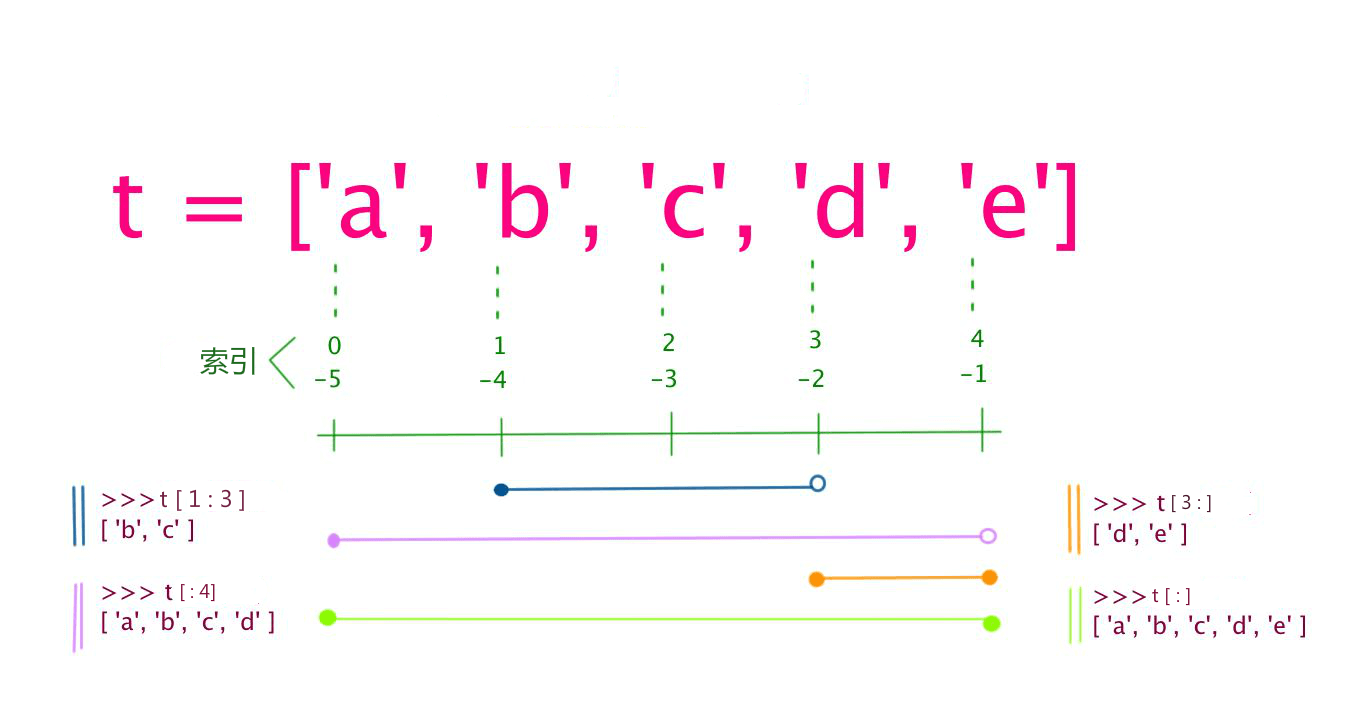
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
```python
|
|
|
|
|
|
fruits = ['grape', 'apple', 'strawberry', 'waxberry']
|
|
|
|
|
|
fruits += ['pitaya', 'pear', 'mango']
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 列表切片
|
|
|
|
|
|
fruits2 = fruits[1:4]
|
|
|
|
|
|
print(fruits2) # apple strawberry waxberry
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 可以通过完整切片操作来复制列表
|
|
|
|
|
|
fruits3 = fruits[:]
|
|
|
|
|
|
fruits4 = fruits[-3:-1]
|
|
|
|
|
|
print(fruits4) # ['pitaya', 'pear']
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 通过反向切片操作来获得倒转后的列表的拷贝
|
2022-01-27 17:58:05 +08:00
|
|
|
|
fruits5 = fruits[::-1]
|
|
|
|
|
|
print(fruits5) # ['mango', 'pear', 'pitaya', 'waxberry', 'strawberry', 'apple', 'grape']
|
|
|
|
|
|
```
|
|
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
## 元组
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
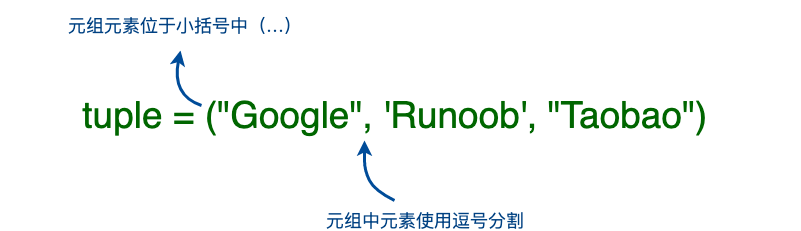
Python 中的元组与列表类似也是一种容器数据类型,元组使用小括号 **( )**,列表使用方括号 **[ ]**;元组可以用一个变量(对象)来存储多个数据,不同之处在于**元组的元素不能修改**。
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
### 操作
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
|
# 定义元组
|
|
|
|
|
|
t = ('骆昊', 38, True, '四川成都')
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 定义空元组
|
|
|
|
|
|
t1 = ()
|
|
|
|
|
|
|
|
|
|
|
|
# 元组中只包含一个元素时,需要在元素后面添加逗号 , ,否则括号会被当作运算符使用。
|
|
|
|
|
|
tup1 = (50) # 不加逗号,类型为整型
|
|
|
|
|
|
tup1 = (50,) # 加上逗号,类型为元组
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 遍历元组中的值
|
|
|
|
|
|
for member in t:
|
|
|
|
|
|
print(member)
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 重新给元组赋值
|
|
|
|
|
|
# t[0] = '王大锤' # TypeError
|
|
|
|
|
|
# 变量t重新引用了新的元组原来的元组将被垃圾回收
|
|
|
|
|
|
t = ('王大锤', 20, True, '云南昆明')
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 将元组转换成列表
|
|
|
|
|
|
person = list(t)
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 将列表转换成元组
|
|
|
|
|
|
fruits_list = ['apple', 'banana', 'orange']
|
|
|
|
|
|
fruits_tuple = tuple(fruits_list)
|
2022-11-20 19:10:55 +08:00
|
|
|
|
|
|
|
|
|
|
# 创建一个新的元组
|
|
|
|
|
|
tup1 = (12, 34.56)
|
|
|
|
|
|
tup2 = ('abc', 'xyz')
|
|
|
|
|
|
tup3 = tup1 + tup2
|
|
|
|
|
|
|
|
|
|
|
|
# 删除元组
|
|
|
|
|
|
tup = ('Google', 'Runoob', 1997, 2000)
|
|
|
|
|
|
del tup
|
2022-01-27 17:58:05 +08:00
|
|
|
|
```
|
|
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
### 切片
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
|
tup = ('Google', 'Runoob', 'Taobao', 'Wiki', 'Weibo','Weixin')
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
| Python 表达式 | 结果 | 描述 |
|
|
|
|
|
|
| :------------ | :---------------------------------------------- | :----------------------------------------------- |
|
|
|
|
|
|
| tup[1] | 'Runoob' | 读取第二个元素 |
|
|
|
|
|
|
| tup[-2] | 'Weibo' | 反向读取,读取倒数第二个元素 |
|
|
|
|
|
|
| tup[1:] | ('Runoob', 'Taobao', 'Wiki', 'Weibo', 'Weixin') | 截取元素,从第二个开始后的所有元素。 |
|
|
|
|
|
|
| tup[1:4] | ('Runoob', 'Taobao', 'Wiki') | 截取元素,从第二个开始到第四个元素(索引为 3)。 |
|
|
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
## 集合
|
|
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
集合(set)是由不重复元素组成的无序容器。基本用法包括成员检测、消除重复元素。集合对象支持合集、交集、差集、对称差分等数学运算。
|
2022-11-20 16:38:36 +08:00
|
|
|
|
|
|
|
|
|
|
创建集合用花括号或 set() 函数。注意,创建空集合只能用 set(),不能用 {},{} 创建的是空字典
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
### 操作
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
|
|
|
|
|
```python
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 演示去重功能
|
|
|
|
|
|
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
|
|
|
|
|
|
print(basket) # 输出 {'orange', 'banana', 'pear', 'apple'}
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 判断元素是否在集合内
|
|
|
|
|
|
'orange' in basket # True
|
|
|
|
|
|
'crabgrass' in basket # Flase
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
2022-02-11 16:28:35 +08:00
|
|
|
|
# 添加
|
2022-11-20 19:10:55 +08:00
|
|
|
|
basket.add(400)
|
|
|
|
|
|
basket.add(500)
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
|
|
|
|
|
# 删除
|
2022-11-20 19:10:55 +08:00
|
|
|
|
basket.remove('apple')
|
|
|
|
|
|
basket.discard('orange')
|
|
|
|
|
|
|
|
|
|
|
|
# 元素个数
|
|
|
|
|
|
len(basket)
|
|
|
|
|
|
|
|
|
|
|
|
# 清空
|
|
|
|
|
|
basket.clear()
|
2022-01-27 17:58:05 +08:00
|
|
|
|
```
|
|
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
### 运算
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
|
|
|
|
|
```python
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 交集
|
2022-01-27 17:58:05 +08:00
|
|
|
|
print(set1 & set2)
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 并集
|
2022-01-27 17:58:05 +08:00
|
|
|
|
print(set1 | set2)
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 差集
|
2022-01-27 17:58:05 +08:00
|
|
|
|
print(set1 - set2)
|
2022-11-20 19:10:55 +08:00
|
|
|
|
# 对称差运算
|
2022-01-27 17:58:05 +08:00
|
|
|
|
print(set1 ^ set2)
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-01-27 17:58:05 +08:00
|
|
|
|
# 判断子集和超集
|
|
|
|
|
|
print(set2 <= set1)
|
|
|
|
|
|
print(set3 <= set1)
|
|
|
|
|
|
print(set1 >= set2)
|
|
|
|
|
|
print(set1 >= set3)
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
## 字典
|
|
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
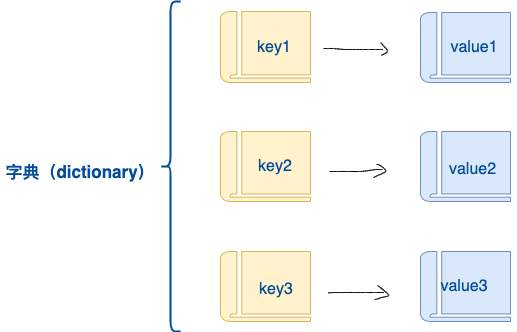
字典是另一种可变容器模型,且**可存储任意类型对象**。字典与列表、集合不同的是,字典的每个元素都是由一个键和一个值组成的**键值对**,键和值通过冒号分开。键必须是唯一的,但值则不必。
|
2022-01-27 17:58:05 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
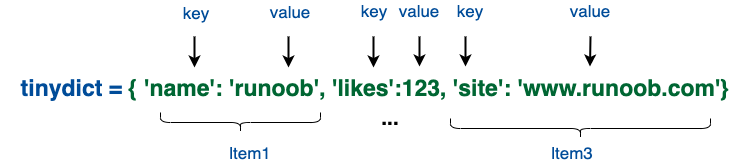
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
字典实例:
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
```python
|
|
|
|
|
|
tinydict = {'name': 'runoob', 'likes': 123, 'url': 'www.runoob.com'}
|
|
|
|
|
|
```
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
### 操作
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
```python
|
|
|
|
|
|
# 使用大括号 {} 来创建空字典
|
|
|
|
|
|
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
|
|
|
|
|
|
# 使用内建函数 dict() 创建字典
|
|
|
|
|
|
emptyDict = dict()
|
|
|
|
|
|
|
|
|
|
|
|
# 打印字典
|
|
|
|
|
|
print(tinydict)
|
|
|
|
|
|
|
|
|
|
|
|
# 查看字典的数量
|
|
|
|
|
|
print("Length:", len(tinydict))
|
|
|
|
|
|
|
|
|
|
|
|
# 查看类型
|
|
|
|
|
|
print(type(tinydict))
|
|
|
|
|
|
|
|
|
|
|
|
# 访问字典里的值
|
|
|
|
|
|
print ("tinydict['Name']: ", tinydict['Name'])
|
|
|
|
|
|
|
|
|
|
|
|
# 修改字典
|
|
|
|
|
|
tinydict['Age'] = 8 # 更新 Age
|
|
|
|
|
|
tinydict['School'] = "菜鸟教程" # 添加信息
|
|
|
|
|
|
|
|
|
|
|
|
# 删除字典元素
|
|
|
|
|
|
del tinydict['Name'] # 删除键 'Name'
|
|
|
|
|
|
tinydict.clear() # 清空字典
|
|
|
|
|
|
del tinydict # 删除字典
|
2022-01-27 17:58:05 +08:00
|
|
|
|
```
|
|
|
|
|
|
|
2022-11-20 19:10:55 +08:00
|
|
|
|
### 循环
|
2022-02-11 16:28:35 +08:00
|
|
|
|
|
|
|
|
|
|
在字典中循环时,用 `items()` 方法可同时取出键和对应的值:
|
|
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
|
knights = {'gallahad': 'the pure', 'robin': 'the brave'}
|
|
|
|
|
|
for k, v in knights.items():
|
|
|
|
|
|
print(k, v)
|
|
|
|
|
|
|
|
|
|
|
|
# gallahad the pure
|
|
|
|
|
|
# robin the brave
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在序列中循环时,用 `enumerate()` 函数可以同时取出位置索引和对应的值:
|
|
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
|
for i, v in enumerate(['tic', 'tac', 'toe']):
|
|
|
|
|
|
print(i, v)
|
|
|
|
|
|
|
|
|
|
|
|
# 0 tic
|
|
|
|
|
|
# 1 tac
|
|
|
|
|
|
# 2 toe
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
同时循环两个或多个序列时,用 `zip()` 函数可以将其内的元素一一匹配:
|
|
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
|
questions = ['name', 'quest', 'favorite color']
|
|
|
|
|
|
answers = ['lancelot', 'the holy grail', 'blue']
|
|
|
|
|
|
for q, a in zip(questions, answers):
|
|
|
|
|
|
print(f'What is your {q}? It is {a}.')
|
|
|
|
|
|
|
|
|
|
|
|
# What is your name? It is lancelot.
|
|
|
|
|
|
# What is your quest? It is the holy grail.
|
|
|
|
|
|
# What is your favorite color? It is blue.
|
|
|
|
|
|
```
|
|
|
|
|
|
|